 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning POMDP World Models from Observations with Language-Model Priors
May 13, 2026Whether navigating a building, operating a robot, or playing a game, an agent that acts effectively in an environment must first learn an internal model of how that environment works. Partially-observable Markov decision processes (POMDPs) provide a flexible modeling class for such internal world models, but learning them from observation-action trajectories alone is challenging and typically requires extensive environment interaction. We ask whether language-model priors can reduce costly interaction by leveraging prior knowledge, and introduce \emph{Pinductor} (POMDP-inductor): an LLM proposes candidate POMDP models from a few observation-action trajectories and iteratively refines them to optimize a belief-based likelihood score. Despite using strictly less information, \emph{Pinductor} matches the performance and sample efficiency of LLM-based POMDP learning methods that assume privileged access to the hidden state, while significantly surpassing the sample efficiency of tabular POMDP baselines. Further results show that performance scales with LLM capability and degrades gracefully as semantic information about the environment is withheld. Together, these results position language-model priors as a practical tool for sample-efficient world-model learning under partial observability, and a step toward generalist agents in real-world environments. Code is available at https://github.com/atomresearch/pinductor.
Flipping Against All Odds: Reducing LLM Coin Flip Bias via Verbalized Rejection Sampling
Jun 11, 2025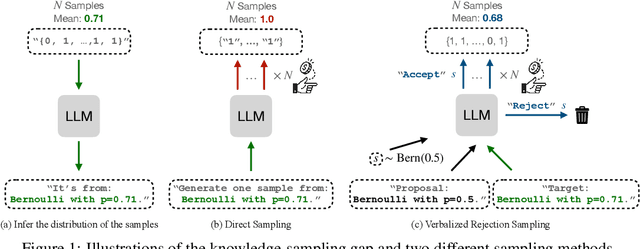


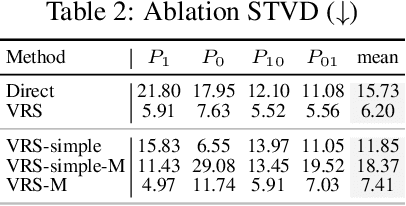
Large language models (LLMs) can often accurately describe probability distributions using natural language, yet they still struggle to generate faithful samples from them. This mismatch limits their use in tasks requiring reliable stochasticity, such as Monte Carlo methods, agent-based simulations, and randomized decision-making. We investigate this gap between knowledge and sampling in the context of Bernoulli distributions. We introduce Verbalized Rejection Sampling (VRS), a natural-language adaptation of classical rejection sampling that prompts the LLM to reason about and accept or reject proposed samples. Despite relying on the same Bernoulli mechanism internally, VRS substantially reduces sampling bias across models. We provide theoretical analysis showing that, under mild assumptions, VRS improves over direct sampling, with gains attributable to both the algorithm and prompt design. More broadly, our results show how classical probabilistic tools can be verbalized and embedded into LLM workflows to improve reliability, without requiring access to model internals or heavy prompt engineering.
Reparameterized LLM Training via Orthogonal Equivalence Transformation
Jun 09, 2025While large language models (LLMs) are driving the rapid advancement of artificial intelligence, effectively and reliably training these large models remains one of the field's most significant challenges. To address this challenge, we propose POET, a novel reParameterized training algorithm that uses Orthogonal Equivalence Transformation to optimize neurons. Specifically, POET reparameterizes each neuron with two learnable orthogonal matrices and a fixed random weight matrix. Because of its provable preservation of spectral properties of weight matrices, POET can stably optimize the objective function with improved generalization. We further develop efficient approximations that make POET flexible and scalable for training large-scale neural networks. Extensive experiments validate the effectiveness and scalability of POET in training LLMs.
