 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromem: A Granular Decomposition of the Streaming Lifecycle in External Memory for LLMs
Feb 15, 2026Most evaluations of External Memory Module assume a static setting: memory is built offline and queried at a fixed state. In practice, memory is streaming: new facts arrive continuously, insertions interleave with retrievals, and the memory state evolves while the model is serving queries. In this regime, accuracy and cost are governed by the full memory lifecycle, which encompasses the ingestion, maintenance, retrieval, and integration of information into generation. We present Neuromem, a scalable testbed that benchmarks External Memory Modules under an interleaved insertion-and-retrieval protocol and decomposes its lifecycle into five dimensions including memory data structure, normalization strategy, consolidation policy, query formulation strategy, and context integration mechanism. Using three representative datasets LOCOMO, LONGMEMEVAL, and MEMORYAGENTBENCH, Neuromem evaluates interchangeable variants within a shared serving stack, reporting token-level F1 and insertion/retrieval latency. Overall, we observe that performance typically degrades as memory grows across rounds, and time-related queries remain the most challenging category. The memory data structure largely determines the attainable quality frontier, while aggressive compression and generative integration mechanisms mostly shift cost between insertion and retrieval with limited accuracy gain.
All-Atom GPCR-Ligand Simulation via Residual Isometric Latent Flow
Feb 03, 2026G-protein-coupled receptors (GPCRs), primary targets for over one-third of approved therapeutics, rely on intricate conformational transitions to transduce signals. While Molecular Dynamics (MD) is essential for elucidating this transduction process, particularly within ligand-bound complexes, conventional all-atom MD simulation is computationally prohibitive. In this paper, we introduce GPCRLMD, a deep generative framework for efficient all-atom GPCR-ligand simulation.GPCRLMD employs a Harmonic-Prior Variational Autoencoder (HP-VAE) to first map the complex into a regularized isometric latent space, preserving geometric topology via physics-informed constraints. Within this latent space, a Residual Latent Flow samples evolution trajectories, which are subsequently decoded back to atomic coordinates. By capturing temporal dynamics via relative displacements anchored to the initial structure, this residual mechanism effectively decouples static topology from dynamic fluctuations. Experimental results demonstrate that GPCRLMD achieves state-of-the-art performance in GPCR-ligand dynamics simulation, faithfully reproducing thermodynamic observables and critical ligand-receptor interactions.
Models Under SCOPE: Scalable and Controllable Routing via Pre-hoc Reasoning
Jan 29, 2026Model routing chooses which language model to use for each query. By sending easy queries to cheaper models and hard queries to stronger ones, it can significantly reduce inference cost while maintaining high accuracy. However, most existing routers treat this as a fixed choice among a small set of models, which makes them hard to adapt to new models or changing budget constraints. In this paper, we propose SCOPE (Scalable and Controllable Outcome Performance Estimator), a routing framework that goes beyond model selection by predicting their cost and performance. Trained with reinforcement learning, SCOPE makes reasoning-based predictions by retrieving how models behave on similar problems, rather than relying on fixed model names, enabling it to work with new, unseen models. Moreover, by explicitly predicting how accurate and how expensive a model will be, it turns routing into a dynamic decision problem, allowing users to easily control the trade-off between accuracy and cost. Experiments show that SCOPE is more than just a cost-saving tool. It flexibly adapts to user needs: it can boost accuracy by up to 25.7% when performance is the priority, or cut costs by up to 95.1% when efficiency matters most.
ActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
DLP: Dynamic Layerwise Pruning in Large Language Models
May 27, 2025Pruning has recently been widely adopted to reduce the parameter scale and improve the inference efficiency of Large Language Models (LLMs). Mainstream pruning techniques often rely on uniform layerwise pruning strategies, which can lead to severe performance degradation at high sparsity levels. Recognizing the varying contributions of different layers in LLMs, recent studies have shifted their focus toward non-uniform layerwise pruning. However, these approaches often rely on pre-defined values, which can result in suboptimal performance. To overcome these limitations, we propose a novel method called Dynamic Layerwise Pruning (DLP). This approach adaptively determines the relative importance of each layer by integrating model weights with input activation information, assigning pruning rates accordingly. Experimental results show that DLP effectively preserves model performance at high sparsity levels across multiple LLMs. Specifically, at 70% sparsity, DLP reduces the perplexity of LLaMA2-7B by 7.79 and improves the average accuracy by 2.7% compared to state-of-the-art methods. Moreover, DLP is compatible with various existing LLM compression techniques and can be seamlessly integrated into Parameter-Efficient Fine-Tuning (PEFT). We release the code at https://github.com/ironartisan/DLP to facilitate future research.
CEFW: A Comprehensive Evaluation Framework for Watermark in Large Language Models
Mar 24, 2025Text watermarking provides an effective solution for identifying synthetic text generated by large language models. However, existing techniques often focus on satisfying specific criteria while ignoring other key aspects, lacking a unified evaluation. To fill this gap, we propose the Comprehensive Evaluation Framework for Watermark (CEFW), a unified framework that comprehensively evaluates watermarking methods across five key dimensions: ease of detection, fidelity of text quality, minimal embedding cost, robustness to adversarial attacks, and imperceptibility to prevent imitation or forgery. By assessing watermarks according to all these key criteria, CEFW offers a thorough evaluation of their practicality and effectiveness. Moreover, we introduce a simple and effective watermarking method called Balanced Watermark (BW), which guarantees robustness and imperceptibility through balancing the way watermark information is added. Extensive experiments show that BW outperforms existing methods in overall performance across all evaluation dimensions. We release our code to the community for future research. https://github.com/DrankXs/BalancedWatermark.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
HSI: A Holistic Style Injector for Arbitrary Style Transfer
Feb 05, 2025Attention-based arbitrary style transfer methods have gained significant attention recently due to their impressive ability to synthesize style details. However, the point-wise matching within the attention mechanism may overly focus on local patterns such that neglect the remarkable global features of style images. Additionally, when processing large images, the quadratic complexity of the attention mechanism will bring high computational load. To alleviate above problems, we propose Holistic Style Injector (HSI), a novel attention-style transformation module to deliver artistic expression of target style. Specifically, HSI performs stylization only based on global style representation that is more in line with the characteristics of style transfer, to avoid generating local disharmonious patterns in stylized images. Moreover, we propose a dual relation learning mechanism inside the HSI to dynamically render images by leveraging semantic similarity in content and style, ensuring the stylized images preserve the original content and improve style fidelity. Note that the proposed HSI achieves linear computational complexity because it establishes feature mapping through element-wise multiplication rather than matrix multiplication. Qualitative and quantitative results demonstrate that our method outperforms state-of-the-art approaches in both effectiveness and efficiency.
