 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELATE: A Reinforcement Learning-Enhanced LLM Framework for Advertising Text Generation
Feb 12, 2026In online advertising, advertising text plays a critical role in attracting user engagement and driving advertiser value. Existing industrial systems typically follow a two-stage paradigm, where candidate texts are first generated and subsequently aligned with online performance metrics such as click-through rate(CTR). This separation often leads to misaligned optimization objectives and low funnel efficiency, limiting global optimality. To address these limitations, we propose RELATE, a reinforcement learning-based end-to-end framework that unifies generation and objective alignment within a single model. Instead of decoupling text generation from downstream metric alignment, RELATE integrates performance and compliance objectives directly into the generation process via policy learning. To better capture ultimate advertiser value beyond click-level signals, We incorporate conversion-oriented metrics into the objective and jointly model them with compliance constraints as multi-dimensional rewards, enabling the model to generate high-quality ad texts that improve conversion performance under policy constraints. Extensive experiments on large-scale industrial datasets demonstrate that RELATE consistently outperforms baselines. Furthermore, online deployment on a production advertising platform yields statistically significant improvements in click-through conversion rate(CTCVR) under strict policy constraints, validating the robustness and real-world effectiveness of the proposed framework.
An Equivariant Graph Network for Interpretable Nanoporous Materials Design
Sep 19, 2025Nanoporous materials hold promise for diverse sustainable applications, yet their vast chemical space poses challenges for efficient design. Machine learning offers a compelling pathway to accelerate the exploration, but existing models lack either interpretability or fidelity for elucidating the correlation between crystal geometry and property. Here, we report a three-dimensional periodic space sampling method that decomposes large nanoporous structures into local geometrical sites for combined property prediction and site-wise contribution quantification. Trained with a constructed database and retrieved datasets, our model achieves state-of-the-art accuracy and data efficiency for property prediction on gas storage, separation, and electrical conduction. Meanwhile, this approach enables the interpretation of the prediction and allows for accurate identification of significant local sites for targeted properties. Through identifying transferable high-performance sites across diverse nanoporous frameworks, our model paves the way for interpretable, symmetry-aware nanoporous materials design, which is extensible to other materials, like molecular crystals and beyond.
Data Skeleton Learning: Scalable Active Clustering with Sparse Graph Structures
Sep 10, 2025In this work, we focus on the efficiency and scalability of pairwise constraint-based active clustering, crucial for processing large-scale data in applications such as data mining, knowledge annotation, and AI model pre-training. Our goals are threefold: (1) to reduce computational costs for iterative clustering updates; (2) to enhance the impact of user-provided constraints to minimize annotation requirements for precise clustering; and (3) to cut down memory usage in practical deployments. To achieve these aims, we propose a graph-based active clustering algorithm that utilizes two sparse graphs: one for representing relationships between data (our proposed data skeleton) and another for updating this data skeleton. These two graphs work in concert, enabling the refinement of connected subgraphs within the data skeleton to create nested clusters. Our empirical analysis confirms that the proposed algorithm consistently facilitates more accurate clustering with dramatically less input of user-provided constraints, and outperforms its counterparts in terms of computational performance and scalability, while maintaining robustness across various distance metrics.
