 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Tokens: Internalizing Causal Supervision in Vision-Language Model for Multi-Image Causal Reasoning
Jun 10, 2026Visual causal reasoning is essential for understanding and intervening in the physical world, requiring identification of causal variables from visual inputs and reasoning over intervention effects. Despite recent progress, large vision--language models (VLMs) remain brittle at such tasks, especially for interventional and counterfactual queries over multi-image inputs. Most existing explorations inject causal knowledge via textual prompts, leaving causal mechanisms external to model execution and limiting reliable control during inference. To address this problem, we propose BridgeVLM, which internalizes visual causal reasoning by inducing a causal graph from multi-image inputs and converting it into structured Causal Tokens executed by RAMP layers injected into the LLM decoder for causal message passing. We further introduce a unified training interface M3S for fine-grained causal supervision from different granularities (local/global level). BridgeVLM achieves 54.4% accuracy on intervention tasks on CausalVLBench (vs. 33.2% with prompt-level supervision), improves results on Causal3D from 43.6% to 49.0%, and substantially improves causal structure learning on CausalVLBench ($F_1$: 33.4% $\rightarrow$ 75.1%).
Neutrality Bites: Gender Representation in AI-Generated Animal Stories
Jun 06, 2026Gender bias in AI-generated stories is a well-documented problem. While much attention has been paid to reducing or mitigating this bias, it is not always clear whether interventions produce genuinely fairer results. To investigate this issue, we examine how large language models (LLMs) handle gender assignment in a narrative context that is popular, highly ambiguous, and also known to closely reproduce human stereotypes: stories about talking animals. We prompt six leading LLMs to complete an English-language story about seven different anthropomorphic animal characters whose gender is unstated. We additionally iterate with four different narrative settings and a range of model temperatures. Across the 23.8K stories, we find that models frequently avoid gendering the animal character in the story (19% on average) or use gender-neutral language like "it" or "its" (38.2% on average). However, when gender is assigned, there is a significant masculine bias. Feminine animal characters are virtually absent, present in just 2.2% of stories vs. 40.6% that feature masculine characters. Our findings point to a broader argument: neutrality bites. In other words, models that prioritize neutrality to address social bias may actually contribute to the erasure of marginalized perspectives and identities. We suggest that alternative strategies beyond neutrality need to be pursued, such as ones that more equally distribute social possibilities across imagined subjects.
Brewing Knowledge in Context: Distillation Perspectives on In-Context Learning
Jun 13, 2025In-context learning (ICL) allows large language models (LLMs) to solve novel tasks without weight updates. Despite its empirical success, the mechanism behind ICL remains poorly understood, limiting our ability to interpret, improve, and reliably apply it. In this paper, we propose a new theoretical perspective that interprets ICL as an implicit form of knowledge distillation (KD), where prompt demonstrations guide the model to form a task-specific reference model during inference. Under this view, we derive a Rademacher complexity-based generalization bound and prove that the bias of the distilled weights grows linearly with the Maximum Mean Discrepancy (MMD) between the prompt and target distributions. This theoretical framework explains several empirical phenomena and unifies prior gradient-based and distributional analyses. To the best of our knowledge, this is the first to formalize inference-time attention as a distillation process, which provides theoretical insights for future prompt engineering and automated demonstration selection.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
E-3SFC: Communication-Efficient Federated Learning with Double-way Features Synthesizing
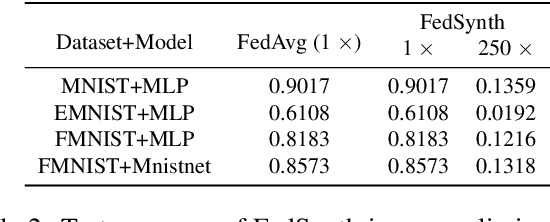
Feb 05, 2025The exponential growth in model sizes has significantly increased the communication burden in Federated Learning (FL). Existing methods to alleviate this burden by transmitting compressed gradients often face high compression errors, which slow down the model's convergence. To simultaneously achieve high compression effectiveness and lower compression errors, we study the gradient compression problem from a novel perspective. Specifically, we propose a systematical algorithm termed Extended Single-Step Synthetic Features Compressing (E-3SFC), which consists of three sub-components, i.e., the Single-Step Synthetic Features Compressor (3SFC), a double-way compression algorithm, and a communication budget scheduler. First, we regard the process of gradient computation of a model as decompressing gradients from corresponding inputs, while the inverse process is considered as compressing the gradients. Based on this, we introduce a novel gradient compression method termed 3SFC, which utilizes the model itself as a decompressor, leveraging training priors such as model weights and objective functions. 3SFC compresses raw gradients into tiny synthetic features in a single-step simulation, incorporating error feedback to minimize overall compression errors. To further reduce communication overhead, 3SFC is extended to E-3SFC, allowing double-way compression and dynamic communication budget scheduling. Our theoretical analysis under both strongly convex and non-convex conditions demonstrates that 3SFC achieves linear and sub-linear convergence rates with aggregation noise. Extensive experiments across six datasets and six models reveal that 3SFC outperforms state-of-the-art methods by up to 13.4% while reducing communication costs by 111.6 times. These findings suggest that 3SFC can significantly enhance communication efficiency in FL without compromising model performance.
