 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarDiU: A Variational Diffusive Upper Bound for One-Step Diffusion Distillation
Aug 28, 2025
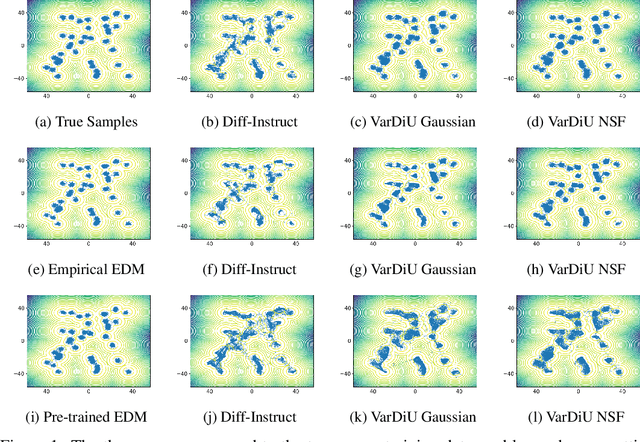


Recently, diffusion distillation methods have compressed thousand-step teacher diffusion models into one-step student generators while preserving sample quality. Most existing approaches train the student model using a diffusive divergence whose gradient is approximated via the student's score function, learned through denoising score matching (DSM). Since DSM training is imperfect, the resulting gradient estimate is inevitably biased, leading to sub-optimal performance. In this paper, we propose VarDiU (pronounced /va:rdju:/), a Variational Diffusive Upper Bound that admits an unbiased gradient estimator and can be directly applied to diffusion distillation. Using this objective, we compare our method with Diff-Instruct and demonstrate that it achieves higher generation quality and enables a more efficient and stable training procedure for one-step diffusion distillation.
Incremental Sequence Classification with Temporal Consistency
May 22, 2025We address the problem of incremental sequence classification, where predictions are updated as new elements in the sequence are revealed. Drawing on temporal-difference learning from reinforcement learning, we identify a temporal-consistency condition that successive predictions should satisfy. We leverage this condition to develop a novel loss function for training incremental sequence classifiers. Through a concrete example, we demonstrate that optimizing this loss can offer substantial gains in data efficiency. We apply our method to text classification tasks and show that it improves predictive accuracy over competing approaches on several benchmark datasets. We further evaluate our approach on the task of verifying large language model generations for correctness in grade-school math problems. Our results show that models trained with our method are better able to distinguish promising generations from unpromising ones after observing only a few tokens.
Towards Training One-Step Diffusion Models Without Distillation
Feb 11, 2025



Recent advances in one-step generative models typically follow a two-stage process: first training a teacher diffusion model and then distilling it into a one-step student model. This distillation process traditionally relies on both the teacher model's score function to compute the distillation loss and its weights for student initialization. In this paper, we explore whether one-step generative models can be trained directly without this distillation process. First, we show that the teacher's score function is not essential and propose a family of distillation methods that achieve competitive results without relying on score estimation. Next, we demonstrate that initialization from teacher weights is indispensable in successful training. Surprisingly, we find that this benefit is not due to improved ``input-output" mapping but rather the learned feature representations, which dominate distillation quality. Our findings provide a better understanding of the role of initialization in one-step model training and its impact on distillation quality.
Training Neural Samplers with Reverse Diffusive KL Divergence
Oct 16, 2024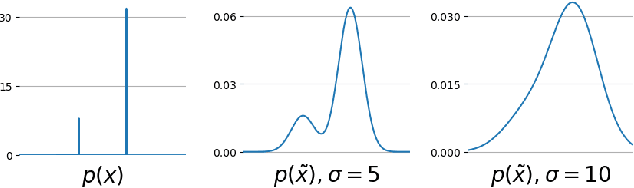