Generating Symbolic World Models via Test-time Scaling of Large Language Models
Feb 07, 2025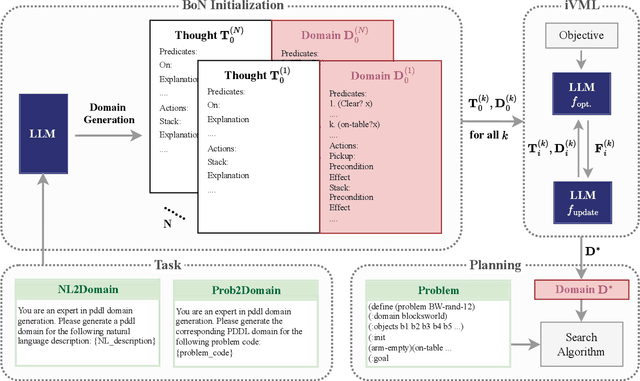

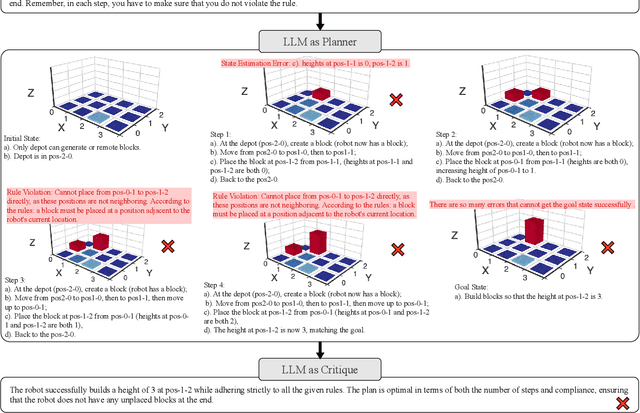
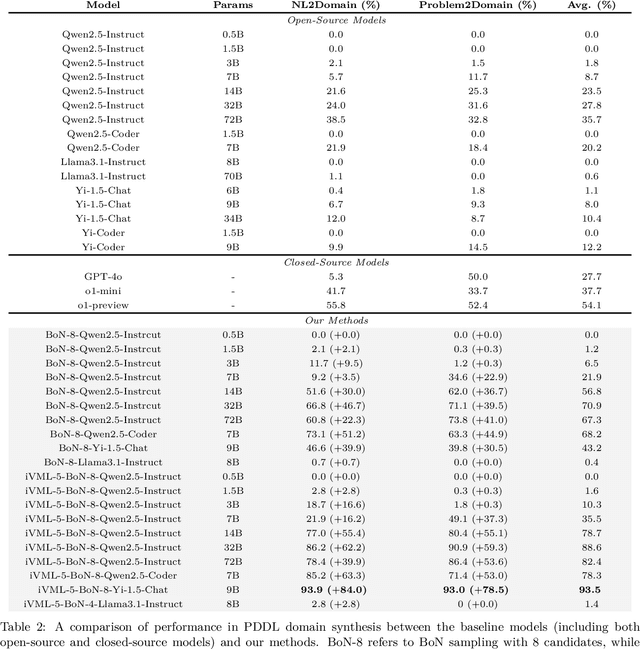
Solving complex planning problems requires Large Language Models (LLMs) to explicitly model the state transition to avoid rule violations, comply with constraints, and ensure optimality-a task hindered by the inherent ambiguity of natural language. To overcome such ambiguity, Planning Domain Definition Language (PDDL) is leveraged as a planning abstraction that enables precise and formal state descriptions. With PDDL, we can generate a symbolic world model where classic searching algorithms, such as A*, can be seamlessly applied to find optimal plans. However, directly generating PDDL domains with current LLMs remains an open challenge due to the lack of PDDL training data. To address this challenge, we propose to scale up the test-time computation of LLMs to enhance their PDDL reasoning capabilities, thereby enabling the generation of high-quality PDDL domains. Specifically, we introduce a simple yet effective algorithm, which first employs a Best-of-N sampling approach to improve the quality of the initial solution and then refines the solution in a fine-grained manner with verbalized machine learning. Our method outperforms o1-mini by a considerable margin in the generation of PDDL domain, achieving over 50% success rate on two tasks (i.e., generating PDDL domains from natural language description or PDDL problems). This is done without requiring additional training. By taking advantage of PDDL as state abstraction, our method is able to outperform current state-of-the-art methods on almost all competition-level planning tasks.
Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
Dec 10, 2024While one commonly trains large diffusion models by collecting datasets on target downstream tasks, it is often desired to align and finetune pretrained diffusion models on some reward functions that are either designed by experts or learned from small-scale datasets. Existing methods for finetuning diffusion models typically suffer from lack of diversity in generated samples, lack of prior preservation, and/or slow convergence in finetuning. Inspired by recent successes in generative flow networks (GFlowNets), a class of probabilistic models that sample with the unnormalized density of a reward function, we propose a novel GFlowNet method dubbed Nabla-GFlowNet (abbreviated as $\nabla$-GFlowNet), the first GFlowNet method that leverages the rich signal in reward gradients, together with an objective called $\nabla$-DB plus its variant residual $\nabla$-DB designed for prior-preserving diffusion alignment. We show that our proposed method achieves fast yet diversity- and prior-preserving alignment of Stable Diffusion, a large-scale text-conditioned image diffusion model, on different realistic reward functions.
Can Large Language Models Understand Symbolic Graphics Programs?
Aug 15, 2024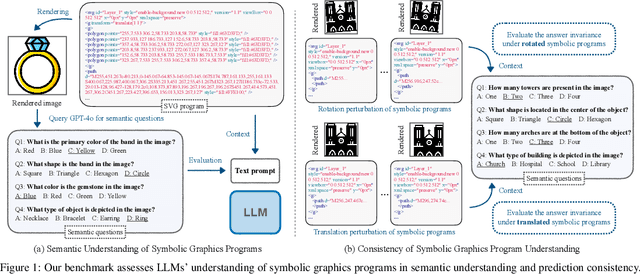

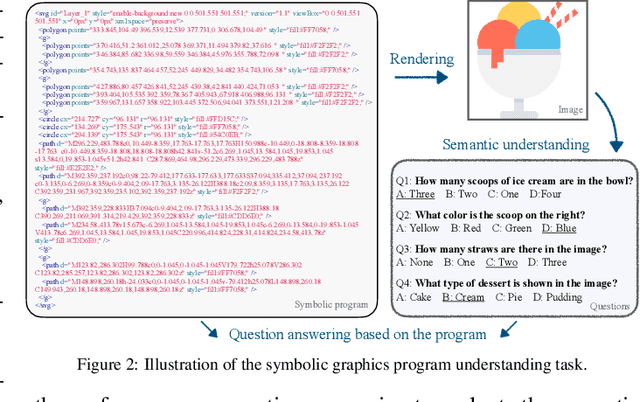
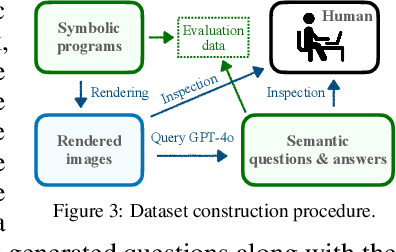
Assessing the capabilities of large language models (LLMs) is often challenging, in part, because it is hard to find tasks to which they have not been exposed during training. We take one step to address this challenge by turning to a new task: focusing on symbolic graphics programs, which are a popular representation for graphics content that procedurally generates visual data. LLMs have shown exciting promise towards program synthesis, but do they understand symbolic graphics programs? Unlike conventional programs, symbolic graphics programs can be translated to graphics content. Here, we characterize an LLM's understanding of symbolic programs in terms of their ability to answer questions related to the graphics content. This task is challenging as the questions are difficult to answer from the symbolic programs alone -- yet, they would be easy to answer from the corresponding graphics content as we verify through a human experiment. To understand symbolic programs, LLMs may need to possess the ability to imagine how the corresponding graphics content would look without directly accessing the rendered visual content. We use this task to evaluate LLMs by creating a large benchmark for the semantic understanding of symbolic graphics programs. This benchmark is built via program-graphics correspondence, hence requiring minimal human efforts. We evaluate current LLMs on our benchmark to elucidate a preliminary assessment of their ability to reason about visual scenes from programs. We find that this task distinguishes existing LLMs and models considered good at reasoning perform better. Lastly, we introduce Symbolic Instruction Tuning (SIT) to improve this ability. Specifically, we query GPT4-o with questions and images generated by symbolic programs. Such data are then used to finetune an LLM. We also find that SIT data can improve the general instruction following ability of LLMs.
