 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025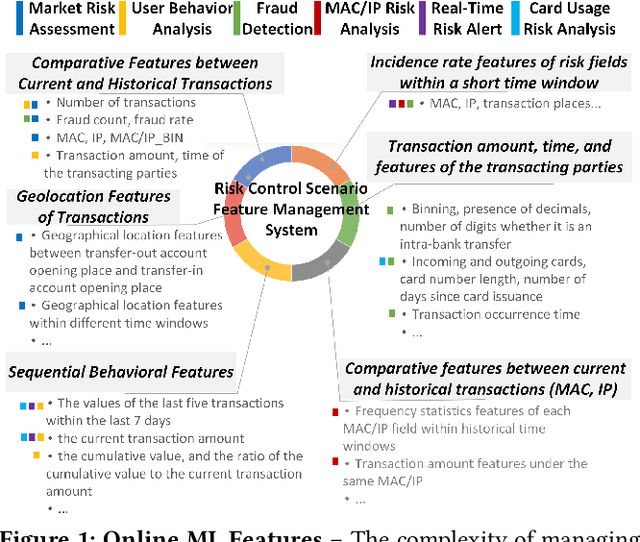
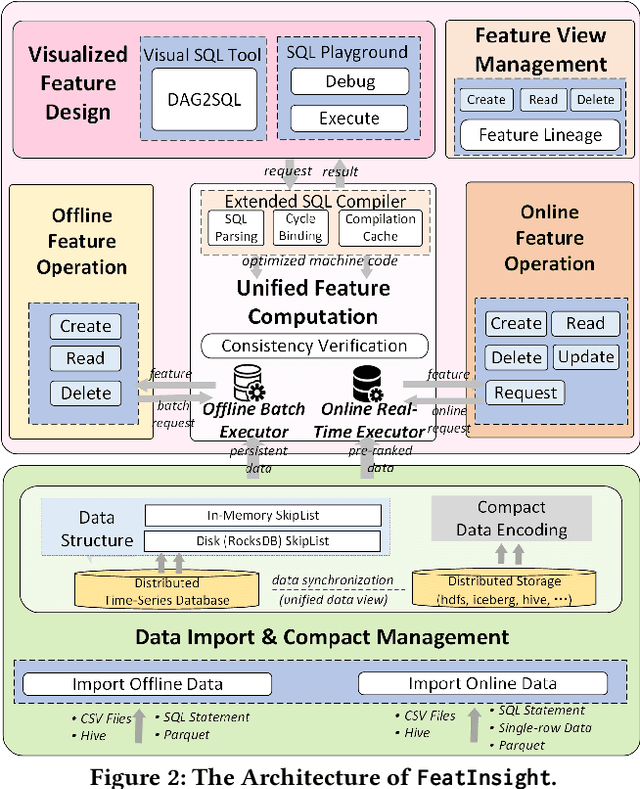
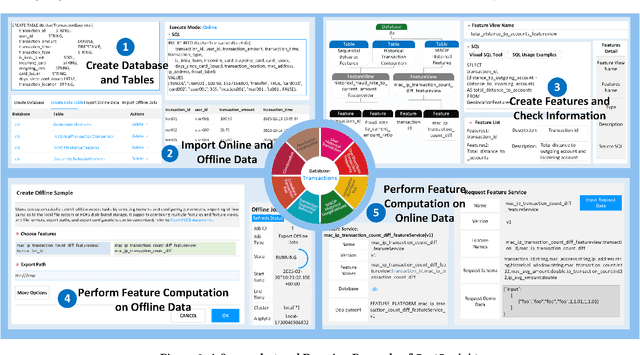
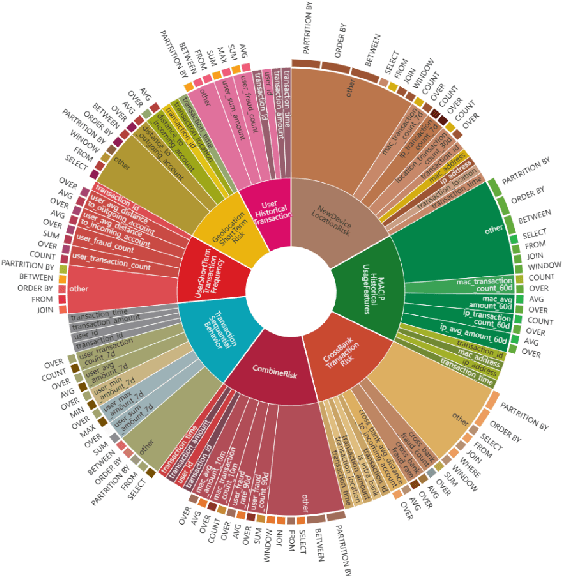
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
Mar 25, 2025



We introduce LogQuant, a groundbreaking 2-bit quantization technique for KV Cache in large language model (LLM) inference, delivering substantial memory savings while preserving superior performance. Previous methods either assume that later tokens are more important or attempt to predict important tokens based on earlier attention patterns. Both approaches, however, can result in performance bottlenecks or frequent mispredictions. LogQuant takes a different approach. By applying a log-based filtering mechanism, it selectively compresses the KV Cache across the entire context, achieving better performance with the same or even reduced memory footprint compared to existing methods. In benchmark tests, it enhances throughput by 25% and boosts batch size by 60% without increasing memory consumption. For challenging tasks such as Math and Code Completion, LogQuant improves accuracy by 40% to 200% at the same compression ratio, outperforming comparable techniques.LogQuant integrates effortlessly with popular inference frameworks like Python's transformers library. Implementation can be available in https://github.com/Concyclics/LogQuantKV.