WECAR: An End-Edge Collaborative Inference and Training Framework for WiFi-Based Continuous Human Activity Recognition
Mar 09, 2025WiFi-based human activity recognition (HAR) holds significant promise for ubiquitous sensing in smart environments. A critical challenge lies in enabling systems to dynamically adapt to evolving scenarios, learning new activities without catastrophic forgetting of prior knowledge, while adhering to the stringent computational constraints of edge devices. Current approaches struggle to reconcile these requirements due to prohibitive storage demands for retaining historical data and inefficient parameter utilization. We propose WECAR, an end-edge collaborative inference and training framework for WiFi-based continuous HAR, which decouples computational workloads to overcome these limitations. In this framework, edge devices handle model training, lightweight optimization, and updates, while end devices perform efficient inference. WECAR introduces two key innovations, i.e., dynamic continual learning with parameter efficiency and hierarchical distillation for end deployment. For the former, we propose a transformer-based architecture enhanced by task-specific dynamic model expansion and stability-aware selective retraining. For the latter, we propose a dual-phase distillation mechanism that includes multi-head self-attention relation distillation and prefix relation distillation. We implement WECAR based on heterogeneous hardware using Jetson Nano as edge devices and the ESP32 as end devices, respectively. Our experiments across three public WiFi datasets reveal that WECAR not only outperforms several state-of-the-art methods in performance and parameter efficiency, but also achieves a substantial reduction in the model's parameter count post-optimization without sacrificing accuracy. This validates its practicality for resource-constrained environments.
SalM$2$: An Extremely Lightweight Saliency Mamba Model for Real-Time Cognitive Awareness of Driver Attention
Feb 22, 2025



Driver attention recognition in driving scenarios is a popular direction in traffic scene perception technology. It aims to understand human driver attention to focus on specific targets/objects in the driving scene. However, traffic scenes contain not only a large amount of visual information but also semantic information related to driving tasks. Existing methods lack attention to the actual semantic information present in driving scenes. Additionally, the traffic scene is a complex and dynamic process that requires constant attention to objects related to the current driving task. Existing models, influenced by their foundational frameworks, tend to have large parameter counts and complex structures. Therefore, this paper proposes a real-time saliency Mamba network based on the latest Mamba framework. As shown in Figure 1, our model uses very few parameters (0.08M, only 0.09~11.16% of other models), while maintaining SOTA performance or achieving over 98% of the SOTA model's performance.
ConSense: Continually Sensing Human Activity with WiFi via Growing and Picking
Feb 18, 2025WiFi-based human activity recognition (HAR) holds significant application potential across various fields. To handle dynamic environments where new activities are continuously introduced, WiFi-based HAR systems must adapt by learning new concepts without forgetting previously learned ones. Furthermore, retaining knowledge from old activities by storing historical exemplar is impractical for WiFi-based HAR due to privacy concerns and limited storage capacity of edge devices. In this work, we propose ConSense, a lightweight and fast-adapted exemplar-free class incremental learning framework for WiFi-based HAR. The framework leverages the transformer architecture and involves dynamic model expansion and selective retraining to preserve previously learned knowledge while integrating new information. Specifically, during incremental sessions, small-scale trainable parameters that are trained specifically on the data of each task are added in the multi-head self-attention layer. In addition, a selective retraining strategy that dynamically adjusts the weights in multilayer perceptron based on the performance stability of neurons across tasks is used. Rather than training the entire model, the proposed strategies of dynamic model expansion and selective retraining reduce the overall computational load while balancing stability on previous tasks and plasticity on new tasks. Evaluation results on three public WiFi datasets demonstrate that ConSense not only outperforms several competitive approaches but also requires fewer parameters, highlighting its practical utility in class-incremental scenarios for HAR.
D2D-Assisted Mobile Edge Computing: Optimal Scheduling under Uncertain Processing Cycles and Intermittent Communications
Sep 08, 2023



Mobile edge computing (MEC) has been regarded as a promising approach to deal with explosive computation requirements by enabling cloud computing capabilities at the edge of networks. Existing models of MEC impose some strong assumptions on the known processing cycles and unintermittent communications. However, practical MEC systems are constrained by various uncertainties and intermittent communications, rendering these assumptions impractical. In view of this, we investigate how to schedule task offloading in MEC systems with uncertainties. First, we derive a closed-form expression of the average offloading success probability in a device-to-device (D2D) assisted MEC system with uncertain computation processing cycles and intermittent communications. Then, we formulate a task offloading maximization problem (TOMP), and prove that the problem is NP-hard. For problem solving, if the problem instance exhibits a symmetric structure, we propose a task scheduling algorithm based on dynamic programming (TSDP). By solving this problem instance, we derive a bound to benchmark sub-optimal algorithm. For general scenarios, by reformulating the problem, we propose a repeated matching algorithm (RMA). Finally, in performance evaluations, we validate the accuracy of the closed-form expression of the average offloading success probability by Monte Carlo simulations, as well as the effectiveness of the proposed algorithms.
