 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Vision and Vision-motion Calibration Strategies for PointGoal Navigation in Indoor Environment
Oct 02, 2022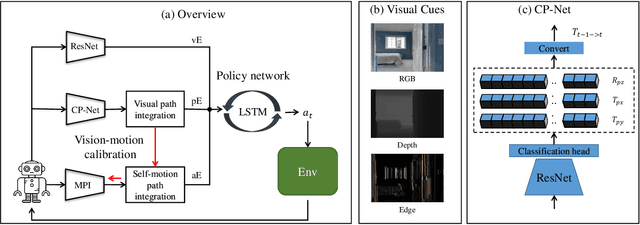
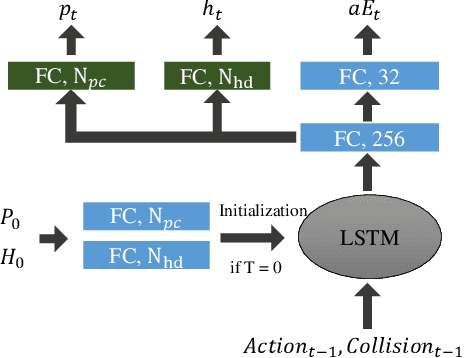
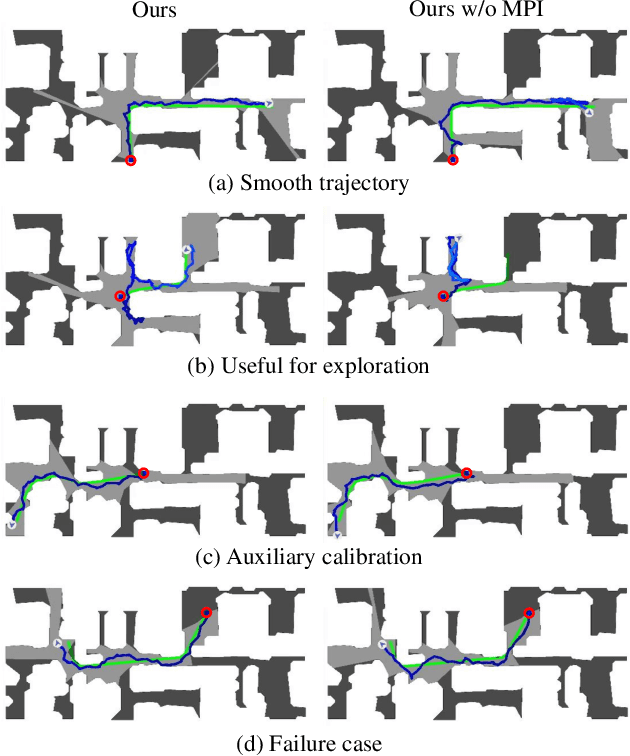
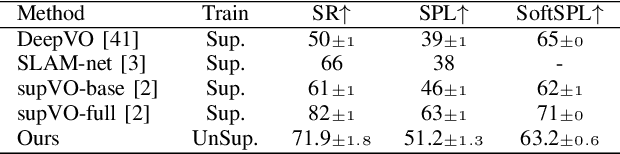
PointGoal navigation in indoor environment is a fundamental task for personal robots to navigate to a specified point. Recent studies solved this PointGoal navigation task with near-perfect success rate in photo-realistically simulated environments, under the assumptions with noiseless actuation and most importantly, perfect localization with GPS and compass sensors. However, accurate GPS signal can not be obtained in real indoor environment. To improve the pointgoal navigation accuracy in real indoor, we proposed novel vision and vision-motion calibration strategies to train visual and motion path integration in unsupervised manner. Sepecifically, visual calibration computes the relative pose of the agent from the re-projection error of two adjacent frames, and then replaces the accurate GPS signal with the path integration. This pseudo position is also used to calibrate self-motion integration which assists agent to update their internal perception of location and helps improve the success rate of navigation. The training and inference process only use RGB, depth, collision as well as self-action information. The experiments show that the proposed system achieves satisfactory results and outperforms the partially supervised learning algorithms on the popular Gibson dataset.
