 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Graph Contrastive Masked Autoencoders are Strong Distillers for EEG
Nov 28, 2024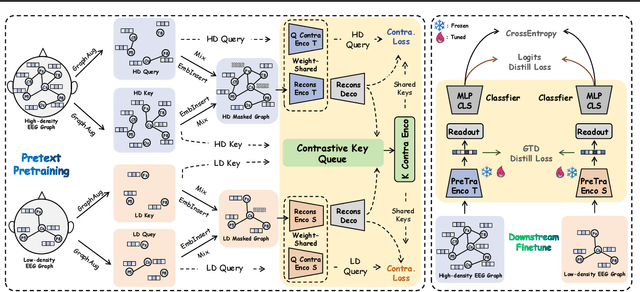
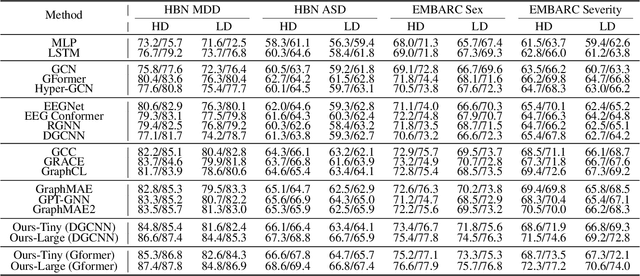


Effectively utilizing extensive unlabeled high-density EEG data to improve performance in scenarios with limited labeled low-density EEG data presents a significant challenge. In this paper, we address this by framing it as a graph transfer learning and knowledge distillation problem. We propose a Unified Pre-trained Graph Contrastive Masked Autoencoder Distiller, named EEG-DisGCMAE, to bridge the gap between unlabeled/labeled and high/low-density EEG data. To fully leverage the abundant unlabeled EEG data, we introduce a novel unified graph self-supervised pre-training paradigm, which seamlessly integrates Graph Contrastive Pre-training and Graph Masked Autoencoder Pre-training. This approach synergistically combines contrastive and generative pre-training techniques by reconstructing contrastive samples and contrasting the reconstructions. For knowledge distillation from high-density to low-density EEG data, we propose a Graph Topology Distillation loss function, allowing a lightweight student model trained on low-density data to learn from a teacher model trained on high-density data, effectively handling missing electrodes through contrastive distillation. To integrate transfer learning and distillation, we jointly pre-train the teacher and student models by contrasting their queries and keys during pre-training, enabling robust distillers for downstream tasks. We demonstrate the effectiveness of our method on four classification tasks across two clinical EEG datasets with abundant unlabeled data and limited labeled data. The experimental results show that our approach significantly outperforms contemporary methods in both efficiency and accuracy.
VPBSD:Vessel-Pattern-Based Semi-Supervised Distillation for Efficient 3D Microscopic Cerebrovascular Segmentation
Nov 14, 2024



3D microscopic cerebrovascular images are characterized by their high resolution, presenting significant annotation challenges, large data volumes, and intricate variations in detail. Together, these factors make achieving high-quality, efficient whole-brain segmentation particularly demanding. In this paper, we propose a novel Vessel-Pattern-Based Semi-Supervised Distillation pipeline (VpbSD) to address the challenges of 3D microscopic cerebrovascular segmentation. This pipeline initially constructs a vessel-pattern codebook that captures diverse vascular structures from unlabeled data during the teacher model's pretraining phase. In the knowledge distillation stage, the codebook facilitates the transfer of rich knowledge from a heterogeneous teacher model to a student model, while the semi-supervised approach further enhances the student model's exposure to diverse learning samples. Experimental results on real-world data, including comparisons with state-of-the-art methods and ablation studies, demonstrate that our pipeline and its individual components effectively address the challenges inherent in microscopic cerebrovascular segmentation.