Federated cINN Clustering for Accurate Clustered Federated Learning
Sep 04, 2023Federated Learning (FL) presents an innovative approach to privacy-preserving distributed machine learning and enables efficient crowd intelligence on a large scale. However, a significant challenge arises when coordinating FL with crowd intelligence which diverse client groups possess disparate objectives due to data heterogeneity or distinct tasks. To address this challenge, we propose the Federated cINN Clustering Algorithm (FCCA) to robustly cluster clients into different groups, avoiding mutual interference between clients with data heterogeneity, and thereby enhancing the performance of the global model. Specifically, FCCA utilizes a global encoder to transform each client's private data into multivariate Gaussian distributions. It then employs a generative model to learn encoded latent features through maximum likelihood estimation, which eases optimization and avoids mode collapse. Finally, the central server collects converged local models to approximate similarities between clients and thus partition them into distinct clusters. Extensive experimental results demonstrate FCCA's superiority over other state-of-the-art clustered federated learning algorithms, evaluated on various models and datasets. These results suggest that our approach has substantial potential to enhance the efficiency and accuracy of real-world federated learning tasks.
Communication-efficient Federated Learning with Single-Step Synthetic Features Compressor for Faster Convergence
Mar 19, 2023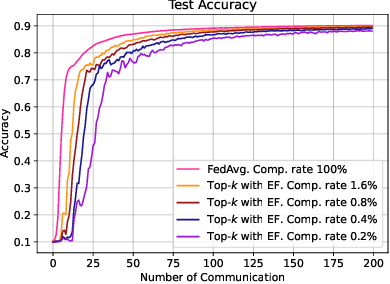


Reducing communication overhead in federated learning (FL) is challenging but crucial for large-scale distributed privacy-preserving machine learning. While methods utilizing sparsification or others can largely lower the communication overhead, the convergence rate is also greatly compromised. In this paper, we propose a novel method, named single-step synthetic features compressor (3SFC), to achieve communication-efficient FL by directly constructing a tiny synthetic dataset based on raw gradients. Thus, 3SFC can achieve an extremely low compression rate when the constructed dataset contains only one data sample. Moreover, 3SFC's compressing phase utilizes a similarity-based objective function so that it can be optimized with just one step, thereby considerably improving its performance and robustness. In addition, to minimize the compressing error, error feedback (EF) is also incorporated into 3SFC. Experiments on multiple datasets and models suggest that 3SFC owns significantly better convergence rates compared to competing methods with lower compression rates (up to 0.02%). Furthermore, ablation studies and visualizations show that 3SFC can carry more information than competing methods for every communication round, further validating its effectiveness.
Semantic Evolutionary Concept Distances for Effective Information Retrieval in Query Expansion
Jan 19, 2017
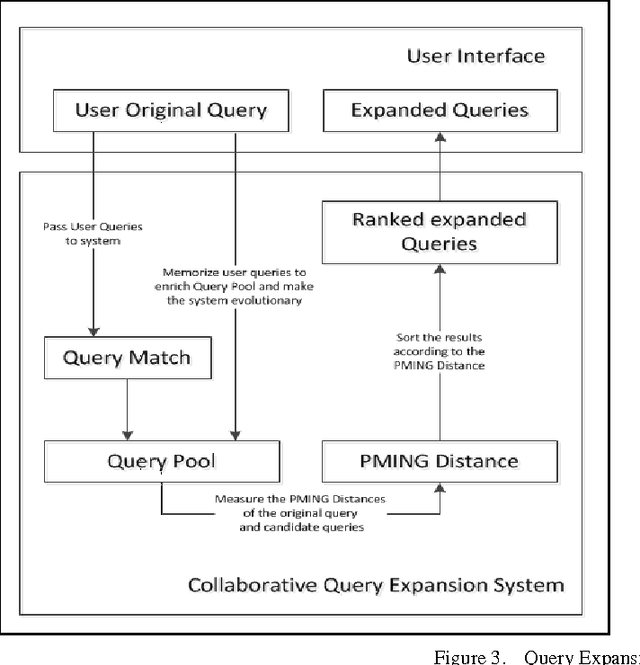

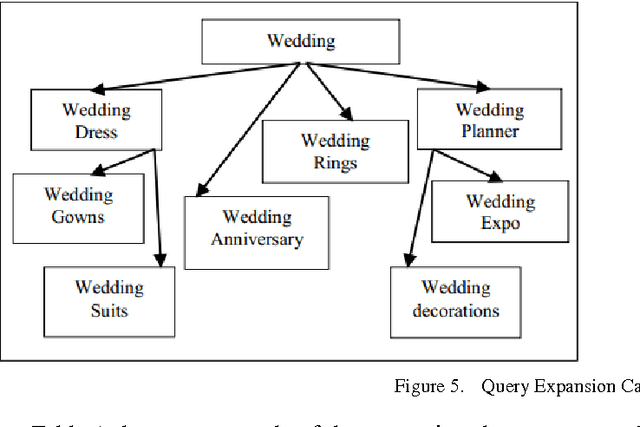
In this work several semantic approaches to concept-based query expansion and reranking schemes are studied and compared with different ontology-based expansion methods in web document search and retrieval. In particular, we focus on concept-based query expansion schemes, where, in order to effectively increase the precision of web document retrieval and to decrease the users browsing time, the main goal is to quickly provide users with the most suitable query expansion. Two key tasks for query expansion in web document retrieval are to find the expansion candidates, as the closest concepts in web document domain, and to rank the expanded queries properly. The approach we propose aims at improving the expansion phase for better web document retrieval and precision. The basic idea is to measure the distance between candidate concepts using the PMING distance, a collaborative semantic proximity measure, i.e. a measure which can be computed by using statistical results from web search engine. Experiments show that the proposed technique can provide users with more satisfying expansion results and improve the quality of web document retrieval.