Deep Pneumonia: Attention-Based Contrastive Learning for Class-Imbalanced Pneumonia Lesion Recognition in Chest X-rays
Jul 23, 2022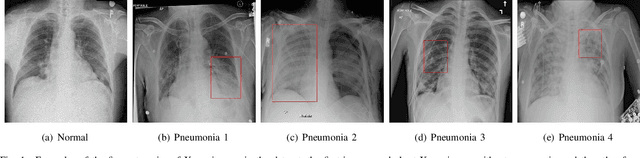
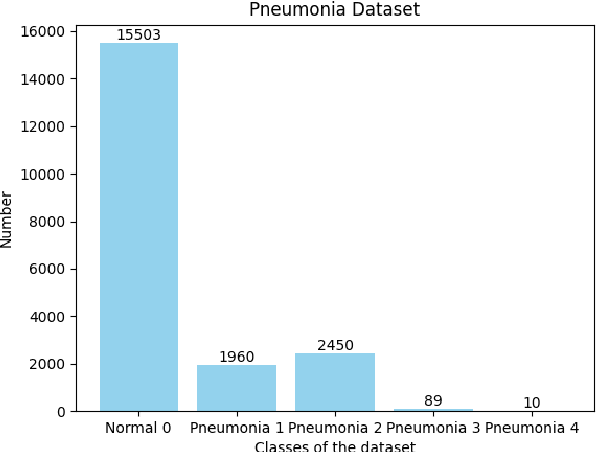
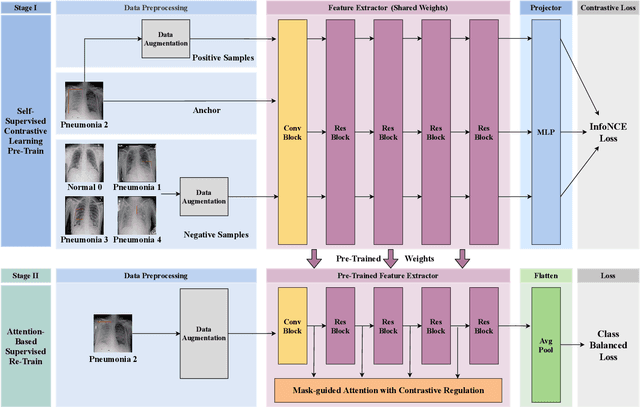
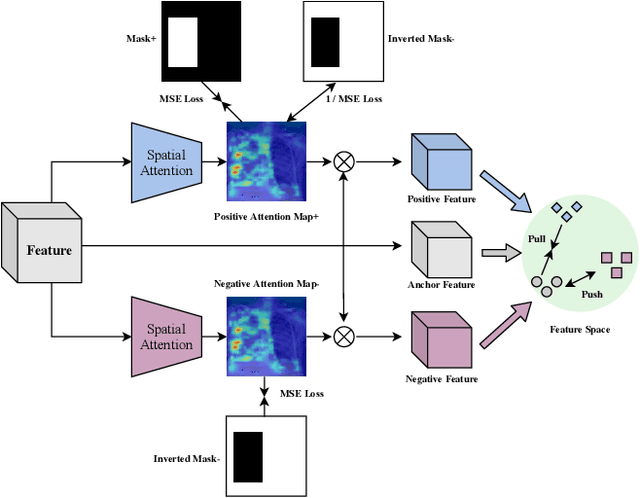
Computer-aided X-ray pneumonia lesion recognition is important for accurate diagnosis of pneumonia. With the emergence of deep learning, the identification accuracy of pneumonia has been greatly improved, but there are still some challenges due to the fuzzy appearance of chest X-rays. In this paper, we propose a deep learning framework named Attention-Based Contrastive Learning for Class-Imbalanced X-Ray Pneumonia Lesion Recognition (denoted as Deep Pneumonia). We adopt self-supervised contrastive learning strategy to pre-train the model without using extra pneumonia data for fully mining the limited available dataset. In order to leverage the location information of the lesion area that the doctor has painstakingly marked, we propose mask-guided hard attention strategy and feature learning with contrastive regulation strategy which are applied on the attention map and the extracted features respectively to guide the model to focus more attention on the lesion area where contains more discriminative features for improving the recognition performance. In addition, we adopt Class-Balanced Loss instead of traditional Cross-Entropy as the loss function of classification to tackle the problem of serious class imbalance between different classes of pneumonia in the dataset. The experimental results show that our proposed framework can be used as a reliable computer-aided pneumonia diagnosis system to assist doctors to better diagnose pneumonia cases accurately.
