 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Struggle to Measure What Distinguishes Students of Different Proficiency Levels: A Study of Item Discrimination in Reading Comprehension Assessment
Jun 17, 2026Item discrimination is a fundamental psychometric property of educational assessment, which measures whether an item meaningfully distinguishes students with higher proficiency from students with lower proficiency. While various existing works have explored whether large language models (LLMs) can estimate item difficulty, it remains unclear whether they can capture item discrimination. In this work, we evaluate 42 proprietary and open-weight LLMs in zero-shot settings using two complementary approaches: direct discrimination prediction, where models explicitly estimate an item's discrimination value from its content, and response-based Classical Test Theory (CTT) calibration, where LLM answers are treated as synthetic student responses to compute discrimination scores. Our results show that direct prediction yields weak alignment with human-calibrated discrimination: the best-performing model reaches only a Spearman correlation of 0.152. Response-based CTT calibration provides a stronger but still limited signal, with the all-persona synthetic respondent pool reaching a Spearman correlation of 0.241. These findings highlight item discrimination as an open challenge for LLM-based psychometric evaluation: current LLMs contain non-random discrimination-relevant signal, but they do not yet reliably capture how assessment items distinguish human students.
RW-TTT: Batched Serving for Request-Owned Test-Time Training State
May 27, 2026Test-time training (TTT) adapts an LLM during generation by reading and updating request-owned state, such as fast weights, low-rank deltas, or streaming learner state. This breaks batched LLM serving, which assumes shared static weights: serial execution is correct but slow, while naive batching can corrupt request state. We formulate this problem as read-write TTT serving and present RW-TTT , which tags each decode step with its owner, version, and READ/WRITE effect, batches only compatible phases, and commits updates only to the owner. On one GPU with eight fast-weight InPlace-TTT streams, RW-TTT reaches 274.61 aggregate tok/s, 9.31x over sequential serving and 3.44x over per-stream replicas under the same memory budget. It preserves behavior on RULER, a long-context benchmark, and passes owner/version checks.
ROSE: An Intent-Centered Evaluation Metric for NL2SQL
Apr 14, 2026Execution Accuracy (EX), the widely used metric for evaluating the effectiveness of Natural Language to SQL (NL2SQL) solutions, is becoming increasingly unreliable. It is sensitive to syntactic variation, ignores that questions may admit multiple interpretations, and is easily misled by erroneous ground-truth SQL. To address this, we introduce ROSE, an intent-centered metric that focuses on whether the predicted SQL answers the question, rather than consistency with the ground-truth SQL under the reference-dependent paradigm. ROSE employs an adversarial Prover-Refuter cascade: SQL Prover assesses the semantic correctness of a predicted SQL against the user's intent independently, while Adversarial Refuter uses the ground-truth SQL as evidence to challenge and refine this judgment. On our expert-aligned validation set ROSE-VEC, ROSE achieves the best agreement with human experts, outperforming the next-best metric by nearly 24% in Cohen's Kappa. We also conduct a largescale re-evaluation of 19 NL2SQL methods, revealing four valuable insights. We release ROSE and ROSE-VEC to facilitate more reliable NL2SQL research.
Artificial intelligence-driven improvement of hospital logistics management resilience: a practical exploration based on H Hospital
Mar 14, 2026Hospital logistics management faces growing pressure from internal operations and external emergencies, with artificial intelligence (AI) holding untapped potential to boost its resilience. This study explores AI's role in enhancing logistics resilience via a mixed-methods case study of H Hospital, combining 12 key informant interviews and a full survey of 151 logistics staff, with the PDCA cycle as the analytical framework. Thematic and quantitative analyses (hierarchical regression, structural equation modeling) were adopted for data analysis. Results showed 94.7% staff perceived AI application, with the strongest improvements in equipment maintenance (41.1%) and resource allocation (33.1%), but limited effects in emergency response (18.54%) and risk management (15.23%). AI integration positively correlated with logistics resilience (\b{eta}=0.642, p<0.001), with management system adaptability as a positive moderator (\b{eta}=0.208, p<0.01). The PDCA cycle fully mediated the AI-resilience relationship. We conclude AI effectively enhances logistics resilience, dependent on adaptive management systems and structured continuous improvement mechanisms. Targeted strategies are proposed to form an AI-driven closed-loop resilience mechanism, offering empirical guidance for AI-hospital logistics integration and resilient health system construction.
