 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Lightweight Framework for Efficient Land-Air Bimodal Robot Autonomous Navigation
Jul 30, 2025Land-air bimodal robots (LABR) are gaining attention for autonomous navigation, combining high mobility from aerial vehicles with long endurance from ground vehicles. However, existing LABR navigation methods are limited by suboptimal trajectories from mapping-based approaches and the excessive computational demands of learning-based methods. To address this, we propose a two-stage lightweight framework that integrates global key points prediction with local trajectory refinement to generate efficient and reachable trajectories. In the first stage, the Global Key points Prediction Network (GKPN) was used to generate a hybrid land-air keypoint path. The GKPN includes a Sobel Perception Network (SPN) for improved obstacle detection and a Lightweight Attention Planning Network (LAPN) to improves predictive ability by capturing contextual information. In the second stage, the global path is segmented based on predicted key points and refined using a mapping-based planner to create smooth, collision-free trajectories. Experiments conducted on our LABR platform show that our framework reduces network parameters by 14\% and energy consumption during land-air transitions by 35\% compared to existing approaches. The framework achieves real-time navigation without GPU acceleration and enables zero-shot transfer from simulation to reality during
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Toward Better SSIM Loss for Unsupervised Monocular Depth Estimation
Jun 05, 2025Unsupervised monocular depth learning generally relies on the photometric relation among temporally adjacent images. Most of previous works use both mean absolute error (MAE) and structure similarity index measure (SSIM) with conventional form as training loss. However, they ignore the effect of different components in the SSIM function and the corresponding hyperparameters on the training. To address these issues, this work proposes a new form of SSIM. Compared with original SSIM function, the proposed new form uses addition rather than multiplication to combine the luminance, contrast, and structural similarity related components in SSIM. The loss function constructed with this scheme helps result in smoother gradients and achieve higher performance on unsupervised depth estimation. We conduct extensive experiments to determine the relatively optimal combination of parameters for our new SSIM. Based on the popular MonoDepth approach, the optimized SSIM loss function can remarkably outperform the baseline on the KITTI-2015 outdoor dataset.
* 12 pages,4 figures
Cross-Asset Risk Management: Integrating LLMs for Real-Time Monitoring of Equity, Fixed Income, and Currency Markets
Apr 05, 2025Large language models (LLMs) have emerged as powerful tools in the field of finance, particularly for risk management across different asset classes. In this work, we introduce a Cross-Asset Risk Management framework that utilizes LLMs to facilitate real-time monitoring of equity, fixed income, and currency markets. This innovative approach enables dynamic risk assessment by aggregating diverse data sources, ultimately enhancing decision-making processes. Our model effectively synthesizes and analyzes market signals to identify potential risks and opportunities while providing a holistic view of asset classes. By employing advanced analytics, we leverage LLMs to interpret financial texts, news articles, and market reports, ensuring that risks are contextualized within broader market narratives. Extensive backtesting and real-time simulations validate the framework, showing increased accuracy in predicting market shifts compared to conventional methods. The focus on real-time data integration enhances responsiveness, allowing financial institutions to manage risks adeptly under varying market conditions and promoting financial stability through the advanced application of LLMs in risk analysis.
Dynamic Hedging Strategies in Derivatives Markets with LLM-Driven Sentiment and News Analytics
Apr 05, 2025Dynamic hedging strategies are essential for effective risk management in derivatives markets, where volatility and market sentiment can greatly impact performance. This paper introduces a novel framework that leverages large language models (LLMs) for sentiment analysis and news analytics to inform hedging decisions. By analyzing textual data from diverse sources like news articles, social media, and financial reports, our approach captures critical sentiment indicators that reflect current market conditions. The framework allows for real-time adjustments to hedging strategies, adapting positions based on continuous sentiment signals. Backtesting results on historical derivatives data reveal that our dynamic hedging strategies achieve superior risk-adjusted returns compared to conventional static approaches. The incorporation of LLM-driven sentiment analysis into hedging practices presents a significant advancement in decision-making processes within derivatives trading. This research showcases how sentiment-informed dynamic hedging can enhance portfolio management and effectively mitigate associated risks.
