 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Better SSIM Loss for Unsupervised Monocular Depth Estimation
Jun 05, 2025Unsupervised monocular depth learning generally relies on the photometric relation among temporally adjacent images. Most of previous works use both mean absolute error (MAE) and structure similarity index measure (SSIM) with conventional form as training loss. However, they ignore the effect of different components in the SSIM function and the corresponding hyperparameters on the training. To address these issues, this work proposes a new form of SSIM. Compared with original SSIM function, the proposed new form uses addition rather than multiplication to combine the luminance, contrast, and structural similarity related components in SSIM. The loss function constructed with this scheme helps result in smoother gradients and achieve higher performance on unsupervised depth estimation. We conduct extensive experiments to determine the relatively optimal combination of parameters for our new SSIM. Based on the popular MonoDepth approach, the optimized SSIM loss function can remarkably outperform the baseline on the KITTI-2015 outdoor dataset.
* 12 pages,4 figures
Unsupervised Vision and Vision-motion Calibration Strategies for PointGoal Navigation in Indoor Environment
Oct 02, 2022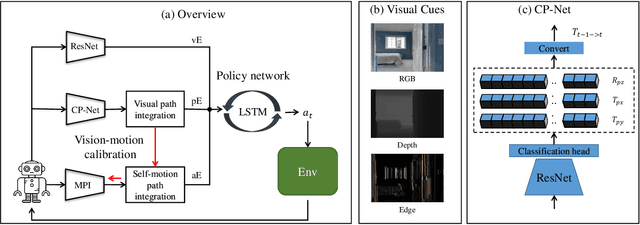
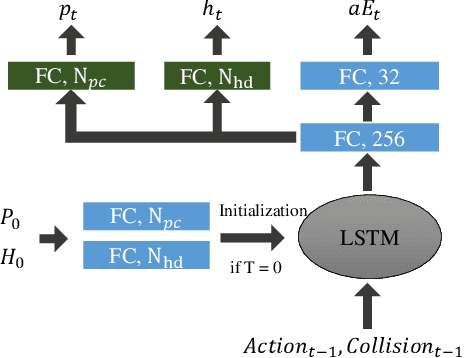
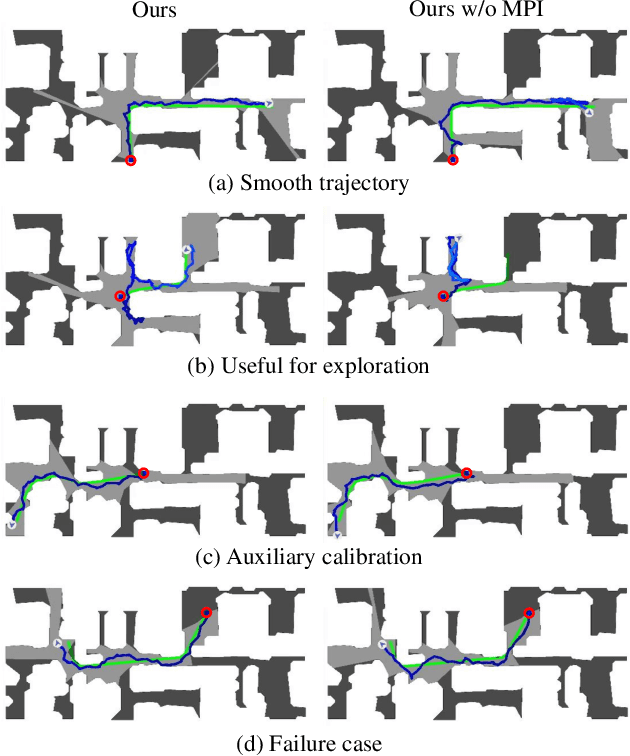
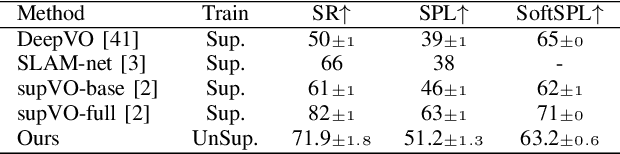
PointGoal navigation in indoor environment is a fundamental task for personal robots to navigate to a specified point. Recent studies solved this PointGoal navigation task with near-perfect success rate in photo-realistically simulated environments, under the assumptions with noiseless actuation and most importantly, perfect localization with GPS and compass sensors. However, accurate GPS signal can not be obtained in real indoor environment. To improve the pointgoal navigation accuracy in real indoor, we proposed novel vision and vision-motion calibration strategies to train visual and motion path integration in unsupervised manner. Sepecifically, visual calibration computes the relative pose of the agent from the re-projection error of two adjacent frames, and then replaces the accurate GPS signal with the path integration. This pseudo position is also used to calibrate self-motion integration which assists agent to update their internal perception of location and helps improve the success rate of navigation. The training and inference process only use RGB, depth, collision as well as self-action information. The experiments show that the proposed system achieves satisfactory results and outperforms the partially supervised learning algorithms on the popular Gibson dataset.
