 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Identifiability of Causal Representations from Unknown Interventions
Jun 01, 2023We study causal representation learning, the task of inferring latent causal variables and their causal relations from high-dimensional functions ("mixtures") of the variables. Prior work relies on weak supervision, in the form of counterfactual pre- and post-intervention views or temporal structure; places restrictive assumptions, such as linearity, on the mixing function or latent causal model; or requires partial knowledge of the generative process, such as the causal graph or the intervention targets. We instead consider the general setting in which both the causal model and the mixing function are nonparametric. The learning signal takes the form of multiple datasets, or environments, arising from unknown interventions in the underlying causal model. Our goal is to identify both the ground truth latents and their causal graph up to a set of ambiguities which we show to be irresolvable from interventional data. We study the fundamental setting of two causal variables and prove that the observational distribution and one perfect intervention per node suffice for identifiability, subject to a genericity condition. This condition rules out spurious solutions that involve fine-tuning of the intervened and observational distributions, mirroring similar conditions for nonlinear cause-effect inference. For an arbitrary number of variables, we show that two distinct paired perfect interventions per node guarantee identifiability. Further, we demonstrate that the strengths of causal influences among the latent variables are preserved by all equivalent solutions, rendering the inferred representation appropriate for drawing causal conclusions from new data. Our study provides the first identifiability results for the general nonparametric setting with unknown interventions, and elucidates what is possible and impossible for causal representation learning without more direct supervision.
Causal Component Analysis
May 26, 2023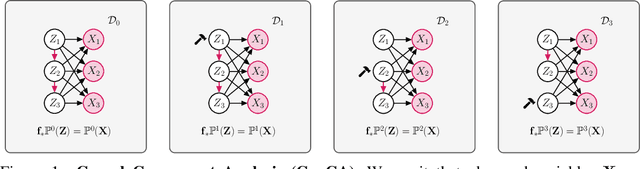


Independent Component Analysis (ICA) aims to recover independent latent variables from observed mixtures thereof. Causal Representation Learning (CRL) aims instead to infer causally related (thus often statistically dependent) latent variables, together with the unknown graph encoding their causal relationships. We introduce an intermediate problem termed Causal Component Analysis (CauCA). CauCA can be viewed as a generalization of ICA, modelling the causal dependence among the latent components, and as a special case of CRL. In contrast to CRL, it presupposes knowledge of the causal graph, focusing solely on learning the unmixing function and the causal mechanisms. Any impossibility results regarding the recovery of the ground truth in CauCA also apply for CRL, while possibility results may serve as a stepping stone for extensions to CRL. We characterize CauCA identifiability from multiple datasets generated through different types of interventions on the latent causal variables. As a corollary, this interventional perspective also leads to new identifiability results for nonlinear ICA -- a special case of CauCA with an empty graph -- requiring strictly fewer datasets than previous results. We introduce a likelihood-based approach using normalizing flows to estimate both the unmixing function and the causal mechanisms, and demonstrate its effectiveness through extensive synthetic experiments in the CauCA and ICA setting.