Diffusion Model With Optimal Covariance Matching
Jun 16, 2024The probabilistic diffusion model has become highly effective across various domains. Typically, sampling from a diffusion model involves using a denoising distribution characterized by a Gaussian with a learned mean and either fixed or learned covariances. In this paper, we leverage the recently proposed full covariance moment matching technique and introduce a novel method for learning covariances. Unlike traditional data-driven covariance approximation approaches, our method involves directly regressing the optimal analytic covariance using a new, unbiased objective named Optimal Covariance Matching (OCM). This approach can significantly reduce the approximation error in covariance prediction. We demonstrate how our method can substantially enhance the sampling efficiency of both Markovian (DDPM) and non-Markovian (DDIM) diffusion model families.
Verbalized Machine Learning: Revisiting Machine Learning with Language Models
Jun 06, 2024



Motivated by the large progress made by large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical machine learning problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a concrete model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why each learner update is performed. We conduct several studies to empirically evaluate the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability and trustworthiness in ML.
Your Finetuned Large Language Model is Already a Powerful Out-of-distribution Detector
Apr 07, 2024
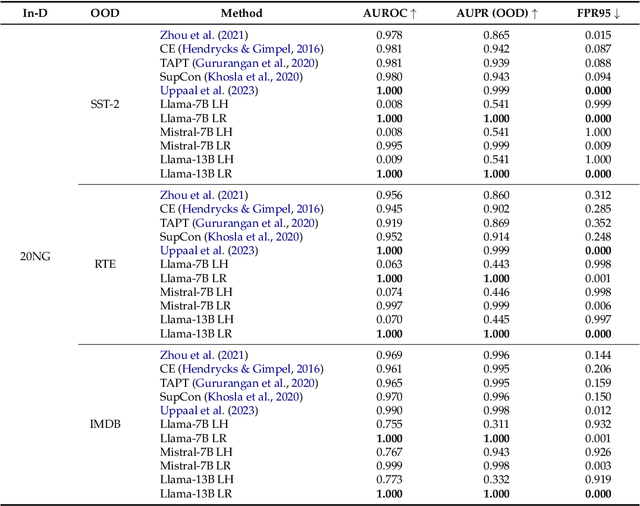
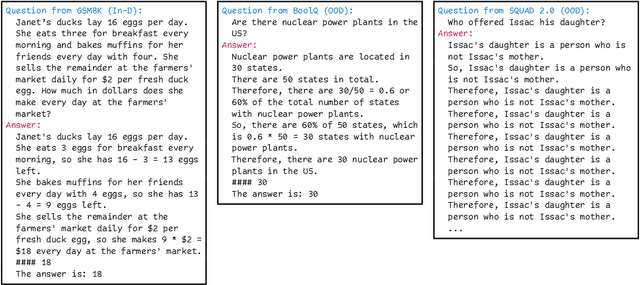
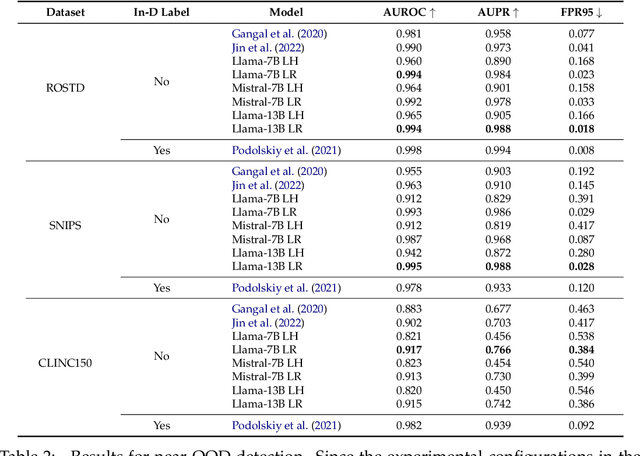
We revisit the likelihood ratio between a pretrained large language model (LLM) and its finetuned variant as a criterion for out-of-distribution (OOD) detection. The intuition behind such a criterion is that, the pretrained LLM has the prior knowledge about OOD data due to its large amount of training data, and once finetuned with the in-distribution data, the LLM has sufficient knowledge to distinguish their difference. Leveraging the power of LLMs, we show that, for the first time, the likelihood ratio can serve as an effective