SunnyParking: Multi-Shot Trajectory Generation and Motion State Awareness for Human-like Parking
Feb 25, 2026Autonomous parking fundamentally differs from on-road driving due to its frequent direction changes and complex maneuvering requirements. However, existing End-to-End (E2E) planning methods often simplify the parking task into a geometric path regression problem, neglecting explicit modeling of the vehicle's kinematic state. This "dimensionality deficiency" easily leads to physically infeasible trajectories and deviates from real human driving behavior, particularly at critical gear-shift points in multi-shot parking scenarios. In this paper, we propose SunnyParking, a novel dual-branch E2E architecture that achieves motion state awareness by jointly predicting spatial trajectories and discrete motion state sequences (e.g., forward/reverse). Additionally, we introduce a Fourier feature-based representation of target parking slots to overcome the resolution limitations of traditional bird's-eye view (BEV) approaches, enabling high-precision target interactions. Experimental results demonstrate that our framework generates more robust and human-like trajectories in complex multi-shot parking scenarios, while significantly improving gear-shift point localization accuracy compared to state-of-the-art methods. We open-source a new parking dataset of the CARLA simulator, specifically designed to evaluate full prediction capabilities under complex maneuvers.
Latent-Space Contrastive Reinforcement Learning for Stable and Efficient LLM Reasoning
Jan 24, 2026While Large Language Models (LLMs) demonstrate exceptional performance in surface-level text generation, their nature in handling complex multi-step reasoning tasks often remains one of ``statistical fitting'' rather than systematic logical deduction. Traditional Reinforcement Learning (RL) attempts to mitigate this by introducing a ``think-before-speak'' paradigm. However, applying RL directly in high-dimensional, discrete token spaces faces three inherent challenges: sample-inefficient rollouts, high gradient estimation variance, and the risk of catastrophic forgetting. To fundamentally address these structural bottlenecks, we propose \textbf{DeepLatent Reasoning (DLR)}, a latent-space bidirectional contrastive reinforcement learning framework. This framework shifts the trial-and-error cost from expensive token-level full sequence generation