* author's copy of publication in NLCS ICCSA 2013 proceedings: Collective Evolutionary Concept Distance Based Query Expansion for Effective Web Document Retrieval
Web-based Semantic Similarity for Emotion Recognition in Web Objects
Dec 17, 2016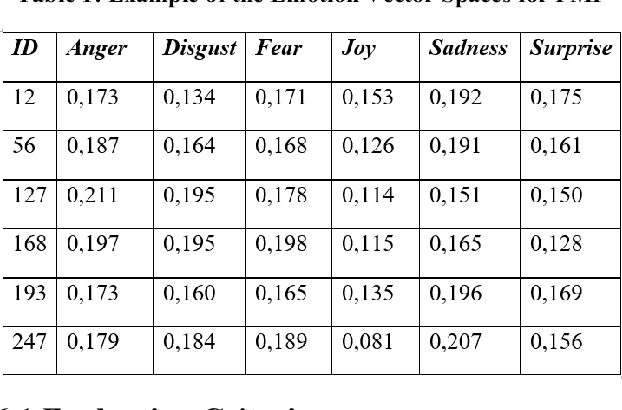

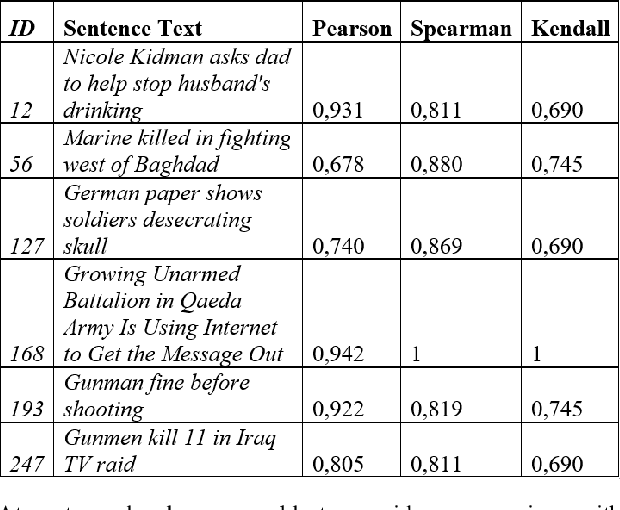
In this project we propose a new approach for emotion recognition using web-based similarity (e.g. confidence, PMI and PMING). We aim to extract basic emotions from short sentences with emotional content (e.g. news titles, tweets, captions), performing a web-based quantitative evaluation of semantic proximity between each word of the analyzed sentence and each emotion of a psychological model (e.g. Plutchik, Ekman, Lovheim). The phases of the extraction include: text preprocessing (tokenization, stop words, filtering), search engine automated query, HTML parsing of results (i.e. scraping), estimation of semantic proximity, ranking of emotions according to proximity measures. The main idea is that, since it is possible to generalize semantic similarity under the assumption that similar concepts co-occur in documents indexed in search engines, therefore also emotions can be generalized in the same way, through tags or terms that express them in a particular language, ranking emotions. Training results are compared to human evaluation, then additional comparative tests on results are performed, both for the global ranking correlation (e.g. Kendall, Spearman, Pearson) both for the evaluation of the emotion linked to each single word. Different from sentiment analysis, our approach works at a deeper level of abstraction, aiming at recognizing specific emotions and not only the positive/negative sentiment, in order to predict emotions as semantic data.
* Authors preprint, including revision differences with respect to the main publication 'Web-based Similarity for Emotion Recognition in Web Objects' published in the UCC '16 workshop in IEEE UCC, December 06 - 09, 2016, Shanghai, China. DOI: http://dx.doi.org/10.1145/2996890.3007883