Robust Visual Odometry Using Position-Aware Flow and Geometric Bundle Adjustment
Nov 22, 2021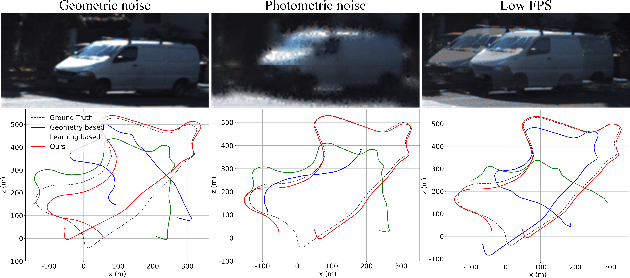



In this paper, an essential problem of robust visual odometry (VO) is approached by incorporating geometry-based methods into deep-learning architecture in a self-supervised manner. Generally, pure geometry-based algorithms are not as robust as deep learning in feature-point extraction and matching, but perform well in ego-motion estimation because of their well-established geometric theory. In this work, a novel optical flow network (PANet) built on a position-aware mechanism is proposed first. Then, a novel system that jointly estimates depth, optical flow, and ego-motion without a typical network to learning ego-motion is proposed. The key component of the proposed system is an improved bundle adjustment module containing multiple sampling, initialization of ego-motion, dynamic damping factor adjustment, and Jacobi matrix weighting. In addition, a novel relative photometric loss function is advanced to improve the depth estimation accuracy. The experiments show that the proposed system not only outperforms other state-of-the-art methods in terms of depth, flow, and VO estimation among self-supervised learning-based methods on KITTI dataset, but also significantly improves robustness compared with geometry-based, learning-based and hybrid VO systems. Further experiments show that our model achieves outstanding generalization ability and performance in challenging indoor (TMU-RGBD) and outdoor (KAIST) scenes.
TSN-CA: A Two-Stage Network with Channel Attention for Low-Light Image Enhancement
Oct 06, 2021



Low-light image enhancement is a challenging low-level computer vision task because after we enhance the brightness of the image, we have to deal with amplified noise, color distortion, detail loss, blurred edges, shadow blocks and halo artifacts. In this paper, we propose a Two-Stage Network with Channel Attention (denoted as TSN-CA) to enhance the brightness of the low-light image and restore the enhanced images from various kinds of degradation. In the first stage, we enhance the brightness of the low-light image in HSV space and use the information of H and S channels to help the recovery of details in V channel. In the second stage, we integrate Channel Attention (CA) mechanism into the skip connection of U-Net in order to restore the brightness-enhanced image from severe kinds of degradation in RGB space. We train and evaluate the performance of our proposed model on the LOL real-world and synthetic datasets. In addition, we test our model on several other commonly used datasets without Ground-Truth. We conduct extensive experiments to demonstrate that our method achieves excellent effect on brightness enhancement as well as denoising, details preservation and halo artifacts elimination. Our method outperforms many other state-of-the-art methods qualitatively and quantitatively.