to the continuous latent manifold. Specifically, we introduce a lightweight assistant model to efficiently sample $K$ reasoning chain encodings within the latent space. These encodings are filtered via a dual reward mechanism based on correctness and formatting; only high-value latent trajectories are fed into a \textbf{frozen main model} for single-pass decoding. To maximize reasoning diversity while maintaining coherence, we design a contrastive learning objective to enable directed exploration within the latent space. Since the main model parameters remain frozen during optimization, this method mathematically eliminates catastrophic forgetting. Experiments demonstrate that under comparable GPU computational budgets, DLR achieves more stable training convergence, supports longer-horizon reasoning chains, and facilitates the sustainable accumulation of reasoning capabilities, providing a viable path toward reliable and scalable reinforcement learning for LLMs.
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
Dec 21, 2025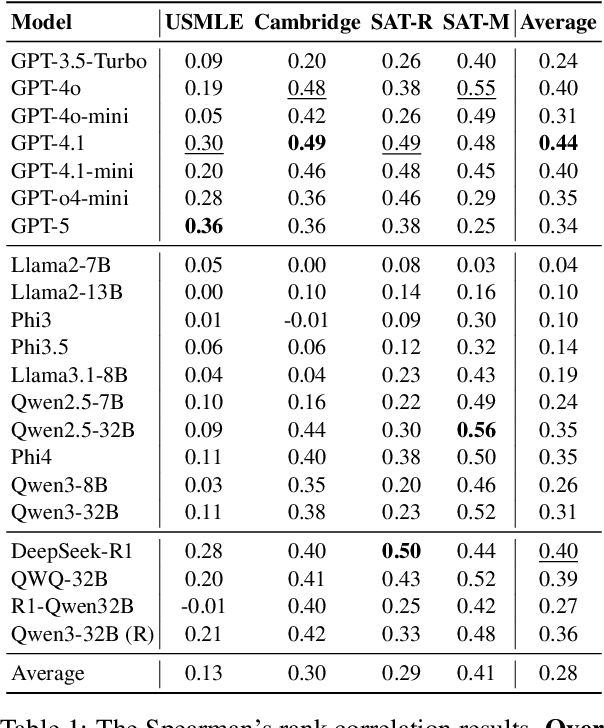
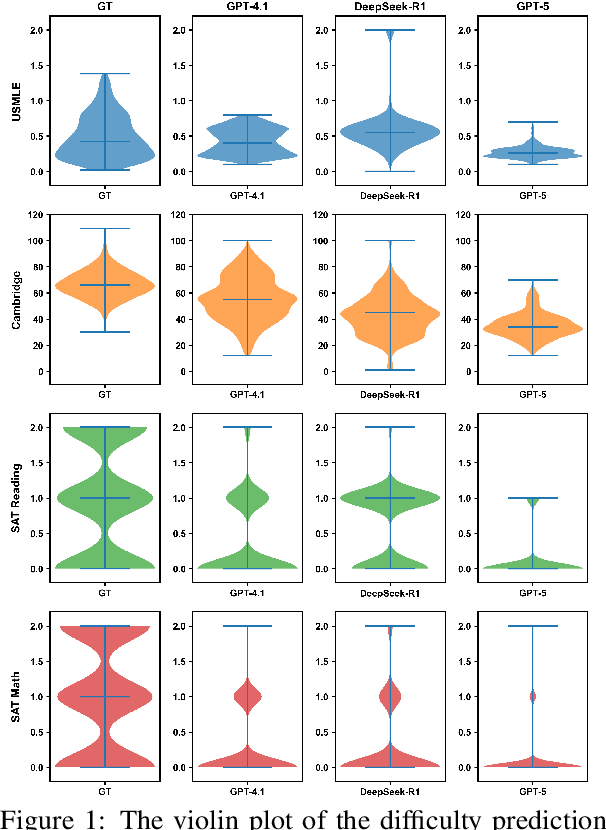
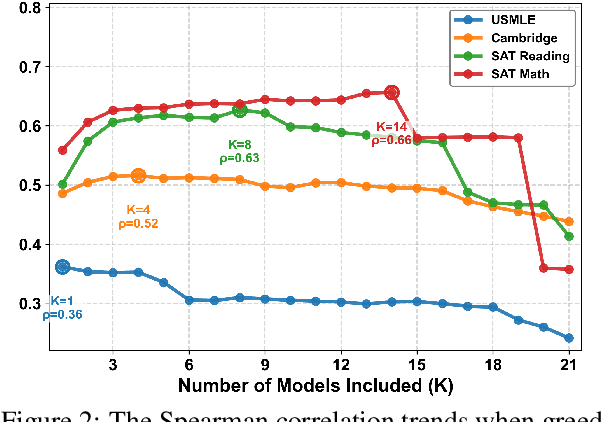
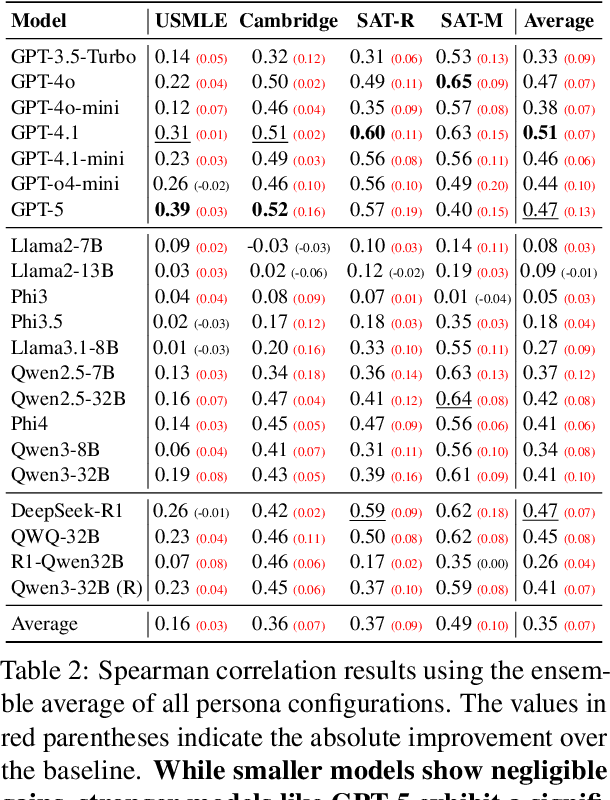
Accurate estimation of item (question or task) difficulty is critical for educational assessment but suffers from the cold start problem. While Large Language Models demonstrate superhuman problem-solving capabilities, it remains an open question whether they can perceive the cognitive struggles of human learners. In this work, we present a large-scale empirical analysis of Human-AI Difficulty Alignment for over 20 models across diverse domains such as medical knowledge and mathematical reasoning. Our findings reveal a systematic misalignment where scaling up model size is not reliably helpful; instead of aligning with humans, models converge toward a shared machine consensus. We observe that high performance often impedes accurate difficulty estimation, as models struggle to simulate the capability limitations of students even when being explicitly prompted to adopt specific proficiency levels. Furthermore, we identify a critical lack of introspection, as models fail to predict their own limitations. These results suggest that general problem-solving capability does not imply an understanding of human cognitive struggles, highlighting the challenge of using current models for automated difficulty prediction.