Primary visual cortex contributes to color constancy by predicting rather than discounting the illuminant: evidence from a computational study
Dec 10, 2024



Color constancy (CC) is an important ability of the human visual system to stably perceive the colors of objects despite considerable changes in the color of the light illuminating them. While increasing evidence from the field of neuroscience supports that multiple levels of the visual system contribute to the realization of CC, how the primary visual cortex (V1) plays role in CC is not fully resolved. In specific, double-opponent (DO) neurons in V1 have been thought to contribute to realizing a degree of CC, but the computational mechanism is not clear. We build an electrophysiologically based V1 neural model to learn the color of the light source from a natural image dataset with the ground truth illuminants as the labels. Based on the qualitative and quantitative analysis of the responsive properties of the learned model neurons, we found that both the spatial structures and color weights of the receptive fields of the learned model neurons are quite similar to those of the simple and DO neurons recorded in V1. Computationally, DO cells perform more robustly than the simple cells in V1 for illuminant prediction. Therefore, this work provides computational evidence supporting that V1 DO neurons serve to realize color constancy by encoding the illuminant,which is contradictory to the common hypothesis that V1 contributes to CC by discounting the illuminant using its DO cells. This evidence is expected to not only help resolve the visual mechanisms of CC, but also provide inspiration to develop more effective computer vision models.
VPBSD:Vessel-Pattern-Based Semi-Supervised Distillation for Efficient 3D Microscopic Cerebrovascular Segmentation
Nov 14, 2024



3D microscopic cerebrovascular images are characterized by their high resolution, presenting significant annotation challenges, large data volumes, and intricate variations in detail. Together, these factors make achieving high-quality, efficient whole-brain segmentation particularly demanding. In this paper, we propose a novel Vessel-Pattern-Based Semi-Supervised Distillation pipeline (VpbSD) to address the challenges of 3D microscopic cerebrovascular segmentation. This pipeline initially constructs a vessel-pattern codebook that captures diverse vascular structures from unlabeled data during the teacher model's pretraining phase. In the knowledge distillation stage, the codebook facilitates the transfer of rich knowledge from a heterogeneous teacher model to a student model, while the semi-supervised approach further enhances the student model's exposure to diverse learning samples. Experimental results on real-world data, including comparisons with state-of-the-art methods and ablation studies, demonstrate that our pipeline and its individual components effectively address the challenges inherent in microscopic cerebrovascular segmentation.