Multi-modal Cross-domain Self-supervised Pre-training for fMRI and EEG Fusion
Sep 27, 2024Neuroimaging techniques including functional magnetic resonance imaging (fMRI) and electroencephalogram (EEG) have shown promise in detecting functional abnormalities in various brain disorders. However, existing studies often focus on a single domain or modality, neglecting the valuable complementary information offered by multiple domains from both fMRI and EEG, which is crucial for a comprehensive representation of disorder pathology. This limitation poses a challenge in effectively leveraging the synergistic information derived from these modalities. To address this, we propose a Multi-modal Cross-domain Self-supervised Pre-training Model (MCSP), a novel approach that leverages self-supervised learning to synergize multi-modal information across spatial, temporal, and spectral domains. Our model employs cross-domain self-supervised loss that bridges domain differences by implementing domain-specific data augmentation and contrastive loss, enhancing feature discrimination. Furthermore, MCSP introduces cross-modal self-supervised loss to capitalize on the complementary information of fMRI and EEG, facilitating knowledge distillation within domains and maximizing cross-modal feature convergence. We constructed a large-scale pre-training dataset and pretrained MCSP model by leveraging proposed self-supervised paradigms to fully harness multimodal neuroimaging data. Through comprehensive experiments, we have demonstrated the superior performance and generalizability of our model on multiple classification tasks. Our study contributes a significant advancement in the fusion of fMRI and EEG, marking a novel integration of cross-domain features, which enriches the existing landscape of neuroimaging research, particularly within the context of mental disorder studies.
Retinal Vessel Segmentation with Deep Graph and Capsule Reasoning
Sep 17, 2024
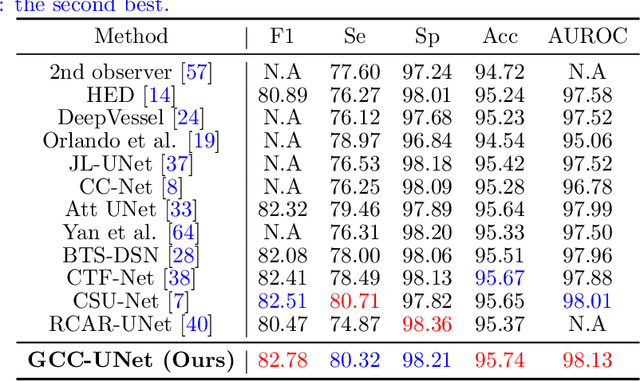

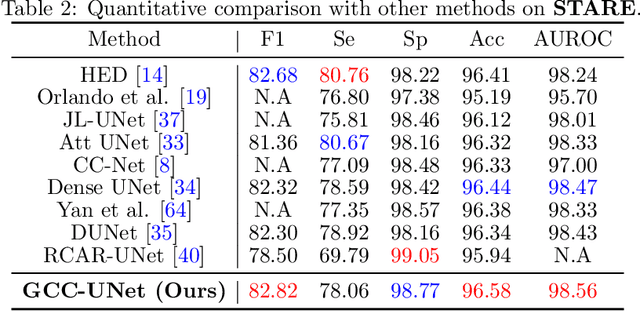
Effective retinal vessel segmentation requires a sophisticated integration of global contextual awareness and local vessel continuity. To address this challenge, we propose the Graph Capsule Convolution Network (GCC-UNet), which merges capsule convolutions with CNNs to capture both local and global features. The Graph Capsule Convolution operator is specifically designed to enhance the representation of global context, while the Selective Graph Attention Fusion module ensures seamless integration of local and global information. To further improve vessel continuity, we introduce the Bottleneck Graph Attention module, which incorporates Channel-wise and Spatial Graph Attention mechanisms. The Multi-Scale Graph Fusion module adeptly combines features from various scales. Our approach has been rigorously validated through experiments on widely used public datasets, with ablation studies confirming the efficacy of each component. Comparative results highlight GCC-UNet's superior performance over existing methods, setting a new benchmark in retinal vessel segmentation. Notably, this work represents the first integration of vanilla, graph, and capsule convolutional techniques in the domain of medical image segmentation.