Training generative models to sample from unnormalized density functions is an important and challenging task in machine learning. Traditional training methods often rely on the reverse Kullback-Leibler (KL) divergence due to its tractability. However, the mode-seeking behavior of reverse KL hinders effective approximation of multi-modal target distributions. To address this, we propose to minimize the reverse KL along diffusion trajectories of both model and target densities. We refer to this objective as the reverse diffusive KL divergence, which allows the model to capture multiple modes. Leveraging this objective, we train neural samplers that can efficiently generate samples from the target distribution in one step. We demonstrate that our method enhances sampling performance across various Boltzmann distributions, including both synthetic multi-modal densities and n-body particle systems.
RotRNN: Modelling Long Sequences with Rotations
Jul 09, 2024Linear recurrent models, such as State Space Models (SSMs) and Linear Recurrent Units (LRUs), have recently shown state-of-the-art performance on long sequence modelling benchmarks. Despite their success, they come with a number of drawbacks, most notably their complex initialisation and normalisation schemes. In this work, we address some of these issues by proposing RotRNN -- a linear recurrent model which utilises the convenient properties of rotation matrices. We show that RotRNN provides a simple model with fewer theoretical assumptions than prior works, with a practical implementation that remains faithful to its theoretical derivation, achieving comparable scores to the LRU and SSMs on several long sequence modelling datasets.
Diffusion Model With Optimal Covariance Matching
Jun 16, 2024The probabilistic diffusion model has become highly effective across various domains. Typically, sampling from a diffusion model involves using a denoising distribution characterized by a Gaussian with a learned mean and either fixed or learned covariances. In this paper, we leverage the recently proposed full covariance moment matching technique and introduce a novel method for learning covariances. Unlike traditional data-driven covariance approximation approaches, our method involves directly regressing the optimal analytic covariance using a new, unbiased objective named Optimal Covariance Matching (OCM). This approach can significantly reduce the approximation error in covariance prediction. We demonstrate how our method can substantially enhance the sampling efficiency of both Markovian (DDPM) and non-Markovian (DDIM) diffusion model families.
Latent Attention for Linear Time Transformers
Mar 04, 2024The time complexity of the standard attention mechanism in a transformer scales quadratically with the length of the sequence. We introduce a method to reduce this to linear scaling with time, based on defining attention via latent vectors. The method is readily usable as a drop-in replacement for the standard attention mechanism. Our "Latte Transformer" model can be implemented for both bidirectional and unidirectional tasks, with the causal version allowing a recurrent implementation which is memory and time-efficient during inference of language generation tasks. Whilst next token prediction scales linearly with the sequence length for a standard transformer, a Latte Transformer requires constant time to compute the next token. The empirical performance of our method is comparable to standard attention, yet allows scaling to context windows much larger than practical in standard attention.
Mafin: Enhancing Black-Box Embeddings with Model Augmented Fine-Tuning
Feb 26, 2024



Retrieval Augmented Generation (RAG) has emerged as an effective solution for mitigating hallucinations in Large Language Models (LLMs). The retrieval stage in RAG typically involves a pre-trained embedding model, which converts queries and passages into vectors to capture their semantics. However, a standard pre-trained embedding model may exhibit sub-optimal performance when applied to specific domain knowledge, necessitating fine-tuning. This paper addresses scenarios where the embeddings are only available from a black-box model. We introduce Model augmented fine-tuning (Mafin) -- a novel approach for fine-tuning a black-box embedding model by augmenting it with a trainable embedding model. Our results demonstrate that Mafin significantly enhances the performance of the black-box embeddings by only requiring the training of a small augmented model. We validate the effectiveness of our method on both labeled and unlabeled datasets, illustrating its broad applicability and efficiency.
Active Preference Learning for Large Language Models
Feb 12, 2024As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
Diffusive Gibbs Sampling
Feb 05, 2024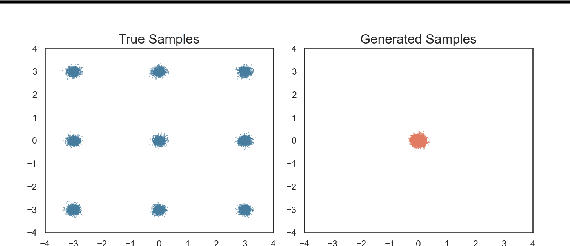
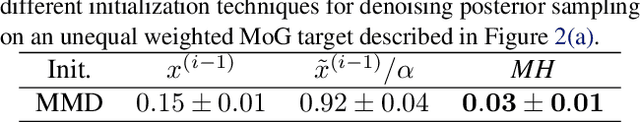
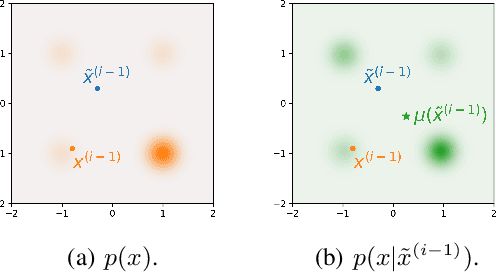

The inadequate mixing of conventional Markov Chain Monte Carlo (MCMC) methods for multi-modal distributions presents a significant challenge in practical applications such as Bayesian inference and molecular dynamics. Addressing this, we propose Diffusive Gibbs Sampling (DiGS), an innovative family of sampling methods designed for effective sampling from distributions characterized by distant and disconnected modes. DiGS integrates recent developments in diffusion models, leveraging Gaussian convolution to create an auxiliary noisy distribution that bridges isolated modes in the original space and applying Gibbs sampling to alternately draw samples from both spaces. Our approach exhibits a better mixing property for sampling multi-modal distributions than state-of-the-art methods such as parallel tempering. We demonstrate that our sampler attains substantially improved results across various tasks, including mixtures of Gaussians, Bayesian neural networks and molecular dynamics.