Retinal Vessel Segmentation with Deep Graph and Capsule Reasoning
Sep 17, 2024
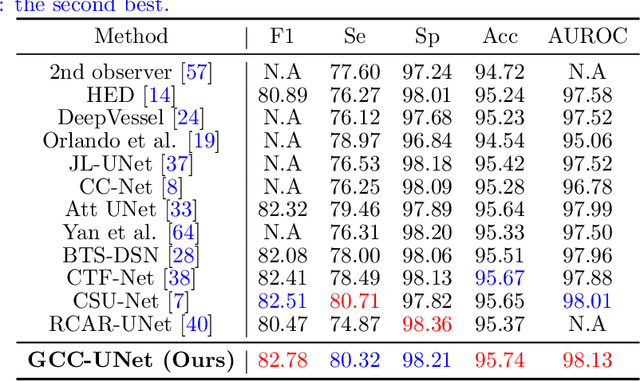

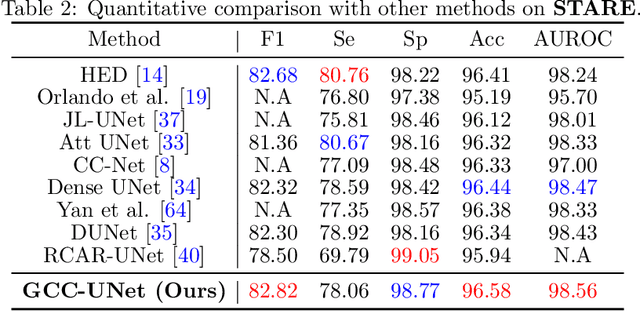
Effective retinal vessel segmentation requires a sophisticated integration of global contextual awareness and local vessel continuity. To address this challenge, we propose the Graph Capsule Convolution Network (GCC-UNet), which merges capsule convolutions with CNNs to capture both local and global features. The Graph Capsule Convolution operator is specifically designed to enhance the representation of global context, while the Selective Graph Attention Fusion module ensures seamless integration of local and global information. To further improve vessel continuity, we introduce the Bottleneck Graph Attention module, which incorporates Channel-wise and Spatial Graph Attention mechanisms. The Multi-Scale Graph Fusion module adeptly combines features from various scales. Our approach has been rigorously validated through experiments on widely used public datasets, with ablation studies confirming the efficacy of each component. Comparative results highlight GCC-UNet's superior performance over existing methods, setting a new benchmark in retinal vessel segmentation. Notably, this work represents the first integration of vanilla, graph, and capsule convolutional techniques in the domain of medical image segmentation.
Vector-Symbolic Architecture for Event-Based Optical Flow
May 15, 2024


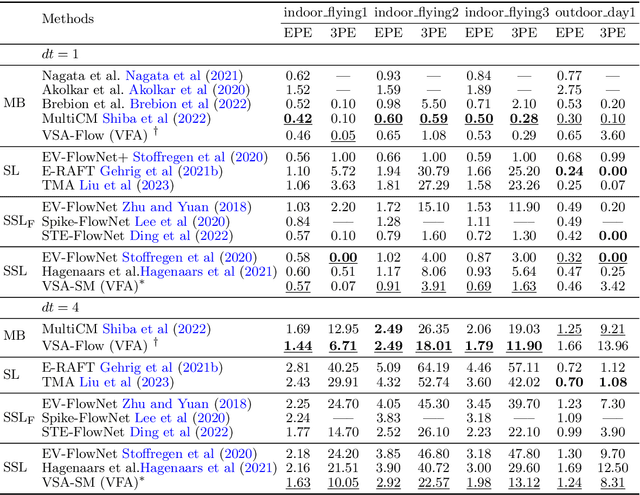
From a perspective of feature matching, optical flow estimation for event cameras involves identifying event correspondences by comparing feature similarity across accompanying event frames. In this work, we introduces an effective and robust high-dimensional (HD) feature descriptor for event frames, utilizing Vector Symbolic Architectures (VSA). The topological similarity among neighboring variables within VSA contributes to the enhanced representation similarity of feature descriptors for flow-matching points, while its structured symbolic representation capacity facilitates feature fusion from both event polarities and multiple spatial scales. Based on this HD feature descriptor, we propose a novel feature matching framework for event-based optical flow, encompassing both model-based (VSA-Flow) and self-supervised learning (VSA-SM) methods. In VSA-Flow, accurate optical flow estimation validates the effectiveness of HD feature descriptors. In VSA-SM, a novel similarity maximization method based on the HD feature descriptor is proposed to learn optical flow in a self-supervised way from events alone, eliminating the need for auxiliary grayscale images. Evaluation results demonstrate that our VSA-based method achieves superior accuracy in comparison to both model-based and self-supervised learning methods on the DSEC benchmark, while remains competitive among both methods on the MVSEC benchmark. This contribution marks a significant advancement in event-based optical flow within the feature matching methodology.