Orientation and Context Entangled Network for Retinal Vessel Segmentation
Jul 23, 2022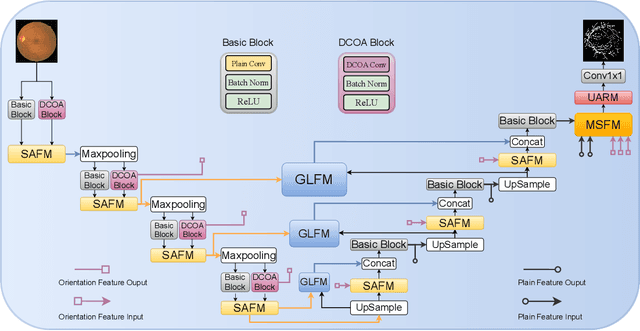

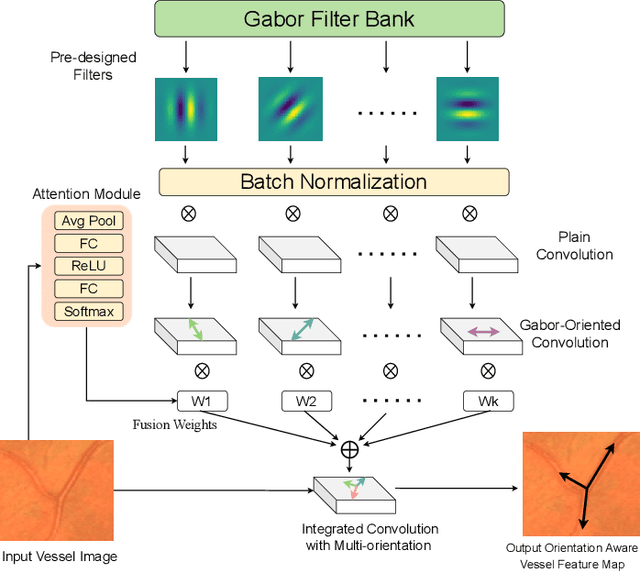
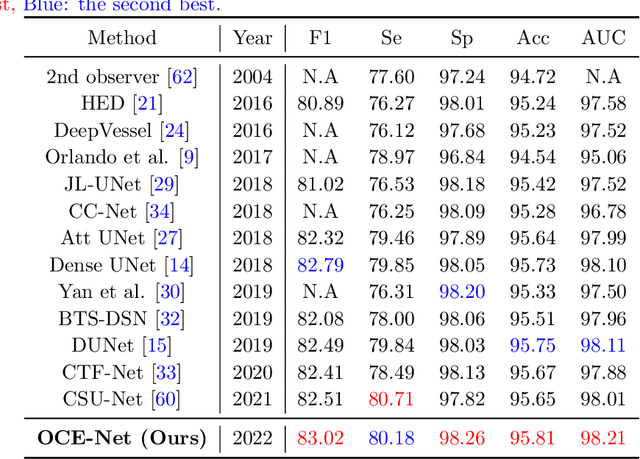
Most of the existing deep learning based methods for vessel segmentation neglect two important aspects of retinal vessels, one is the orientation information of vessels, and the other is the contextual information of the whole fundus region. In this paper, we propose a robust Orientation and Context Entangled Network (denoted as OCE-Net), which has the capability of extracting complex orientation and context information of the blood vessels. To achieve complex orientation aware, a Dynamic Complex Orientation Aware Convolution (DCOA Conv) is proposed to extract complex vessels with multiple orientations for improving the vessel continuity. To simultaneously capture the global context information and emphasize the important local information, a Global and Local Fusion Module (GLFM) is developed to simultaneously model the long-range dependency of vessels and focus sufficient attention on local thin vessels. A novel Orientation and Context Entangled Non-local (OCE-NL) module is proposed to entangle the orientation and context information together. In addition, an Unbalanced Attention Refining Module (UARM) is proposed to deal with the unbalanced pixel numbers of background, thick and thin vessels. Extensive experiments were performed on several commonly used datasets (DRIVE, STARE and CHASEDB1) and some more challenging datasets (AV-WIDE, UoA-DR, RFMiD and UK Biobank). The ablation study shows that the proposed method achieves promising performance on maintaining the continuity of thin vessels and the comparative experiments demonstrate that our OCE-Net can achieve state-of-the-art performance on retinal vessel segmentation.
