 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDis: A Causal Disentanglement Framework for Federated Traffic Prediction
Jan 30, 2026Federated learning offers a promising paradigm for privacy-preserving traffic prediction, yet its performance is often challenged by the non-identically and independently distributed (non-IID) nature of decentralized traffic data. Existing federated methods frequently struggle with this data heterogeneity, typically entangling globally shared patterns with client-specific local dynamics within a single representation. In this work, we postulate that this heterogeneity stems from the entanglement of two distinct generative sources: client-specific localized dynamics and cross-client global spatial-temporal patterns. Motivated by this perspective, we introduce FedDis, a novel framework that, to the best of our knowledge, is the first to leverage causal disentanglement for federated spatial-temporal prediction. Architecturally, FedDis comprises a dual-branch design wherein a Personalized Bank learns to capture client-specific factors, while a Global Pattern Bank distills common knowledge. This separation enables robust cross-client knowledge transfer while preserving high adaptability to unique local environments. Crucially, a mutual information minimization objective is employed to enforce informational orthogonality between the two branches, thereby ensuring effective disentanglement. Comprehensive experiments conducted on four real-world benchmark datasets demonstrate that FedDis consistently achieves state-of-the-art performance, promising efficiency, and superior expandability.
Breaking the Passive Learning Trap: An Active Perception Strategy for Human Motion Prediction
Nov 18, 2025Forecasting 3D human motion is an important embodiment of fine-grained understanding and cognition of human behavior by artificial agents. Current approaches excessively rely on implicit network modeling of spatiotemporal relationships and motion characteristics, falling into the passive learning trap that results in redundant and monotonous 3D coordinate information acquisition while lacking actively guided explicit learning mechanisms. To overcome these issues, we propose an Active Perceptual Strategy (APS) for human motion prediction, leveraging quotient space representations to explicitly encode motion properties while introducing auxiliary learning objectives to strengthen spatio-temporal modeling. Specifically, we first design a data perception module that projects poses into the quotient space, decoupling motion geometry from coordinate redundancy. By jointly encoding tangent vectors and Grassmann projections, this module simultaneously achieves geometric dimension reduction, semantic decoupling, and dynamic constraint enforcement for effective motion pose characterization. Furthermore, we introduce a network perception module that actively learns spatio-temporal dependencies through restorative learning. This module deliberately masks specific joints or injects noise to construct auxiliary supervision signals. A dedicated auxiliary learning network is designed to actively adapt and learn from perturbed information. Notably, APS is model agnostic and can be integrated with different prediction models to enhance active perceptual. The experimental results demonstrate that our method achieves the new state-of-the-art, outperforming existing methods by large margins: 16.3% on H3.6M, 13.9% on CMU Mocap, and 10.1% on 3DPW.
Empowering LLMs to Understand and Generate Complex Vector Graphics
Dec 15, 2024The unprecedented advancements in Large Language Models (LLMs) have profoundly impacted natural language processing but have yet to fully embrace the realm of scalable vector graphics (SVG) generation. While LLMs encode partial knowledge of SVG data from web pages during training, recent findings suggest that semantically ambiguous and tokenized representations within LLMs may result in hallucinations in vector primitive predictions. Additionally, LLM training typically lacks modeling and understanding of the rendering sequence of vector paths, which can lead to occlusion between output vector primitives. In this paper, we present LLM4SVG, an initial yet substantial step toward bridging this gap by enabling LLMs to better understand and generate vector graphics. LLM4SVG facilitates a deeper understanding of SVG components through learnable semantic tokens, which precisely encode these tokens and their corresponding properties to generate semantically aligned SVG outputs. Using a series of learnable semantic tokens, a structured dataset for instruction following is developed to support comprehension and generation across two primary tasks. Our method introduces a modular architecture to existing large language models, integrating semantic tags, vector instruction encoders, fine-tuned commands, and powerful LLMs to tightly combine geometric, appearance, and language information. To overcome the scarcity of SVG-text instruction data, we developed an automated data generation pipeline that collected a massive dataset of more than 250k SVG data and 580k SVG-text instructions, which facilitated the adoption of the two-stage training strategy popular in LLM development. By exploring various training strategies, we developed LLM4SVG, which significantly moves beyond optimized rendering-based approaches and language-model-based baselines to achieve remarkable results in human evaluation tasks.