OpenMLDB: A Real-Time Relational Data Feature Computation System for Online ML
Jan 15, 2025



Efficient and consistent feature computation is crucial for a wide range of online ML applications. Typically, feature computation is divided into two distinct phases, i.e., offline stage for model training and online stage for model serving. These phases often rely on execution engines with different interface languages and function implementations, causing significant inconsistencies. Moreover, many online ML features involve complex time-series computations (e.g., functions over varied-length table windows) that differ from standard streaming and analytical queries. Existing data processing systems (e.g., Spark, Flink, DuckDB) often incur multi-second latencies for these computations, making them unsuitable for real-time online ML applications that demand timely feature updates. This paper presents OpenMLDB, a feature computation system deployed in 4Paradigm's SageOne platform and over 100 real scenarios. Technically, OpenMLDB first employs a unified query plan generator for consistent computation results across the offline and online stages, significantly reducing feature deployment overhead. Second, OpenMLDB provides an online execution engine that resolves performance bottlenecks caused by long window computations (via pre-aggregation) and multi-table window unions (via data self-adjusting). It also provides a high-performance offline execution engine with window parallel optimization and time-aware data skew resolving. Third, OpenMLDB features a compact data format and stream-focused indexing to maximize memory usage and accelerate data access. Evaluations in testing and real workloads reveal significant performance improvements and resource savings compared to the baseline systems. The open community of OpenMLDB now has over 150 contributors and gained 1.6k stars on GitHub.
OEBench: Investigating Open Environment Challenges in Real-World Relational Data Streams
Sep 03, 2023



How to get insights from relational data streams in a timely manner is a hot research topic. This type of data stream can present unique challenges, such as distribution drifts, outliers, emerging classes, and changing features, which have recently been described as open environment challenges for machine learning. While existing studies have been done on incremental learning for data streams, their evaluations are mostly conducted with manually partitioned datasets. Thus, a natural question is how those open environment challenges look like in real-world relational data streams and how existing incremental learning algorithms perform on real datasets. To fill this gap, we develop an Open Environment Benchmark named OEBench to evaluate open environment challenges in relational data streams. Specifically, we investigate 55 real-world relational data streams and establish that open environment scenarios are indeed widespread in real-world datasets, which presents significant challenges for stream learning algorithms. Through benchmarks with existing incremental learning algorithms, we find that increased data quantity may not consistently enhance the model accuracy when applied in open environment scenarios, where machine learning models can be significantly compromised by missing values, distribution shifts, or anomalies in real-world data streams. The current techniques are insufficient in effectively mitigating these challenges posed by open environments. More researches are needed to address real-world open environment challenges. All datasets and code are open-sourced in https://github.com/sjtudyq/OEBench.
