 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Aware Key-Value Compression for Efficient Autoregressive Image Generation
May 20, 2026Autoregressive (AR) visual generation has achieved remarkable performance but suffers from high memory usage and low throughput, as it requires caching previously generated visual tokens. Recent research has shown that retaining only a few lines of cache tokens can maintain high-quality images while significantly reducing memory usage and improving throughput. However, these methods allocate a fixed budget to each attention head, overlooking the heterogeneity among attention heads, leading to suboptimal memory allocation. In this paper, we observe that attention heads across different layers exhibit diverse attention patterns, where some heads focus on local neighborhoods while others capture broader contextual dependencies. Based on this insight, we propose a novel head-aware key-value (KV) cache compression framework for autoregressive image generation, called HeadKV, which assigns smaller budgets to locality-biased heads and larger budgets to heads with broader attention. A key challenge lies in identifying the type of each attention head to guide cache compression. We further observe that, within the same layer, each head exhibits consistent attention patterns across token positions, \emph{i.e.}, a head's behavior for early tokens remains consistent with that for later tokens. This insight suggests that head types can be identified during the early stage and reused for KV compression throughout generation. Its advantage is that it requires no additional training or dataset-level statistics and generalizes seamlessly across different inputs. Moreover, we design a Stratified Token Eviction strategy to effectively preserve long-range information. Extensive experiments demonstrate its effectiveness across multiple autoregressive image generation models.
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Apr 22, 2026Multimodal Large Language Models (MLLMs) have shown promising capabilities in generating Scalable Vector Graphics (SVG) via direct code synthesis. However, existing paradigms typically adopt an open-loop "blind drawing" approach, where models generate symbolic code sequences without perceiving intermediate visual outcomes. This methodology severely underutilizes the powerful visual priors embedded in MLLMs vision encoders, treating SVG generation as a disjointed textual sequence modeling task rather than an integrated visuo-spatial one. Consequently, models struggle to reason about partial canvas states and implicit occlusion relationships, which are visually explicit but textually ambiguous. To bridge this gap, we propose Render-in-the-Loop, a novel generation paradigm that reformulates SVG synthesis as a step-wise, visual-context-aware process. By rendering intermediate code states into a cumulative canvas, the model explicitly observes the evolving visual context at each step, leveraging on-the-fly feedback to guide subsequent generation. However, we demonstrate that applying this visual loop naively to off-the-shelf models is suboptimal due to their inability to leverage incremental visual-code mappings. To address this, we first utilize fine-grained path decomposition to construct dense multi-step visual trajectories, and then introduce a Visual Self-Feedback (VSF) training strategy to condition the next primitive generation on intermediate visual states. Furthermore, a Render-and-Verify (RaV) inference mechanism is proposed to effectively filter degenerate and redundant primitives. Our framework, instantiated on a multimodal foundation model, outperforms strong open-weight baselines on the standard MMSVGBench. This result highlights the remarkable data efficiency and generalization capability of our Render-in-the-Loop paradigm for both Text-to-SVG and Image-to-SVG tasks.
AmodalSVG: Amodal Image Vectorization via Semantic Layer Peeling
Apr 13, 2026We introduce AmodalSVG, a new framework for amodal image vectorization that produces semantically organized and geometrically complete SVG representations from natural images. Existing vectorization methods operate under a modal paradigm: tracing only visible pixels and disregarding occlusion. Consequently, the resulting SVGs are semantically entangled and geometrically incomplete, limiting SVG's structural editability. In contrast, AmodalSVG reconstructs full object geometries, including occluded regions, into independent, editable vector layers. To achieve this, AmodalSVG reformulates image vectorization as a two-stage framework, performing semantic decoupling and completion in the raster domain to produce amodally complete semantic layers, which are then independently vectorized. In the first stage, we introduce Semantic Layer Peeling (SLP), a VLM-guided strategy that progressively decomposes an image into semantically coherent layers. By hybrid inpainting, SLP recovers complete object appearances under occlusions, enabling explicit semantic decoupling. To vectorize these layers efficiently, we propose Adaptive Layered Vectorization (ALV), which dynamically modulates the primitive budget via an error-budget-driven adjustment mechanism. Extensive experiments demonstrate that AmodalSVG significantly outperforms prior methods in visual fidelity. Moreover, the resulting amodal layers enable object-level editing directly in the vector domain, capabilities not supported by existing vectorization approaches. Code will be released upon acceptance.
