 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Fast Polarity Labelling of Massive Data Streams
Paper and Code
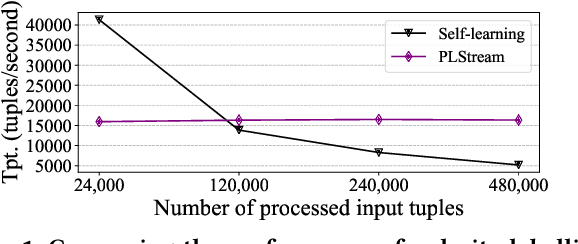
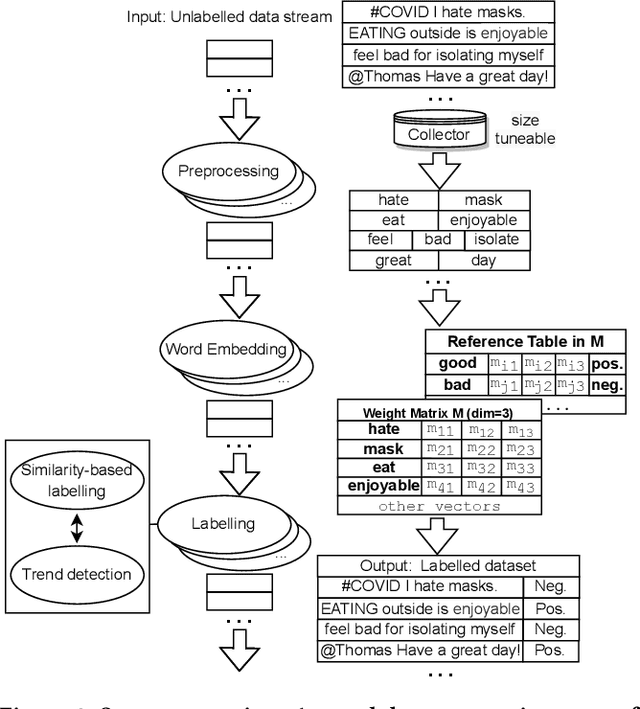
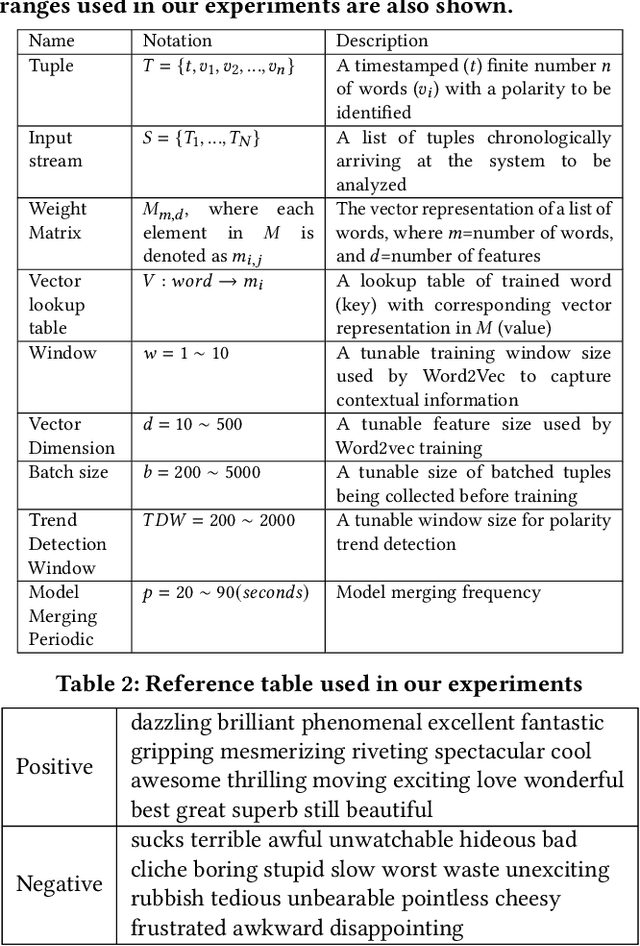
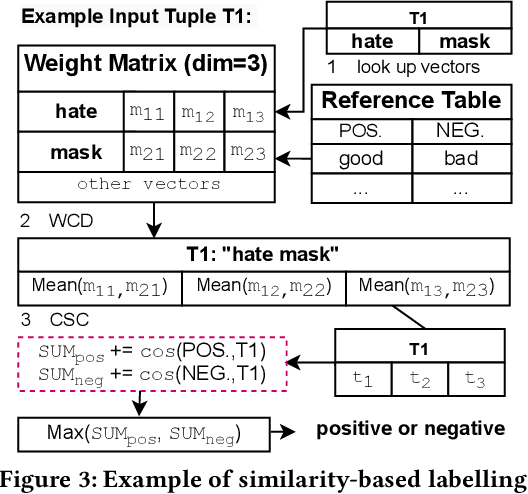
Many of the existing sentiment analysis techniques are based on supervised learning, and they demand the availability of valuable training datasets to train their models. When dataset freshness is critical, the annotating of high speed unlabelled data streams becomes critical but remains an open problem. In this paper, we propose PLStream, a novel Apache Flink-based framework for fast polarity labelling of massive data streams, like Twitter tweets or online product reviews. We address the associated implementation challenges and propose a list of techniques including both algorithmic improvements and system optimizations. A thorough empirical validation with two real-world workloads demonstrates that PLStream is able to generate high quality labels (almost 80% accuracy) in the presence of high-speed continuous unlabelled data streams (almost 16,000 tuples/sec) without any manual efforts.