 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePion: A Spectrum-Preserving Optimizer via Orthogonal Equivalence Transformation
May 12, 2026We introduce Pion, a spectrum-preserving optimizer for large language model (LLM) training based on orthogonal equivalence transformation. Unlike additive optimizers such as Adam and Muon, Pion updates each weight matrix through left and right orthogonal transformations, preserving its singular values throughout training. This yields an optimization mechanism that modulates the geometry of weight matrices while keeping their spectral norm fixed. We derive the Pion update rule, systematically examine its design choices, and analyze its convergence behavior along with several key properties. Empirical results show that Pion offers a stable and competitive alternative to standard optimizers for both LLM pretraining and finetuning.
Logit Distance Bounds Representational Similarity
Feb 17, 2026For a broad family of discriminative models that includes autoregressive language models, identifiability results imply that if two models induce the same conditional distributions, then their internal representations agree up to an invertible linear transformation. We ask whether an analogous conclusion holds approximately when the distributions are close instead of equal. Building on the observation of Nielsen et al. (2025) that closeness in KL divergence need not imply high linear representational similarity, we study a distributional distance based on logit differences and show that closeness in this distance does yield linear similarity guarantees. Specifically, we define a representational dissimilarity measure based on the models' identifiability class and prove that it is bounded by the logit distance. We further show that, when model probabilities are bounded away from zero, KL divergence upper-bounds logit distance; yet the resulting bound fails to provide nontrivial control in practice. As a consequence, KL-based distillation can match a teacher's predictions while failing to preserve linear representational properties, such as linear-probe recoverability of human-interpretable concepts. In distillation experiments on synthetic and image datasets, logit-distance distillation yields students with higher linear representational similarity and better preservation of the teacher's linearly recoverable concepts.
Generation is Required for Data-Efficient Perception
Dec 17, 2025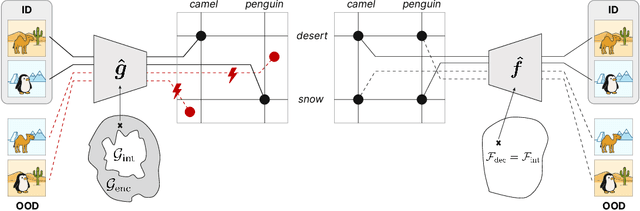
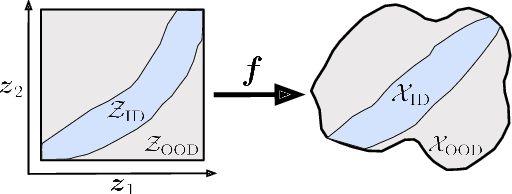
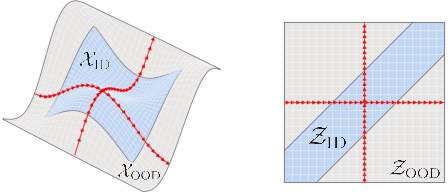
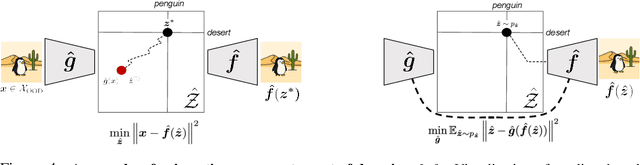
It has been hypothesized that human-level visual perception requires a generative approach in which internal representations result from inverting a decoder. Yet today's most successful vision models are non-generative, relying on an encoder that maps images to representations without decoder inversion. This raises the question of whether generation is, in fact, necessary for machines to achieve human-level visual perception. To address this, we study whether generative and non-generative methods can achieve compositional generalization, a hallmark of human perception. Under a compositional data generating process, we formalize the inductive biases required to guarantee compositional generalization in decoder-based (generative) and encoder-based (non-generative) methods. We then show theoretically that enforcing these inductive biases on encoders is generally infeasible using regularization or architectural constraints. In contrast, for generative methods, the inductive biases can be enforced straightforwardly, thereby enabling compositional generalization by constraining a decoder and inverting it. We highlight how this inversion can be performed efficiently, either online through gradient-based search or offline through generative replay. We examine the empirical implications of our theory by training a range of generative and non-generative methods on photorealistic image datasets. We find that, without the necessary inductive biases, non-generative methods often fail to generalize compositionally and require large-scale pretraining or added supervision to improve generalization. By comparison, generative methods yield significant improvements in compositional generalization, without requiring additional data, by leveraging suitable inductive biases on a decoder along with search and replay.
Reparameterized LLM Training via Orthogonal Equivalence Transformation
Jun 09, 2025While large language models (LLMs) are driving the rapid advancement of artificial intelligence, effectively and reliably training these large models remains one of the field's most significant challenges. To address this challenge, we propose POET, a novel reParameterized training algorithm that uses Orthogonal Equivalence Transformation to optimize neurons. Specifically, POET reparameterizes each neuron with two learnable orthogonal matrices and a fixed random weight matrix. Because of its provable preservation of spectral properties of weight matrices, POET can stably optimize the objective function with improved generalization. We further develop efficient approximations that make POET flexible and scalable for training large-scale neural networks. Extensive experiments validate the effectiveness and scalability of POET in training LLMs.