STARS: Semantic Tokens with Augmented Representations for Recommendation at Scale
Dec 13, 2025



Real-world ecommerce recommender systems must deliver relevant items under strict tens-of-milliseconds latency constraints despite challenges such as cold-start products, rapidly shifting user intent, and dynamic context including seasonality, holidays, and promotions. We introduce STARS, a transformer-based sequential recommendation framework built for large-scale, low-latency ecommerce settings. STARS combines several innovations: dual-memory user embeddings that separate long-term preferences from short-term session intent; semantic item tokens that fuse pretrained text embeddings, learnable deltas, and LLM-derived attribute tags, strengthening content-based matching, long-tail coverage, and cold-start performance; context-aware scoring with learned calendar and event offsets; and a latency-conscious two-stage retrieval pipeline that performs offline embedding generation and online maximum inner-product search with filtering, enabling tens-of-milliseconds response times. In offline evaluations on production-scale data, STARS improves Hit@5 by more than 75 percent relative to our existing LambdaMART system. A large-scale A/B test on 6 million visits shows statistically significant lifts, including Total Orders +0.8%, Add-to-Cart on Home +2.0%, and Visits per User +0.5%. These results demonstrate that combining semantic enrichment, multi-intent modeling, and deployment-oriented design can yield state-of-the-art recommendation quality in real-world environments without sacrificing serving efficiency.
R-Capsule: Compressing High-Level Plans for Efficient Large Language Model Reasoning
Sep 26, 2025Chain-of-Thought (CoT) prompting helps Large Language Models (LLMs) tackle complex reasoning by eliciting explicit step-by-step rationales. However, CoT's verbosity increases latency and memory usage and may propagate early errors across long chains. We propose the Reasoning Capsule (R-Capsule), a framework that aims to combine the efficiency of latent reasoning with the transparency of explicit CoT. The core idea is to compress the high-level plan into a small set of learned latent tokens (a Reasoning Capsule) while keeping execution steps lightweight or explicit. This hybrid approach is inspired by the Information Bottleneck (IB) principle, where we encourage the capsule to be approximately minimal yet sufficient for the task. Minimality is encouraged via a low-capacity bottleneck, which helps improve efficiency. Sufficiency is encouraged via a dual objective: a primary task loss for answer accuracy and an auxiliary plan-reconstruction loss that encourages the capsule to faithfully represent the original textual plan. The reconstruction objective helps ground the latent space, thereby improving interpretability and reducing the use of uninformative shortcuts. Our framework strikes a balance between efficiency, accuracy, and interpretability, thereby reducing the visible token footprint of reasoning while maintaining or improving accuracy on complex benchmarks. Our codes are available at: https://anonymous.4open.science/r/Reasoning-Capsule-7BE0
HEPP: Hyper-efficient Perception and Planning for High-speed Obstacle Avoidance of UAVs
May 23, 2025High-speed obstacle avoidance of uncrewed aerial vehicles (UAVs) in cluttered environments is a significant challenge. Existing UAV planning and obstacle avoidance systems can only fly at moderate speeds or at high speeds over empty or sparse fields. In this article, we propose a hyper-efficient perception and planning system for the high-speed obstacle avoidance of UAVs. The system mainly consists of three modules: 1) A novel incremental robocentric mapping method with distance and gradient information, which takes 89.5% less time compared to existing methods. 2) A novel obstacle-aware topological path search method that generates multiple distinct paths. 3) An adaptive gradient-based high-speed trajectory generation method with a novel time pre-allocation algorithm. With these innovations, the system has an excellent real-time performance with only milliseconds latency in each iteration, taking 79.24% less time than existing methods at high speeds (15 m/s in cluttered environments), allowing UAVs to fly swiftly and avoid obstacles in cluttered environments. The planned trajectory of the UAV is close to the global optimum in both temporal and spatial domains. Finally, extensive validations in both simulation and real-world experiments demonstrate the effectiveness of our proposed system for high-speed navigation in cluttered environments.