 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimary visual cortex contributes to color constancy by predicting rather than discounting the illuminant: evidence from a computational study
Dec 10, 2024



Color constancy (CC) is an important ability of the human visual system to stably perceive the colors of objects despite considerable changes in the color of the light illuminating them. While increasing evidence from the field of neuroscience supports that multiple levels of the visual system contribute to the realization of CC, how the primary visual cortex (V1) plays role in CC is not fully resolved. In specific, double-opponent (DO) neurons in V1 have been thought to contribute to realizing a degree of CC, but the computational mechanism is not clear. We build an electrophysiologically based V1 neural model to learn the color of the light source from a natural image dataset with the ground truth illuminants as the labels. Based on the qualitative and quantitative analysis of the responsive properties of the learned model neurons, we found that both the spatial structures and color weights of the receptive fields of the learned model neurons are quite similar to those of the simple and DO neurons recorded in V1. Computationally, DO cells perform more robustly than the simple cells in V1 for illuminant prediction. Therefore, this work provides computational evidence supporting that V1 DO neurons serve to realize color constancy by encoding the illuminant,which is contradictory to the common hypothesis that V1 contributes to CC by discounting the illuminant using its DO cells. This evidence is expected to not only help resolve the visual mechanisms of CC, but also provide inspiration to develop more effective computer vision models.
Dual-Student Knowledge Distillation Networks for Unsupervised Anomaly Detection
Feb 01, 2024Due to the data imbalance and the diversity of defects, student-teacher networks (S-T) are favored in unsupervised anomaly detection, which explores the discrepancy in feature representation derived from the knowledge distillation process to recognize anomalies. However, vanilla S-T network is not stable. Employing identical structures to construct the S-T network may weaken the representative discrepancy on anomalies. But using different structures can increase the likelihood of divergent performance on normal data. To address this problem, we propose a novel dual-student knowledge distillation (DSKD) architecture. Different from other S-T networks, we use two student networks a single pre-trained teacher network, where the students have the same scale but inverted structures. This framework can enhance the distillation effect to improve the consistency in recognition of normal data, and simultaneously introduce diversity for anomaly representation. To explore high-dimensional semantic information to capture anomaly clues, we employ two strategies. First, a pyramid matching mode is used to perform knowledge distillation on multi-scale feature maps in the intermediate layers of networks. Second, an interaction is facilitated between the two student networks through a deep feature embedding module, which is inspired by real-world group discussions. In terms of classification, we obtain pixel-wise anomaly segmentation maps by measuring the discrepancy between the output feature maps of the teacher and student networks, from which an anomaly score is computed for sample-wise determination. We evaluate DSKD on three benchmark datasets and probe the effects of internal modules through ablation experiments. The results demonstrate that DSKD can achieve exceptional performance on small models like ResNet18 and effectively improve vanilla S-T networks.
Wider and Deeper, Cheaper and Faster: Tensorized LSTMs for Sequence Learning
Dec 13, 2017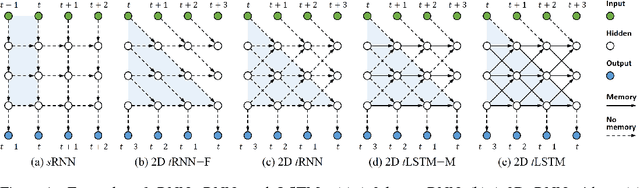


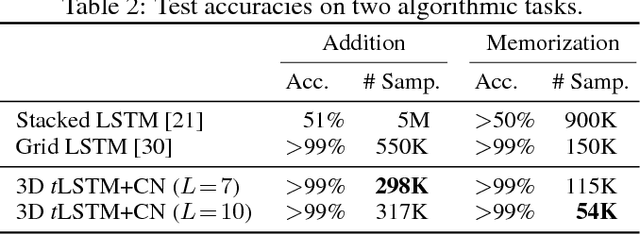
Long Short-Term Memory (LSTM) is a popular approach to boosting the ability of Recurrent Neural Networks to store longer term temporal information. The capacity of an LSTM network can be increased by widening and adding layers. However, usually the former introduces additional parameters, while the latter increases the runtime. As an alternative we propose the Tensorized LSTM in which the hidden states are represented by tensors and updated via a cross-layer convolution. By increasing the tensor size, the network can be widened efficiently without additional parameters since the parameters are shared across different locations in the tensor; by delaying the output, the network can be deepened implicitly with little additional runtime since deep computations for each timestep are merged into temporal computations of the sequence. Experiments conducted on five challenging sequence learning tasks show the potential of the proposed model.