Robustness of Nonlinear Representation Learning
Mar 19, 2025We study the problem of unsupervised representation learning in slightly misspecified settings, and thus formalize the study of robustness of nonlinear representation learning. We focus on the case where the mixing is close to a local isometry in a suitable distance and show based on existing rigidity results that the mixing can be identified up to linear transformations and small errors. In a second step, we investigate Independent Component Analysis (ICA) with observations generated according to $x=f(s)=As+h(s)$ where $A$ is an invertible mixing matrix and $h$ a small perturbation. We show that we can approximately recover the matrix $A$ and the independent components. Together, these two results show approximate identifiability of nonlinear ICA with almost isometric mixing functions. Those results are a step towards identifiability results for unsupervised representation learning for real-world data that do not follow restrictive model classes.
* 37 pages
Algorithmic causal structure emerging through compression
Feb 06, 2025



We explore the relationship between causality, symmetry, and compression. We build on and generalize the known connection between learning and compression to a setting where causal models are not identifiable. We propose a framework where causality emerges as a consequence of compressing data across multiple environments. We define algorithmic causality as an alternative definition of causality when traditional assumptions for causal identifiability do not hold. We demonstrate how algorithmic causal and symmetric structures can emerge from minimizing upper bounds on Kolmogorov complexity, without knowledge of intervention targets. We hypothesize that these insights may also provide a novel perspective on the emergence of causality in machine learning models, such as large language models, where causal relationships may not be explicitly identifiable.
Interaction Asymmetry: A General Principle for Learning Composable Abstractions
Nov 12, 2024Learning disentangled representations of concepts and re-composing them in unseen ways is crucial for generalizing to out-of-domain situations. However, the underlying properties of concepts that enable such disentanglement and compositional generalization remain poorly understood. In this work, we propose the principle of interaction asymmetry which states: "Parts of the same concept have more complex interactions than parts of different concepts". We formalize this via block diagonality conditions on the $(n+1)$th order derivatives of the generator mapping concepts to observed data, where different orders of "complexity" correspond to different $n$. Using this formalism, we prove that interaction asymmetry enables both disentanglement and compositional generalization. Our results unify recent theoretical results for learning concepts of objects, which we show are recovered as special cases with $n\!=\!0$ or $1$. We provide results for up to $n\!=\!2$, thus extending these prior works to more flexible generator functions, and conjecture that the same proof strategies generalize to larger $n$. Practically, our theory suggests that, to disentangle concepts, an autoencoder should penalize its latent capacity and the interactions between concepts during decoding. We propose an implementation of these criteria using a flexible Transformer-based VAE, with a novel regularizer on the attention weights of the decoder. On synthetic image datasets consisting of objects, we provide evidence that this model can achieve comparable object disentanglement to existing models that use more explicit object-centric priors.
Learning Interpretable Concepts: Unifying Causal Representation Learning and Foundation Models
Feb 14, 2024To build intelligent machine learning systems, there are two broad approaches. One approach is to build inherently interpretable models, as endeavored by the growing field of causal representation learning. The other approach is to build highly-performant foundation models and then invest efforts into understanding how they work. In this work, we relate these two approaches and study how to learn human-interpretable concepts from data. Weaving together ideas from both fields, we formally define a notion of concepts and show that they can be provably recovered from diverse data. Experiments on synthetic data and large language models show the utility of our unified approach.
Learning Linear Causal Representations from Interventions under General Nonlinear Mixing
Jun 04, 2023



We study the problem of learning causal representations from unknown, latent interventions in a general setting, where the latent distribution is Gaussian but the mixing function is completely general. We prove strong identifiability results given unknown single-node interventions, i.e., without having access to the intervention targets. This generalizes prior works which have focused on weaker classes, such as linear maps or paired counterfactual data. This is also the first instance of causal identifiability from non-paired interventions for deep neural network embeddings. Our proof relies on carefully uncovering the high-dimensional geometric structure present in the data distribution after a non-linear density transformation, which we capture by analyzing quadratic forms of precision matrices of the latent distributions. Finally, we propose a contrastive algorithm to identify the latent variables in practice and evaluate its performance on various tasks.
Flow Matching for Scalable Simulation-Based Inference
May 26, 2023Neural posterior estimation methods based on discrete normalizing flows have become established tools for simulation-based inference (SBI), but scaling them to high-dimensional problems can be challenging. Building on recent advances in generative modeling, we here present flow matching posterior estimation (FMPE), a technique for SBI using continuous normalizing flows. Like diffusion models, and in contrast to discrete flows, flow matching allows for unconstrained architectures, providing enhanced flexibility for complex data modalities. Flow matching, therefore, enables exact density evaluation, fast training, and seamless scalability to large architectures--making it ideal for SBI. We show that FMPE achieves competitive performance on an established SBI benchmark, and then demonstrate its improved scalability on a challenging scientific problem: for gravitational-wave inference, FMPE outperforms methods based on comparable discrete flows, reducing training time by 30% with substantially improved accuracy. Our work underscores the potential of FMPE to enhance performance in challenging inference scenarios, thereby paving the way for more advanced applications to scientific problems.