Rethinking the Detection Head Configuration for Traffic Object Detection
Oct 08, 2022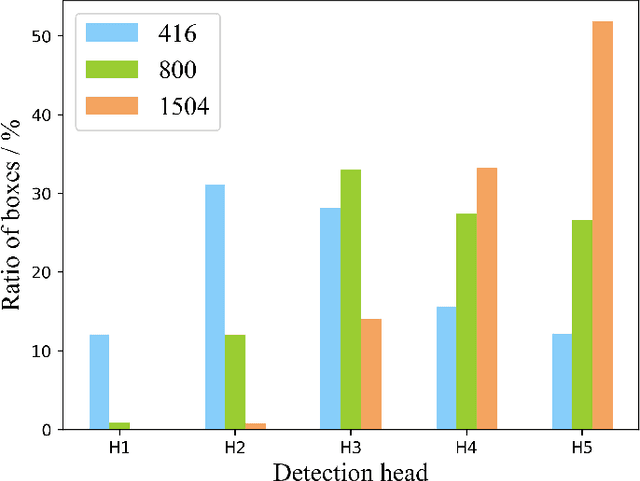
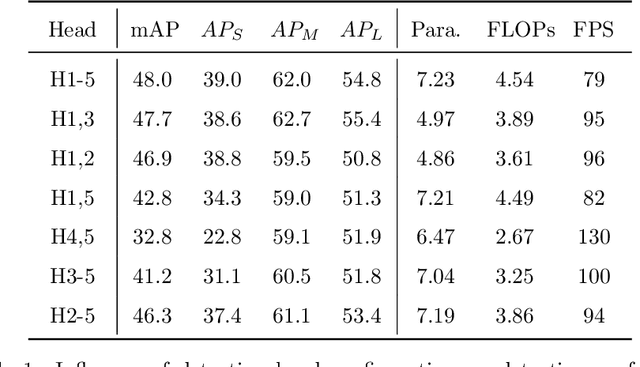
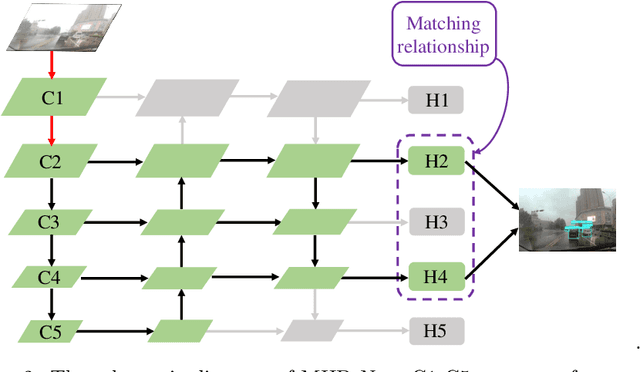
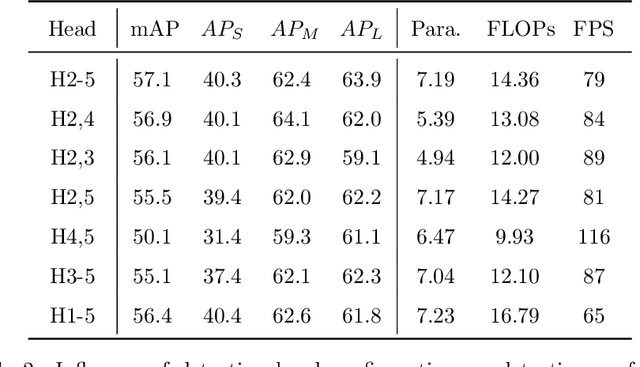
Multi-scale detection plays an important role in object detection models. However, researchers usually feel blank on how to reasonably configure detection heads combining multi-scale features at different input resolutions. We find that there are different matching relationships between the object distribution and the detection head at different input resolutions. Based on the instructive findings, we propose a lightweight traffic object detection network based on matching between detection head and object distribution, termed as MHD-Net. It consists of three main parts. The first is the detection head and object distribution matching strategy, which guides the rational configuration of detection head, so as to leverage multi-scale features to effectively detect objects at vastly different scales. The second is the cross-scale detection head configuration guideline, which instructs to replace multiple detection heads with only two detection heads possessing of rich feature representations to achieve an excellent balance between detection accuracy, model parameters, FLOPs and detection speed. The third is the receptive field enlargement method, which combines the dilated convolution module with shallow features of backbone to further improve the detection accuracy at the cost of increasing model parameters very slightly. The proposed model achieves more competitive performance than other models on BDD100K dataset and our proposed ETFOD-v2 dataset. The code will be available.