Robustified Time-optimal Point-to-point Motion Planning and Control under Uncertainty
Jan 24, 2025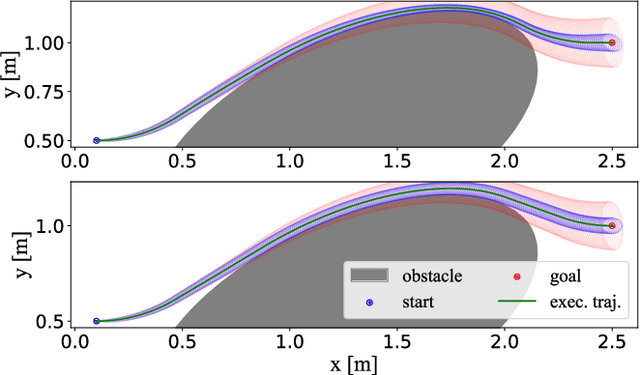
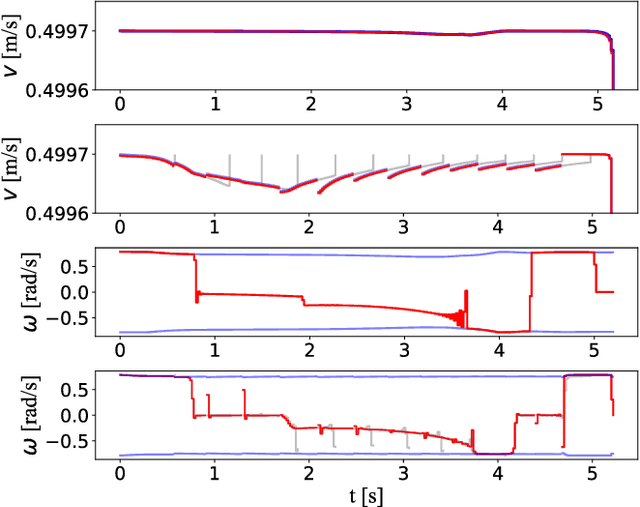
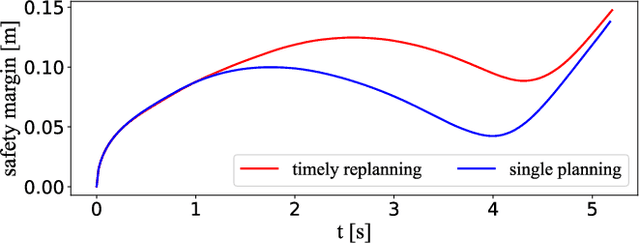
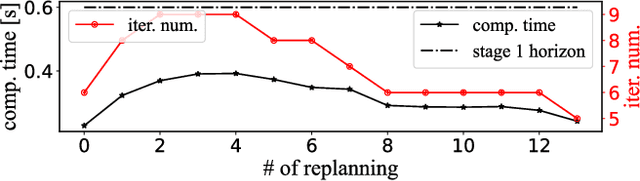
This paper proposes a novel approach to formulate time-optimal point-to-point motion planning and control under uncertainty. The approach defines a robustified two-stage Optimal Control Problem (OCP), in which stage 1, with a fixed time grid, is seamlessly stitched with stage 2, which features a variable time grid. Stage 1 optimizes not only the nominal trajectory, but also feedback gains and corresponding state covariances, which robustify constraints in both stages. The outcome is a minimized uncertainty in stage 1 and a minimized total motion time for stage 2, both contributing to the time optimality and safety of the total motion. A timely replanning strategy is employed to handle changes in constraints and maintain feasibility, while a tailored iterative algorithm is proposed for efficient, real-time OCP execution.
SRTFD: Scalable Real-Time Fault Diagnosis through Online Continual Learning
Aug 11, 2024



Fault diagnosis (FD) is essential for maintaining operational safety and minimizing economic losses by detecting system abnormalities. Recently, deep learning (DL)-driven FD methods have gained prominence, offering significant improvements in precision and adaptability through the utilization of extensive datasets and advanced DL models. Modern industrial environments, however, demand FD methods that can handle new fault types, dynamic conditions, large-scale data, and provide real-time responses with minimal prior information. Although online continual learning (OCL) demonstrates potential in addressing these requirements by enabling DL models to continuously learn from streaming data, it faces challenges such as data redundancy, imbalance, and limited labeled data. To overcome these limitations, we propose SRTFD, a scalable real-time fault diagnosis framework that enhances OCL with three critical methods: Retrospect Coreset Selection (RCS), which selects the most relevant data to reduce redundant training and improve efficiency; Global Balance Technique (GBT), which ensures balanced coreset selection and robust model performance; and Confidence and Uncertainty-driven Pseudo-label Learning (CUPL), which updates the model using unlabeled data for continuous adaptation. Extensive experiments on a real-world dataset and two public simulated datasets demonstrate SRTFD's effectiveness and potential for providing advanced, scalable, and precise fault diagnosis in modern industrial systems.