TwiFF (Think With Future Frames): A Large-Scale Dataset for Dynamic Visual Reasoning
Feb 11, 2026Visual Chain-of-Thought (VCoT) has emerged as a promising paradigm for enhancing multimodal reasoning by integrating visual perception into intermediate reasoning steps. However, existing VCoT approaches are largely confined to static scenarios and struggle to capture the temporal dynamics essential for tasks such as instruction, prediction, and camera motion. To bridge this gap, we propose TwiFF-2.7M, the first large-scale, temporally grounded VCoT dataset derived from $2.7$ million video clips, explicitly designed for dynamic visual question and answer. Accompanying this, we introduce TwiFF-Bench, a high-quality evaluation benchmark of $1,078$ samples that assesses both the plausibility of reasoning trajectories and the correctness of final answers in open-ended dynamic settings. Building on these foundations, we propose the TwiFF model, a unified modal that synergistically leverages pre-trained video generation and image comprehension capabilities to produce temporally coherent visual reasoning cues-iteratively generating future action frames and textual reasoning. Extensive experiments demonstrate that TwiFF significantly outperforms existing VCoT methods and Textual Chain-of-Thought baselines on dynamic reasoning tasks, which fully validates the effectiveness for visual question answering in dynamic scenarios. Our code and data is available at https://github.com/LiuJunhua02/TwiFF.
Improved Masked Image Generation with Knowledge-Augmented Token Representations
Nov 15, 2025Masked image generation (MIG) has demonstrated remarkable efficiency and high-fidelity images by enabling parallel token prediction. Existing methods typically rely solely on the model itself to learn semantic dependencies among visual token sequences. However, directly learning such semantic dependencies from data is challenging because the individual tokens lack clear semantic meanings, and these sequences are usually long. To address this limitation, we propose a novel Knowledge-Augmented Masked Image Generation framework, named KA-MIG, which introduces explicit knowledge of token-level semantic dependencies (\emph{i.e.}, extracted from the training data) as priors to learn richer representations for improving performance. In particular, we explore and identify three types of advantageous token knowledge graphs, including two positive and one negative graphs (\emph{i.e.}, the co-occurrence graph, the semantic similarity graph, and the position-token incompatibility graph). Based on three prior knowledge graphs, we design a graph-aware encoder to learn token and position-aware representations. After that, a lightweight fusion mechanism is introduced to integrate these enriched representations into the existing MIG methods. Resorting to such prior knowledge, our method effectively enhances the model's ability to capture semantic dependencies, leading to improved generation quality. Experimental results demonstrate that our method improves upon existing MIG for class-conditional image generation on ImageNet.
Towards Improved Text-Aligned Codebook Learning: Multi-Hierarchical Codebook-Text Alignment with Long Text
Mar 03, 2025Image quantization is a crucial technique in image generation, aimed at learning a codebook that encodes an image into a discrete token sequence. Recent advancements have seen researchers exploring learning multi-modal codebook (i.e., text-aligned codebook) by utilizing image caption semantics, aiming to enhance codebook performance in cross-modal tasks. However, existing image-text paired datasets exhibit a notable flaw in that the text descriptions tend to be overly concise, failing to adequately describe the images and provide sufficient semantic knowledge, resulting in limited alignment of text and codebook at a fine-grained level. In this paper, we propose a novel Text-Augmented Codebook Learning framework, named TA-VQ, which generates longer text for each image using the visual-language model for improved text-aligned codebook learning. However, the long text presents two key challenges: how to encode text and how to align codebook and text. To tackle two challenges, we propose to split the long text into multiple granularities for encoding, i.e., word, phrase, and sentence, so that the long text can be fully encoded without losing any key semantic knowledge. Following this, a hierarchical encoder and novel sampling-based alignment strategy are designed to achieve fine-grained codebook-text alignment. Additionally, our method can be seamlessly integrated into existing VQ models. Extensive experiments in reconstruction and various downstream tasks demonstrate its effectiveness compared to previous state-of-the-art approaches.