Lane detection in complex scenes based on end-to-end neural network
Oct 26, 2020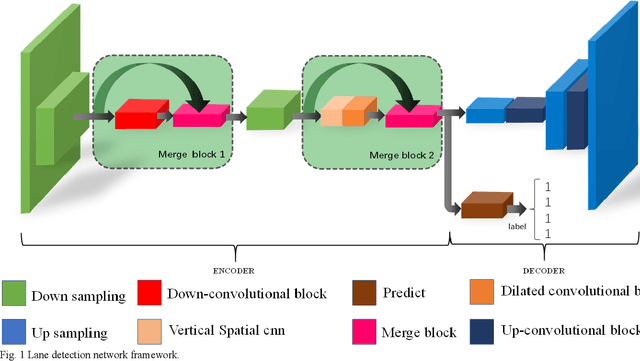
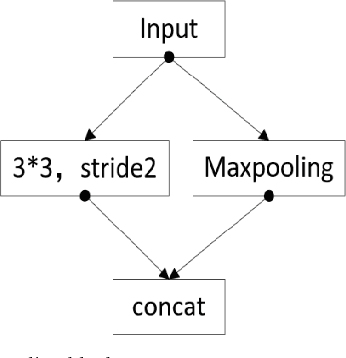
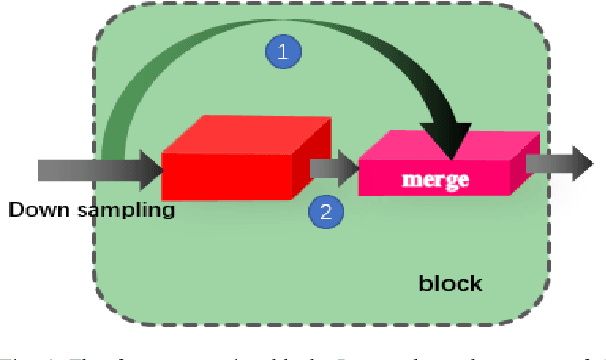

The lane detection is a key problem to solve the division of derivable areas in unmanned driving, and the detection accuracy of lane lines plays an important role in the decision-making of vehicle driving. Scenes faced by vehicles in daily driving are relatively complex. Bright light, insufficient light, and crowded vehicles will bring varying degrees of difficulty to lane detection. So we combine the advantages of spatial convolution in spatial information processing and the efficiency of ERFNet in semantic segmentation, propose an end-to-end network to lane detection in a variety of complex scenes. And we design the information exchange block by combining spatial convolution and dilated convolution, which plays a great role in understanding detailed information. Finally, our network was tested on the CULane database and its F1-measure with IOU threshold of 0.5 can reach 71.9%.
