 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrientation and Context Entangled Network for Retinal Vessel Segmentation
Paper and Code
Jul 23, 2022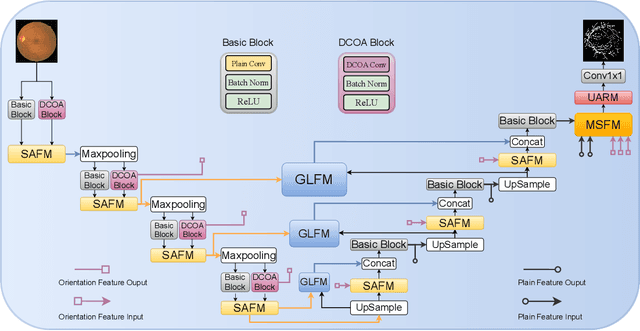

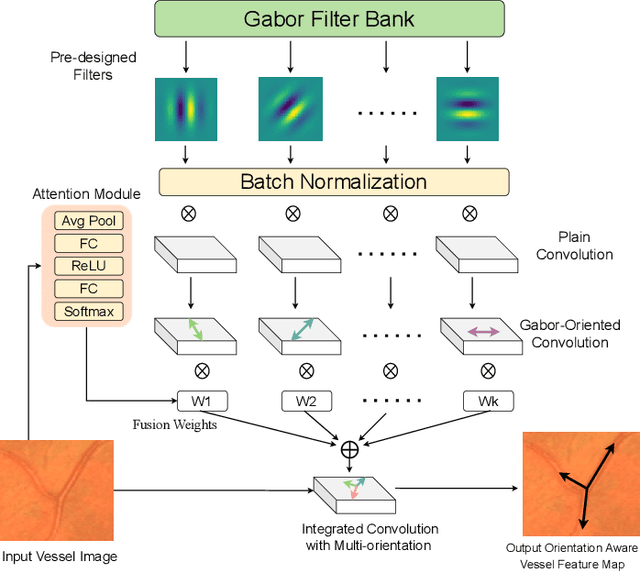
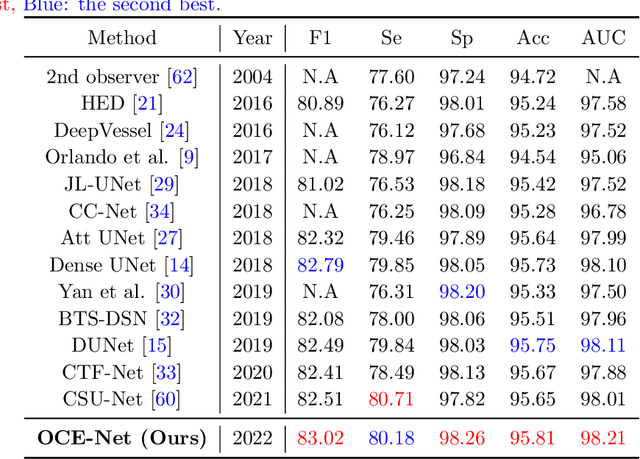
Most of the existing deep learning based methods for vessel segmentation neglect two important aspects of retinal vessels, one is the orientation information of vessels, and the other is the contextual information of the whole fundus region. In this paper, we propose a robust Orientation and Context Entangled Network (denoted as OCE-Net), which has the capability of extracting complex orientation and context information of the blood vessels. To achieve complex orientation aware, a Dynamic Complex Orientation Aware Convolution (DCOA Conv) is proposed to extract complex vessels with multiple orientations for improving the vessel continuity. To simultaneously capture the global context information and emphasize the important local information, a Global and Local Fusion Module (GLFM) is developed to simultaneously model the long-range dependency of vessels and focus sufficient attention on local thin vessels. A novel Orientation and Context Entangled Non-local (OCE-NL) module is proposed to entangle the orientation and context information together. In addition, an Unbalanced Attention Refining Module (UARM) is proposed to deal with the unbalanced pixel numbers of background, thick and thin vessels. Extensive experiments were performed on several commonly used datasets (DRIVE, STARE and CHASEDB1) and some more challenging datasets (AV-WIDE, UoA-DR, RFMiD and UK Biobank). The ablation study shows that the proposed method achieves promising performance on maintaining the continuity of thin vessels and the comparative experiments demonstrate that our OCE-Net can achieve state-of-the-art performance on retinal vessel segmentation.