Deep Pneumonia: Attention-Based Contrastive Learning for Class-Imbalanced Pneumonia Lesion Recognition in Chest X-rays
Jul 23, 2022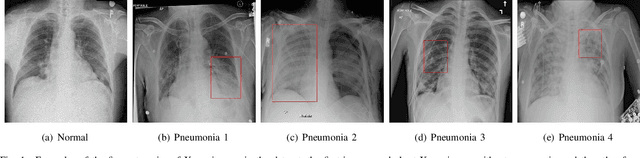
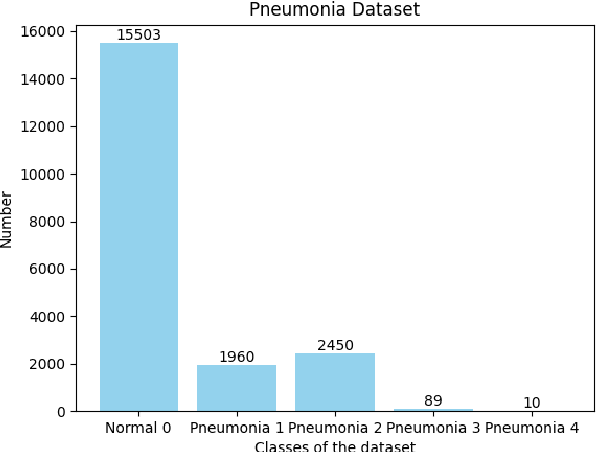
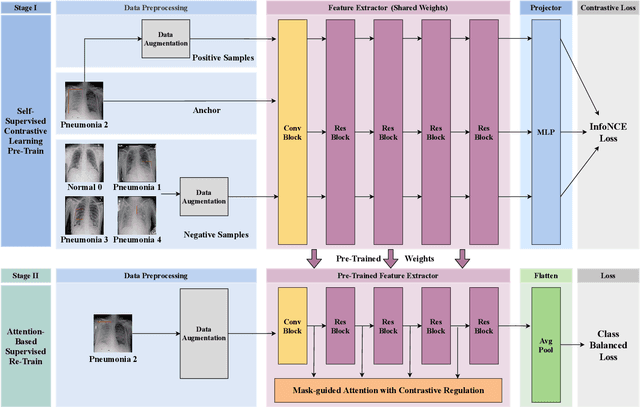
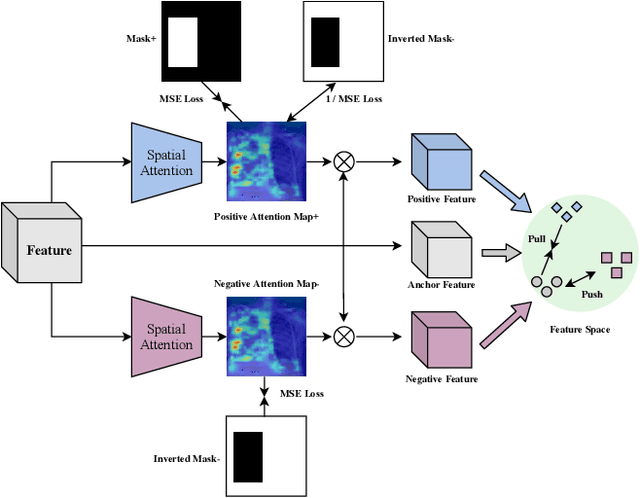
Computer-aided X-ray pneumonia lesion recognition is important for accurate diagnosis of pneumonia. With the emergence of deep learning, the identification accuracy of pneumonia has been greatly improved, but there are still some challenges due to the fuzzy appearance of chest X-rays. In this paper, we propose a deep learning framework named Attention-Based Contrastive Learning for Class-Imbalanced X-Ray Pneumonia Lesion Recognition (denoted as Deep Pneumonia). We adopt self-supervised contrastive learning strategy to pre-train the model without using extra pneumonia data for fully mining the limited available dataset. In order to leverage the location information of the lesion area that the doctor has painstakingly marked, we propose mask-guided hard attention strategy and feature learning with contrastive regulation strategy which are applied on the attention map and the extracted features respectively to guide the model to focus more attention on the lesion area where contains more discriminative features for improving the recognition performance. In addition, we adopt Class-Balanced Loss instead of traditional Cross-Entropy as the loss function of classification to tackle the problem of serious class imbalance between different classes of pneumonia in the dataset. The experimental results show that our proposed framework can be used as a reliable computer-aided pneumonia diagnosis system to assist doctors to better diagnose pneumonia cases accurately.
TSN-CA: A Two-Stage Network with Channel Attention for Low-Light Image Enhancement
Oct 06, 2021



Low-light image enhancement is a challenging low-level computer vision task because after we enhance the brightness of the image, we have to deal with amplified noise, color distortion, detail loss, blurred edges, shadow blocks and halo artifacts. In this paper, we propose a Two-Stage Network with Channel Attention (denoted as TSN-CA) to enhance the brightness of the low-light image and restore the enhanced images from various kinds of degradation. In the first stage, we enhance the brightness of the low-light image in HSV space and use the information of H and S channels to help the recovery of details in V channel. In the second stage, we integrate Channel Attention (CA) mechanism into the skip connection of U-Net in order to restore the brightness-enhanced image from severe kinds of degradation in RGB space. We train and evaluate the performance of our proposed model on the LOL real-world and synthetic datasets. In addition, we test our model on several other commonly used datasets without Ground-Truth. We conduct extensive experiments to demonstrate that our method achieves excellent effect on brightness enhancement as well as denoising, details preservation and halo artifacts elimination. Our method outperforms many other state-of-the-art methods qualitatively and quantitatively.