Empowering LLMs to Understand and Generate Complex Vector Graphics
Dec 15, 2024The unprecedented advancements in Large Language Models (LLMs) have profoundly impacted natural language processing but have yet to fully embrace the realm of scalable vector graphics (SVG) generation. While LLMs encode partial knowledge of SVG data from web pages during training, recent findings suggest that semantically ambiguous and tokenized representations within LLMs may result in hallucinations in vector primitive predictions. Additionally, LLM training typically lacks modeling and understanding of the rendering sequence of vector paths, which can lead to occlusion between output vector primitives. In this paper, we present LLM4SVG, an initial yet substantial step toward bridging this gap by enabling LLMs to better understand and generate vector graphics. LLM4SVG facilitates a deeper understanding of SVG components through learnable semantic tokens, which precisely encode these tokens and their corresponding properties to generate semantically aligned SVG outputs. Using a series of learnable semantic tokens, a structured dataset for instruction following is developed to support comprehension and generation across two primary tasks. Our method introduces a modular architecture to existing large language models, integrating semantic tags, vector instruction encoders, fine-tuned commands, and powerful LLMs to tightly combine geometric, appearance, and language information. To overcome the scarcity of SVG-text instruction data, we developed an automated data generation pipeline that collected a massive dataset of more than 250k SVG data and 580k SVG-text instructions, which facilitated the adoption of the two-stage training strategy popular in LLM development. By exploring various training strategies, we developed LLM4SVG, which significantly moves beyond optimized rendering-based approaches and language-model-based baselines to achieve remarkable results in human evaluation tasks.
AsyncDSB: Schedule-Asynchronous Diffusion Schrödinger Bridge for Image Inpainting
Dec 11, 2024

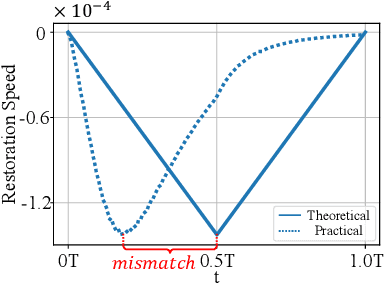
Image inpainting is an important image generation task, which aims to restore corrupted image from partial visible area. Recently, diffusion Schr\"odinger bridge methods effectively tackle this task by modeling the translation between corrupted and target images as a diffusion Schr\"odinger bridge process along a noising schedule path. Although these methods have shown superior performance, in this paper, we find that 1) existing methods suffer from a schedule-restoration mismatching issue, i.e., the theoretical schedule and practical restoration processes usually exist a large discrepancy, which theoretically results in the schedule not fully leveraged for restoring images; and 2) the key reason causing such issue is that the restoration process of all pixels are actually asynchronous but existing methods set a synchronous noise schedule to them, i.e., all pixels shares the same noise schedule. To this end, we propose a schedule-Asynchronous Diffusion Schr\"odinger Bridge (AsyncDSB) for image inpainting. Our insight is preferentially scheduling pixels with high frequency (i.e., large gradients) and then low frequency (i.e., small gradients). Based on this insight, given a corrupted image, we first train a network to predict its gradient map in corrupted area. Then, we regard the predicted image gradient as prior and design a simple yet effective pixel-asynchronous noise schedule strategy to enhance the diffusion Schr\"odinger bridge. Thanks to the asynchronous schedule at pixels, the temporal interdependence of restoration process between pixels can be fully characterized for high-quality image inpainting. Experiments on real-world datasets show that our AsyncDSB achieves superior performance, especially on FID with around 3% - 14% improvement over state-of-the-art baseline methods.
LG-VQ: Language-Guided Codebook Learning
May 23, 2024



Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner. Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps. In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment. In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.