A Framework for Fast Polarity Labelling of Massive Data Streams
Mar 23, 2022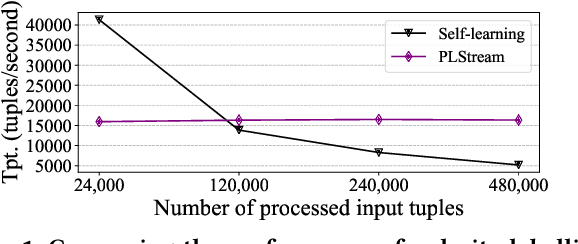
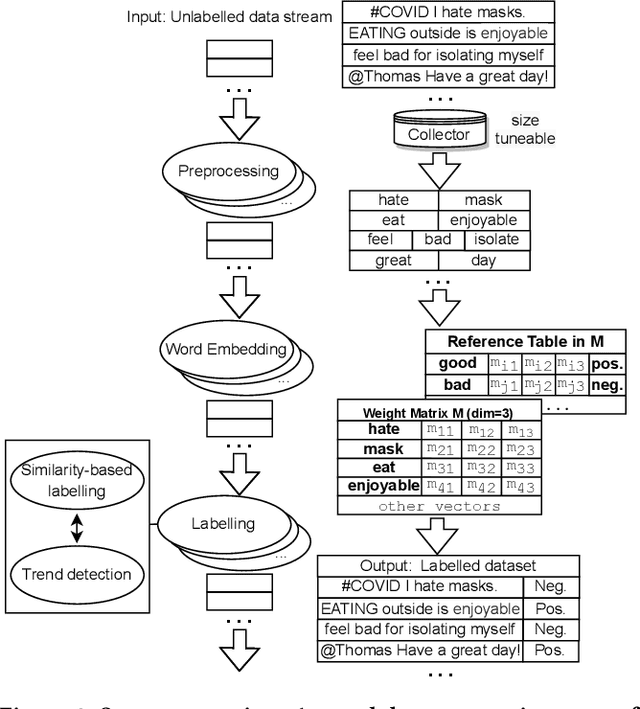
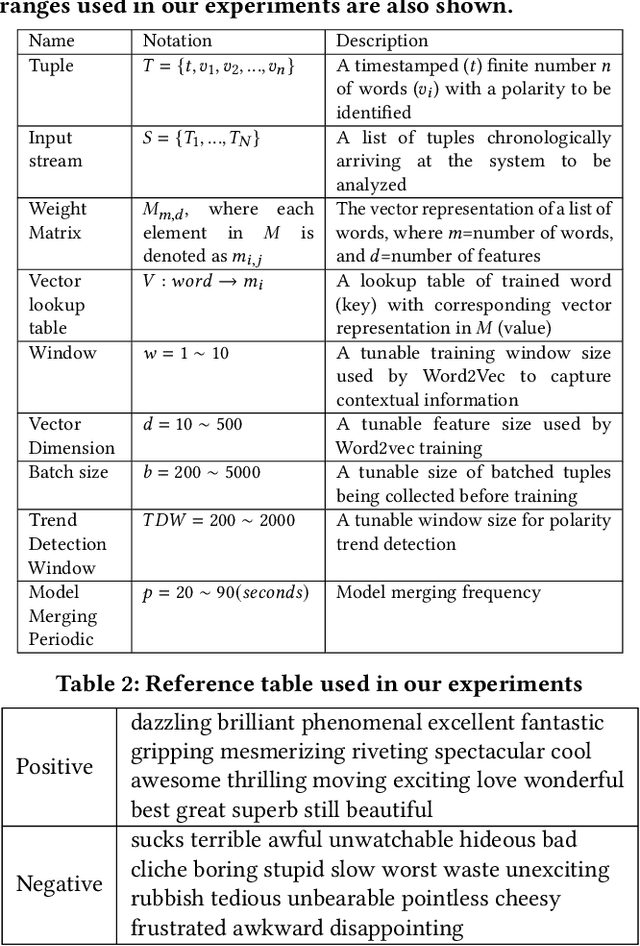
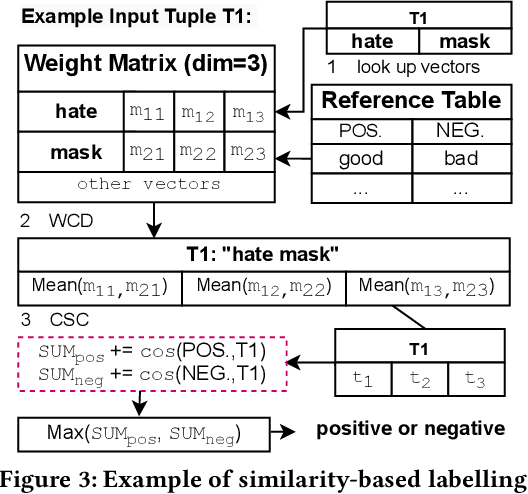
Many of the existing sentiment analysis techniques are based on supervised learning, and they demand the availability of valuable training datasets to train their models. When dataset freshness is critical, the annotating of high speed unlabelled data streams becomes critical but remains an open problem. In this paper, we propose PLStream, a novel Apache Flink-based framework for fast polarity labelling of massive data streams, like Twitter tweets or online product reviews. We address the associated implementation challenges and propose a list of techniques including both algorithmic improvements and system optimizations. A thorough empirical validation with two real-world workloads demonstrates that PLStream is able to generate high quality labels (almost 80% accuracy) in the presence of high-speed continuous unlabelled data streams (almost 16,000 tuples/sec) without any manual efforts.