SVGFusion: Scalable Text-to-SVG Generation via Vector Space Diffusion
Dec 11, 2024The generation of Scalable Vector Graphics (SVG) assets from textual data remains a significant challenge, largely due to the scarcity of high-quality vector datasets and the limitations in scalable vector representations required for modeling intricate graphic distributions. This work introduces SVGFusion, a Text-to-SVG model capable of scaling to real-world SVG data without reliance on a text-based discrete language model or prolonged SDS optimization. The essence of SVGFusion is to learn a continuous latent space for vector graphics with a popular Text-to-Image framework. Specifically, SVGFusion consists of two modules: a Vector-Pixel Fusion Variational Autoencoder (VP-VAE) and a Vector Space Diffusion Transformer (VS-DiT). VP-VAE takes both the SVGs and corresponding rasterizations as inputs and learns a continuous latent space, whereas VS-DiT learns to generate a latent code within this space based on the text prompt. Based on VP-VAE, a novel rendering sequence modeling strategy is proposed to enable the latent space to embed the knowledge of construction logics in SVGs. This empowers the model to achieve human-like design capabilities in vector graphics, while systematically preventing occlusion in complex graphic compositions. Moreover, our SVGFusion's ability can be continuously improved by leveraging the scalability of the VS-DiT by adding more VS-DiT blocks. A large-scale SVG dataset is collected to evaluate the effectiveness of our proposed method. Extensive experimentation has confirmed the superiority of our SVGFusion over existing SVG generation methods, achieving enhanced quality and generalizability, thereby establishing a novel framework for SVG content creation. Code, model, and data will be released at: \href{https://ximinng.github.io/SVGFusionProject/}{https://ximinng.github.io/SVGFusionProject/}
Forming Auxiliary High-confident Instance-level Loss to Promote Learning from Label Proportions
Nov 15, 2024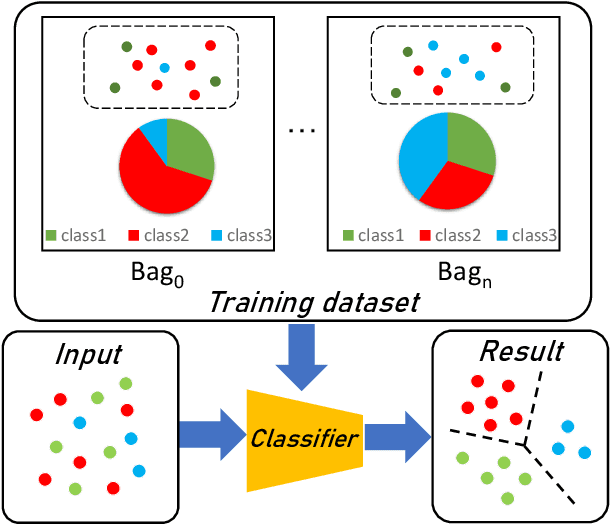
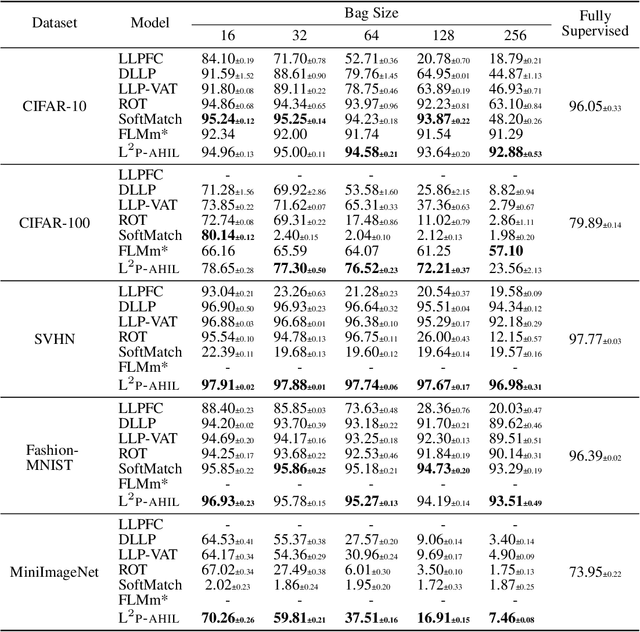

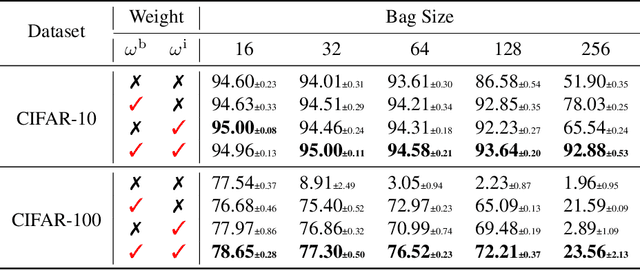
Learning from label proportions (LLP), i.e., a challenging weakly-supervised learning task, aims to train a classifier by using bags of instances and the proportions of classes within bags, rather than annotated labels for each instance. Beyond the traditional bag-level loss, the mainstream methodology of LLP is to incorporate an auxiliary instance-level loss with pseudo-labels formed by predictions. Unfortunately, we empirically observed that the pseudo-labels are are often inaccurate due to over-smoothing, especially for the scenarios with large bag sizes, hurting the classifier induction. To alleviate this problem, we suggest a novel LLP method, namely Learning from Label Proportions with Auxiliary High-confident Instance-level Loss (L^2P-AHIL). Specifically, we propose a dual entropy-based weight (DEW) method to adaptively measure the confidences of pseudo-labels. It simultaneously emphasizes accurate predictions at the bag level and avoids overly smoothed predictions. We then form high-confident instance-level loss with DEW, and jointly optimize it with the bag-level loss in a self-training manner. The experimental results on benchmark datasets show that L^2P-AHIL can surpass the existing baseline methods, and the performance gain can be more significant as the bag size increases.
