 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPBSD:Vessel-Pattern-Based Semi-Supervised Distillation for Efficient 3D Microscopic Cerebrovascular Segmentation
Nov 14, 2024



3D microscopic cerebrovascular images are characterized by their high resolution, presenting significant annotation challenges, large data volumes, and intricate variations in detail. Together, these factors make achieving high-quality, efficient whole-brain segmentation particularly demanding. In this paper, we propose a novel Vessel-Pattern-Based Semi-Supervised Distillation pipeline (VpbSD) to address the challenges of 3D microscopic cerebrovascular segmentation. This pipeline initially constructs a vessel-pattern codebook that captures diverse vascular structures from unlabeled data during the teacher model's pretraining phase. In the knowledge distillation stage, the codebook facilitates the transfer of rich knowledge from a heterogeneous teacher model to a student model, while the semi-supervised approach further enhances the student model's exposure to diverse learning samples. Experimental results on real-world data, including comparisons with state-of-the-art methods and ablation studies, demonstrate that our pipeline and its individual components effectively address the challenges inherent in microscopic cerebrovascular segmentation.
Retinal Vessel Segmentation with Deep Graph and Capsule Reasoning
Sep 17, 2024
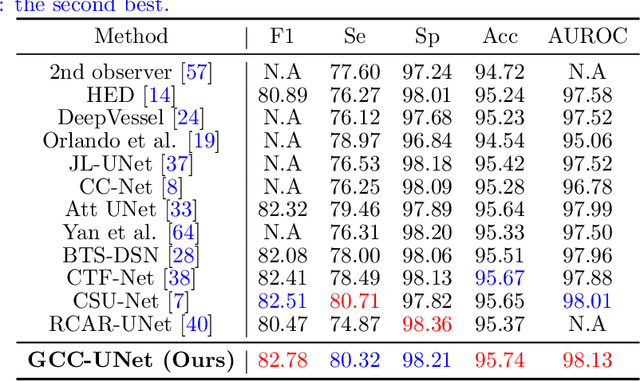

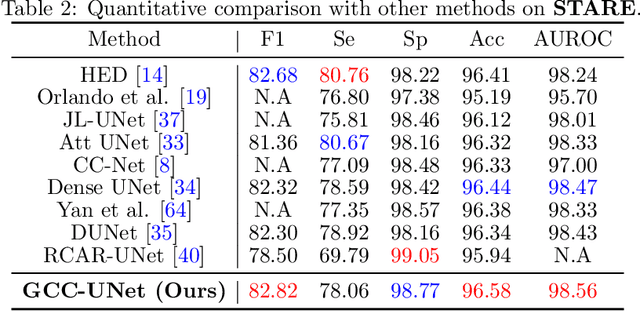
Effective retinal vessel segmentation requires a sophisticated integration of global contextual awareness and local vessel continuity. To address this challenge, we propose the Graph Capsule Convolution Network (GCC-UNet), which merges capsule convolutions with CNNs to capture both local and global features. The Graph Capsule Convolution operator is specifically designed to enhance the representation of global context, while the Selective Graph Attention Fusion module ensures seamless integration of local and global information. To further improve vessel continuity, we introduce the Bottleneck Graph Attention module, which incorporates Channel-wise and Spatial Graph Attention mechanisms. The Multi-Scale Graph Fusion module adeptly combines features from various scales. Our approach has been rigorously validated through experiments on widely used public datasets, with ablation studies confirming the efficacy of each component. Comparative results highlight GCC-UNet's superior performance over existing methods, setting a new benchmark in retinal vessel segmentation. Notably, this work represents the first integration of vanilla, graph, and capsule convolutional techniques in the domain of medical image segmentation.