DA-DRN: Degradation-Aware Deep Retinex Network for Low-Light Image Enhancement
Oct 05, 2021
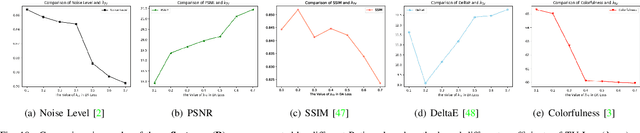

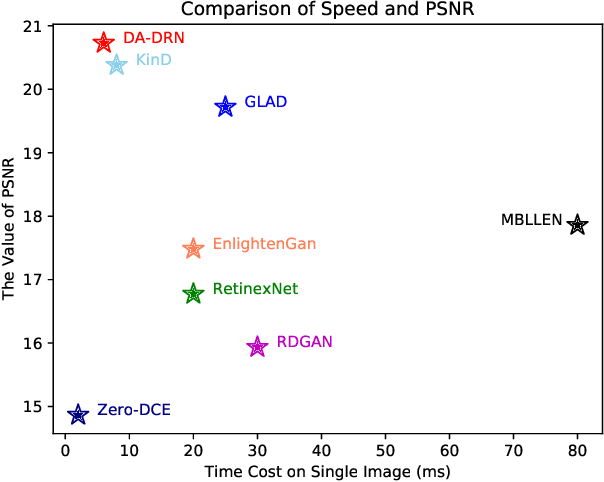
Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color distortion, unknown noise, detail loss and halo artifacts. In this paper, we propose a Degradation-Aware Deep Retinex Network (denoted as DA-DRN) for low-light image enhancement and tackle the above degradation. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination maps and deal with the degradation in the reflectance during the decomposition phase directly. We propose a Degradation-Aware Module (DA Module) which can guide the training process of the decomposer and enable the decomposer to be a restorer during the training phase without additional computational cost in the test phase. DA Module can achieve the purpose of noise removal while preserving detail information into the illumination map as well as tackle color distortion and halo artifacts. We introduce Perceptual Loss to train the enhancement network to generate the brightness-improved illumination maps which are more consistent with human visual perception. We train and evaluate the performance of our proposed model over the LOL real-world and LOL synthetic datasets, and we also test our model over several other frequently used datasets without Ground-Truth (LIME, DICM, MEF and NPE datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method only takes 7 ms to process an image with 600x400 resolution on a TITAN Xp GPU.
BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration
Jun 30, 2021

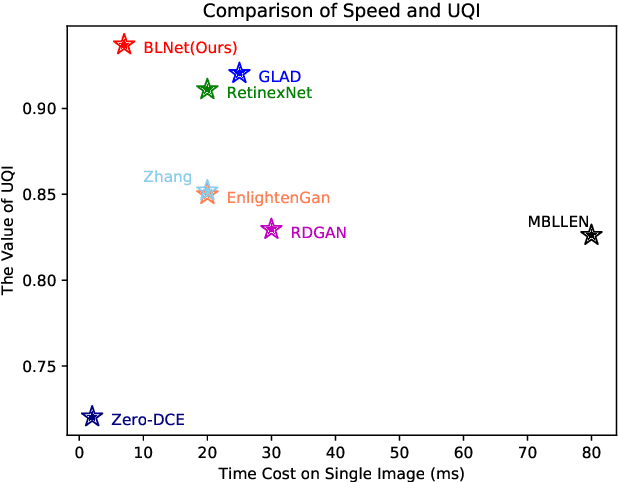

Images obtained in real-world low-light conditions are not only low in brightness, but they also suffer from many other types of degradation, such as color bias, unknown noise, detail loss and halo artifacts. In this paper, we propose a very fast deep learning framework called Bringing the Lightness (denoted as BLNet) that consists of two U-Nets with a series of well-designed loss functions to tackle all of the above degradations. Based on Retinex Theory, the decomposition net in our model can decompose low-light images into reflectance and illumination and remove noise in the reflectance during the decomposition phase. We propose a Noise and Color Bias Control module (NCBC Module) that contains a convolutional neural network and two loss functions (noise loss and color loss). This module is only used to calculate the loss functions during the training phase, so our method is very fast during the test phase. This module can smooth the reflectance to achieve the purpose of noise removal while preserving details and edge information and controlling color bias. We propose a network that can be trained to learn the mapping between low-light and normal-light illumination and enhance the brightness of images taken in low-light illumination. We train and evaluate the performance of our proposed model over the real-world Low-Light (LOL) dataset), and we also test our model over several other frequently used datasets (LIME, DICM and MEF datasets). We conduct extensive experiments to demonstrate that our approach achieves a promising effect with good rubustness and generalization and outperforms many other state-of-the-art methods qualitatively and quantitatively. Our method achieves high speed because we use loss functions instead of introducing additional denoisers for noise removal and color correction. The code and model are available at https://github.com/weixinxu666/BLNet.