Robust Visual Odometry Using Position-Aware Flow and Geometric Bundle Adjustment
Nov 22, 2021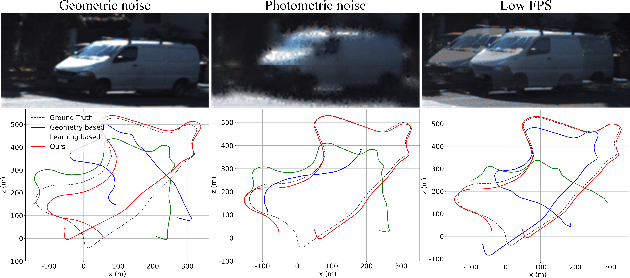



In this paper, an essential problem of robust visual odometry (VO) is approached by incorporating geometry-based methods into deep-learning architecture in a self-supervised manner. Generally, pure geometry-based algorithms are not as robust as deep learning in feature-point extraction and matching, but perform well in ego-motion estimation because of their well-established geometric theory. In this work, a novel optical flow network (PANet) built on a position-aware mechanism is proposed first. Then, a novel system that jointly estimates depth, optical flow, and ego-motion without a typical network to learning ego-motion is proposed. The key component of the proposed system is an improved bundle adjustment module containing multiple sampling, initialization of ego-motion, dynamic damping factor adjustment, and Jacobi matrix weighting. In addition, a novel relative photometric loss function is advanced to improve the depth estimation accuracy. The experiments show that the proposed system not only outperforms other state-of-the-art methods in terms of depth, flow, and VO estimation among self-supervised learning-based methods on KITTI dataset, but also significantly improves robustness compared with geometry-based, learning-based and hybrid VO systems. Further experiments show that our model achieves outstanding generalization ability and performance in challenging indoor (TMU-RGBD) and outdoor (KAIST) scenes.
Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention
Apr 29, 2021


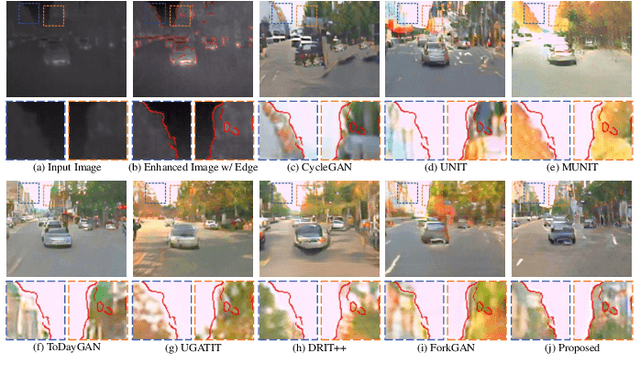
Benefitting from insensitivity to light and high penetration of foggy environments, infrared cameras are widely used for sensing in nighttime traffic scenes. However, the low contrast and lack of chromaticity of thermal infrared (TIR) images hinder the human interpretation and portability of high-level computer vision algorithms. Colorization to translate a nighttime TIR image into a daytime color (NTIR2DC) image may be a promising way to facilitate nighttime scene perception. Despite recent impressive advances in image translation, semantic encoding entanglement and geometric distortion in the NTIR2DC task remain under-addressed. Hence, we propose a toP-down attEntion And gRadient aLignment based GAN, referred to as PearlGAN. A top-down guided attention module and an elaborate attentional loss are first designed to reduce the semantic encoding ambiguity during translation. Then, a structured gradient alignment loss is introduced to encourage edge consistency between the translated and input images. In addition, pixel-level annotation is carried out on a subset of FLIR and KAIST datasets to evaluate the semantic preservation performance of multiple translation methods. Furthermore, a new metric is devised to evaluate the geometric consistency in the translation process. Extensive experiments demonstrate the superiority of the proposed PearlGAN over other image translation methods for the NTIR2DC task. The source code and labeled segmentation masks will be available at \url{https://github.com/FuyaLuo/PearlGAN/}.