Lane Detection Model Based on Spatio-Temporal Network with Double ConvGRUs
Aug 10, 2020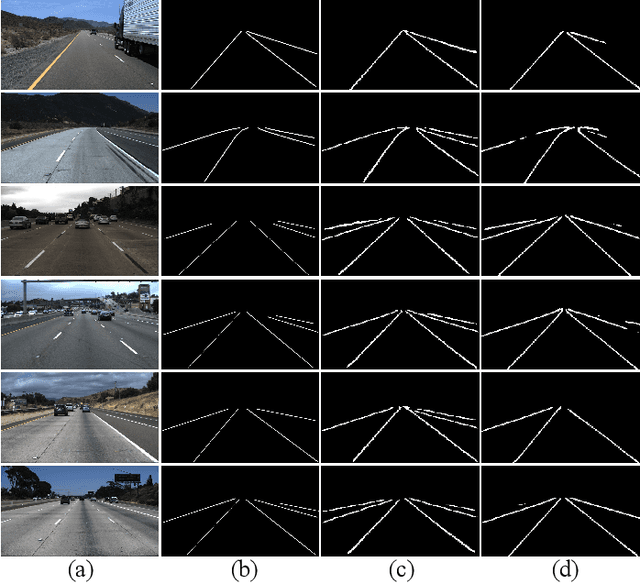
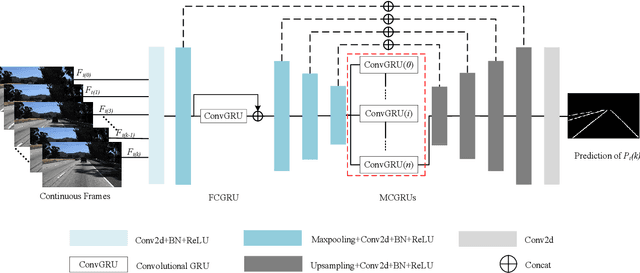
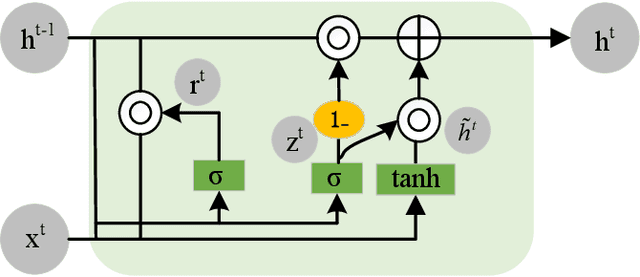
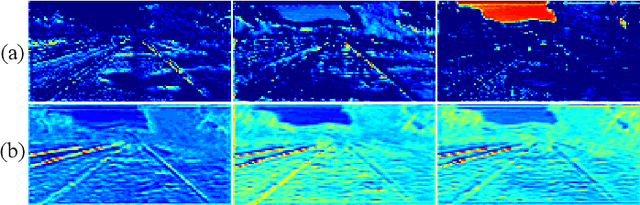
Lane detection is one of the indispensable and key elements of self-driving environmental perception. Many lane detection models have been proposed, solving lane detection under challenging conditions, including intersection merging and splitting, curves, boundaries, occlusions and combinations of scene types. Nevertheless, lane detection will remain an open problem for some time to come. The ability to cope well with those challenging scenes impacts greatly the applications of lane detection on advanced driver assistance systems (ADASs). In this paper, a spatio-temporal network with double Convolutional Gated Recurrent Units (ConvGRUs) is proposed to address lane detection in challenging scenes. Both of ConvGRUs have the same structures, but different locations and functions in our network. One is used to extract the information of the most likely low-level features of lane markings. The extracted features are input into the next layer of the end-to-end network after concatenating them with the outputs of some blocks. The other one takes some continuous frames as its input to process the spatio-temporal driving information. Extensive experiments on the large-scale Tusimple lane marking challenge dataset and Unsupervised LLAMAS dataset demonstrate that the proposed model can effectively detect lanes in the challenging driving scenes. Our model can outperform the state-of-the-art lane detection models.