 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrewing Knowledge in Context: Distillation Perspectives on In-Context Learning
Jun 13, 2025In-context learning (ICL) allows large language models (LLMs) to solve novel tasks without weight updates. Despite its empirical success, the mechanism behind ICL remains poorly understood, limiting our ability to interpret, improve, and reliably apply it. In this paper, we propose a new theoretical perspective that interprets ICL as an implicit form of knowledge distillation (KD), where prompt demonstrations guide the model to form a task-specific reference model during inference. Under this view, we derive a Rademacher complexity-based generalization bound and prove that the bias of the distilled weights grows linearly with the Maximum Mean Discrepancy (MMD) between the prompt and target distributions. This theoretical framework explains several empirical phenomena and unifies prior gradient-based and distributional analyses. To the best of our knowledge, this is the first to formalize inference-time attention as a distillation process, which provides theoretical insights for future prompt engineering and automated demonstration selection.
Retinal Vessel Segmentation with Deep Graph and Capsule Reasoning
Sep 17, 2024
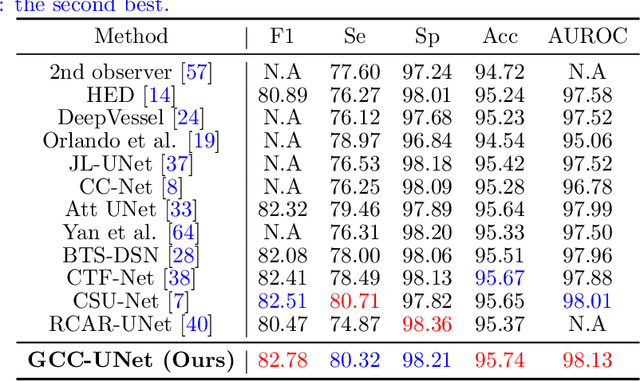

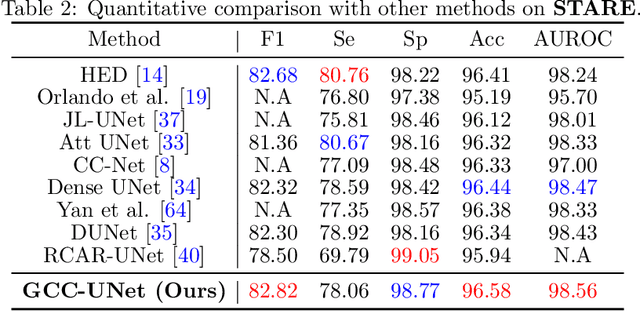
Effective retinal vessel segmentation requires a sophisticated integration of global contextual awareness and local vessel continuity. To address this challenge, we propose the Graph Capsule Convolution Network (GCC-UNet), which merges capsule convolutions with CNNs to capture both local and global features. The Graph Capsule Convolution operator is specifically designed to enhance the representation of global context, while the Selective Graph Attention Fusion module ensures seamless integration of local and global information. To further improve vessel continuity, we introduce the Bottleneck Graph Attention module, which incorporates Channel-wise and Spatial Graph Attention mechanisms. The Multi-Scale Graph Fusion module adeptly combines features from various scales. Our approach has been rigorously validated through experiments on widely used public datasets, with ablation studies confirming the efficacy of each component. Comparative results highlight GCC-UNet's superior performance over existing methods, setting a new benchmark in retinal vessel segmentation. Notably, this work represents the first integration of vanilla, graph, and capsule convolutional techniques in the domain of medical image segmentation.