DA-DRN: Degradation-Aware Deep Retinex Network for Low-Light Image Enhancement
Oct 05, 2021
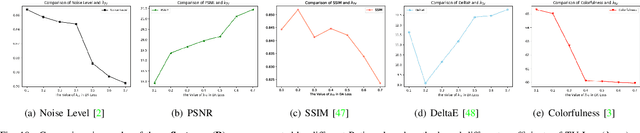

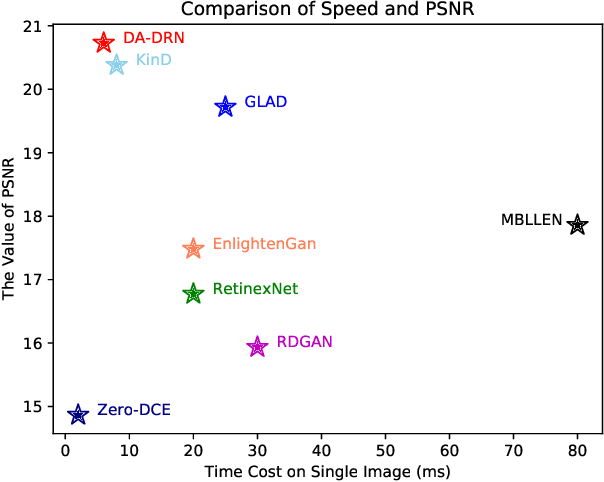
Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color distortion, unknown noise, detail loss and halo artifacts. In this paper, we propose a Degradation-Aware Deep Retinex Network (denoted as DA-DRN) for low-light image enhancement and tackle the above degradation. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination maps and deal with the degradation in the reflectance during the decomposition phase directly. We propose a Degradation-Aware Module (DA Module) which can guide the training process of the decomposer and enable the decomposer to be a restorer during the training phase without additional computational cost in the test phase. DA Module can achieve the purpose of noise removal while preserving detail information into the illumination map as well as tackle color distortion and halo artifacts. We introduce Perceptual Loss to train the enhancement network to generate the brightness-improved illumination maps which are more consistent with human visual perception. We train and evaluate the performance of our proposed model over the LOL real-world and LOL synthetic datasets, and we also test our model over several other frequently used datasets without Ground-Truth (LIME, DICM, MEF and NPE datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method only takes 7 ms to process an image with 600x400 resolution on a TITAN Xp GPU.
BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration
Jun 30, 2021

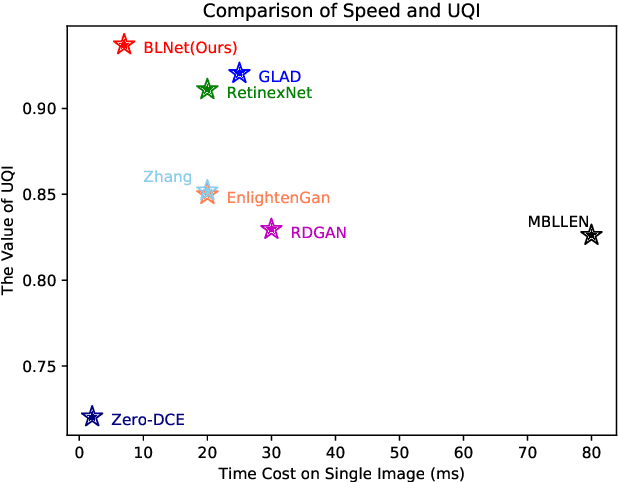

Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color bias, unknown noise, detail loss and halo artifacts. In this paper, we propose a very fast deep learning framework called Bringing the Lightness (denoted as BLNet) that consists of two U-Nets with a series of well-designed loss functions to tackle all of the above degradations. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination and remove noise in the reflectance during the decomposition phase. We propose a Noise and Color Bias Control module (NCBC Module) that contains a convolutional neural network and two loss functions (noise loss and color loss). This module is only used to calculate the loss functions during the training phase, so our method is very fast during the test phase. This module can smooth the reflectance to achieve the purpose of noise removal while preserving details and edge information and controlling color bias. We propose a network that can be trained to learn the mapping between low-light and normal-light illumination and enhance the brightness of images taken in low-light illumination. We train and evaluate the performance of our proposed model over the real-world Low-Light (LOL) dataset), and we also test our model over several other frequently used datasets (LIME, DICM and MEF datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method achieves high speed because we use loss functions instead of introducing additional denoisers for noise removal and color correction. The code and model are available at https://github.com/weixinxu666/BLNet.