Unsupervised Vision and Vision-motion Calibration Strategies for PointGoal Navigation in Indoor Environment
Oct 02, 2022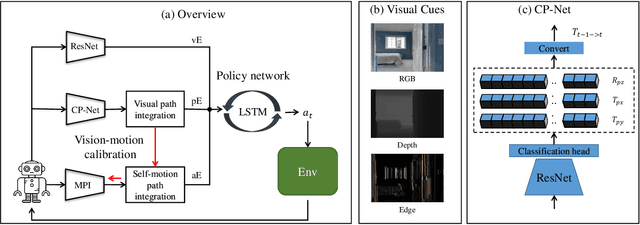
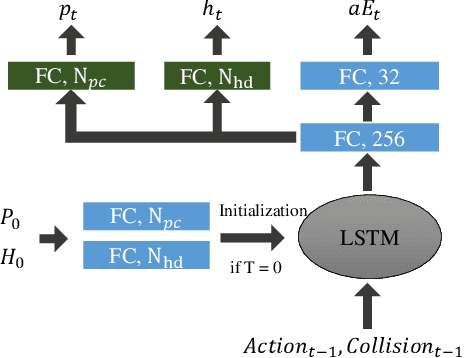
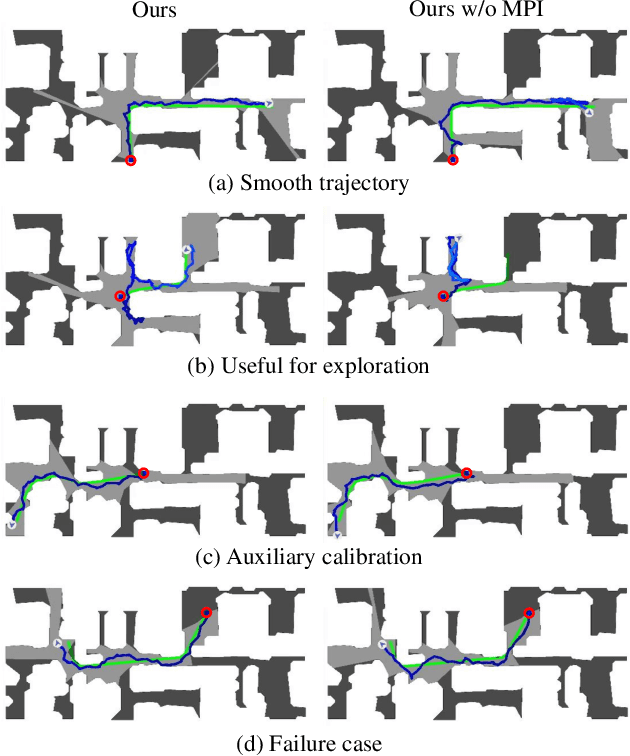
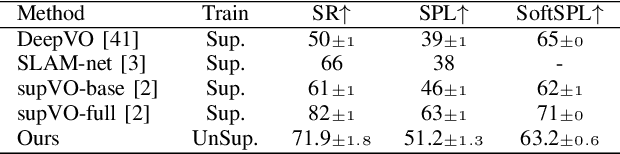
PointGoal navigation in indoor environment is a fundamental task for personal robots to navigate to a specified point. Recent studies solved this PointGoal navigation task with near-perfect success rate in photo-realistically simulated environments, under the assumptions with noiseless actuation and most importantly, perfect localization with GPS and compass sensors. However, accurate GPS signal can not be obtained in real indoor environment. To improve the pointgoal navigation accuracy in real indoor, we proposed novel vision and vision-motion calibration strategies to train visual and motion path integration in unsupervised manner. Sepecifically, visual calibration computes the relative pose of the agent from the re-projection error of two adjacent frames, and then replaces the accurate GPS signal with the path integration. This pseudo position is also used to calibrate self-motion integration which assists agent to update their internal perception of location and helps improve the success rate of navigation. The training and inference process only use RGB, depth, collision as well as self-action information. The experiments show that the proposed system achieves satisfactory results and outperforms the partially supervised learning algorithms on the popular Gibson dataset.