Diversity-Driven Synthesis: Enhancing Dataset Distillation through Directed Weight Adjustment
Sep 26, 2024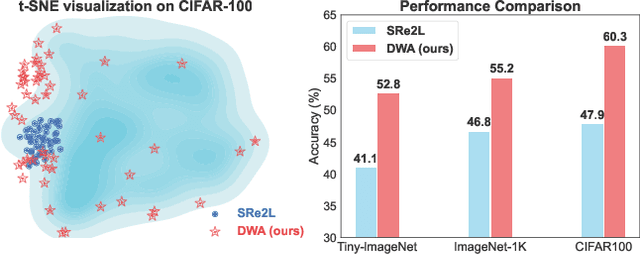



The sharp increase in data-related expenses has motivated research into condensing datasets while retaining the most informative features. Dataset distillation has thus recently come to the fore. This paradigm generates synthetic dataset that are representative enough to replace the original dataset in training a neural network. To avoid redundancy in these synthetic datasets, it is crucial that each element contains unique features and remains diverse from others during the synthesis stage. In this paper, we provide a thorough theoretical and empirical analysis of diversity within synthesized datasets. We argue that enhancing diversity can improve the parallelizable yet isolated synthesizing approach. Specifically, we introduce a novel method that employs dynamic and directed weight adjustment techniques to modulate the synthesis process, thereby maximizing the representativeness and diversity of each synthetic instance. Our method ensures that each batch of synthetic data mirrors the characteristics of a large, varying subset of the original dataset. Extensive experiments across multiple datasets, including CIFAR, Tiny-ImageNet, and ImageNet-1K, demonstrate the superior performance of our method, highlighting its effectiveness in producing diverse and representative synthetic datasets with minimal computational expense.
VectorPainter: A Novel Approach to Stylized Vector Graphics Synthesis with Vectorized Strokes
May 05, 2024



We propose a novel method, VectorPainter, for the task of stylized vector graphics synthesis. Given a text prompt and a reference style image, VectorPainter generates a vector graphic that aligns in content with the text prompt and remains faithful in style to the reference image. We recognize that the key to this task lies in fully leveraging the intrinsic properties of vector graphics. Innovatively, we conceptualize the stylization process as the rearrangement of vectorized strokes extracted from the reference image. VectorPainter employs an optimization-based pipeline. It begins by extracting vectorized strokes from the reference image, which are then used to initialize the synthesis process. To ensure fidelity to the reference style, a novel style preservation loss is introduced. Extensive experiments have been conducted to demonstrate that our method is capable of aligning with the text description while remaining faithful to the reference image.