Rethinking the Detection Head Configuration for Traffic Object Detection
Oct 08, 2022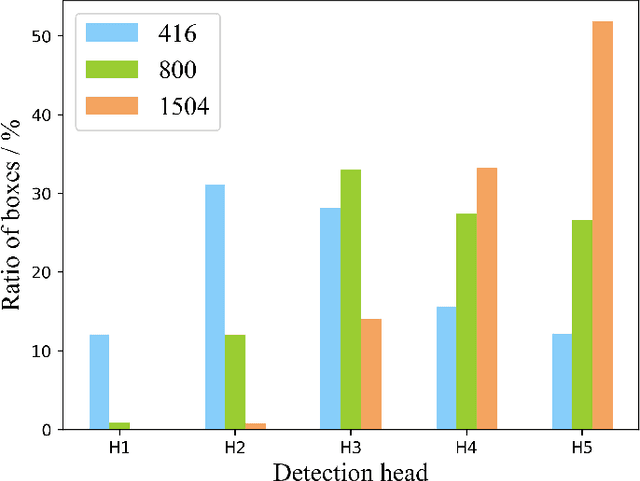
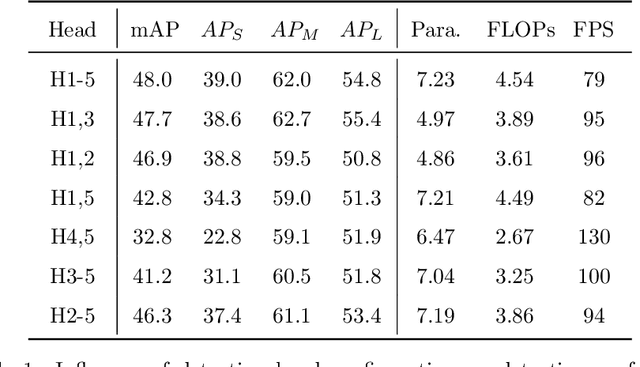
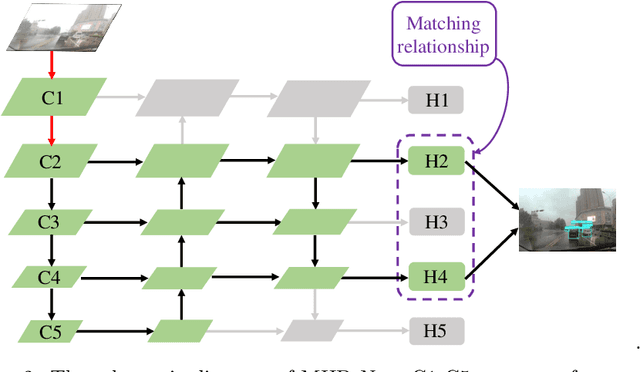
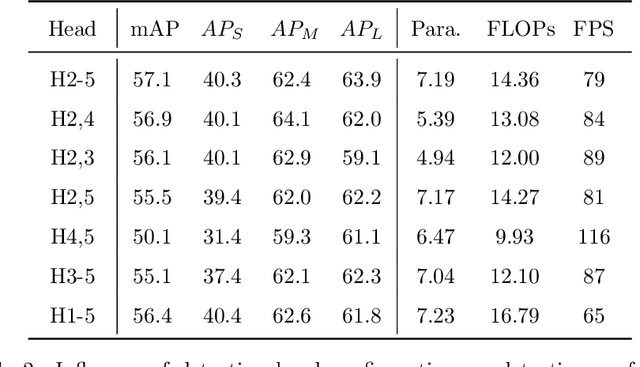
Multi-scale detection plays an important role in object detection models. However, researchers usually feel blank on how to reasonably configure detection heads combining multi-scale features at different input resolutions. We find that there are different matching relationships between the object distribution and the detection head at different input resolutions. Based on the instructive findings, we propose a lightweight traffic object detection network based on matching between detection head and object distribution, termed as MHD-Net. It consists of three main parts. The first is the detection head and object distribution matching strategy, which guides the rational configuration of detection head, so as to leverage multi-scale features to effectively detect objects at vastly different scales. The second is the cross-scale detection head configuration guideline, which instructs to replace multiple detection heads with only two detection heads possessing of rich feature representations to achieve an excellent balance between detection accuracy, model parameters, FLOPs and detection speed. The third is the receptive field enlargement method, which combines the dilated convolution module with shallow features of backbone to further improve the detection accuracy at the cost of increasing model parameters very slightly. The proposed model achieves more competitive performance than other models on BDD100K dataset and our proposed ETFOD-v2 dataset. The code will be available.