OOD detector. Moreover, we apply the proposed LLM-based likelihood ratio to detect OOD questions in question-answering (QA) systems, which can be used to improve the performance of specialized LLMs for general questions. Given that likelihood can be easily obtained by the loss functions within contemporary neural network frameworks, it is straightforward to implement this approach in practice. Since both the pretrained LLMs and its various finetuned models are available, our proposed criterion can be effortlessly incorporated for OOD detection without the need for further training. We conduct comprehensive evaluation across on multiple settings, including far OOD, near OOD, spam detection, and QA scenarios, to demonstrate the effectiveness of the method.
A Compact Representation for Bayesian Neural Networks By Removing Permutation Symmetry
Dec 31, 2023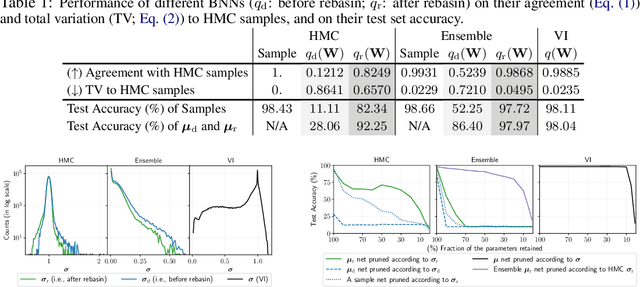
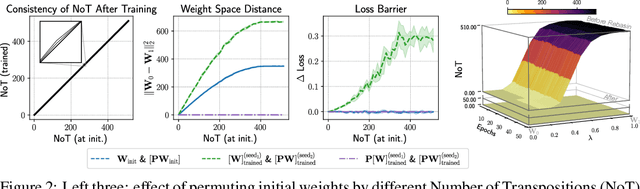
Bayesian neural networks (BNNs) are a principled approach to modeling predictive uncertainties in deep learning, which are important in safety-critical applications. Since exact Bayesian inference over the weights in a BNN is intractable, various approximate inference methods exist, among which sampling methods such as Hamiltonian Monte Carlo (HMC) are often considered the gold standard. While HMC provides high-quality samples, it lacks interpretable summary statistics because its sample mean and variance is meaningless in neural networks due to permutation symmetry. In this paper, we first show that the role of permutations can be meaningfully quantified by a number of transpositions metric. We then show that the recently proposed rebasin method allows us to summarize HMC samples into a compact representation that provides a meaningful explicit uncertainty estimate for each weight in a neural network, thus unifying sampling methods with variational inference. We show that this compact representation allows us to compare trained BNNs directly in weight space across sampling methods and variational inference, and to efficiently prune neural networks trained without explicit Bayesian frameworks by exploiting uncertainty estimates from HMC.