 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Graph Contrastive Masked Autoencoders are Strong Distillers for EEG
Paper and Code
Nov 28, 2024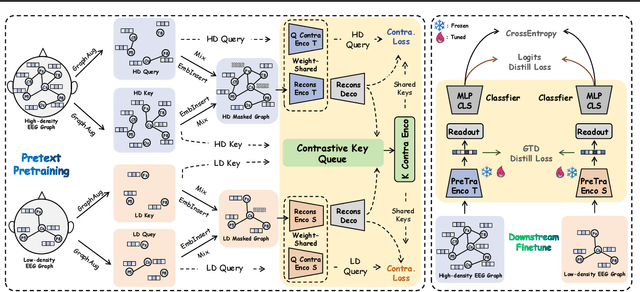
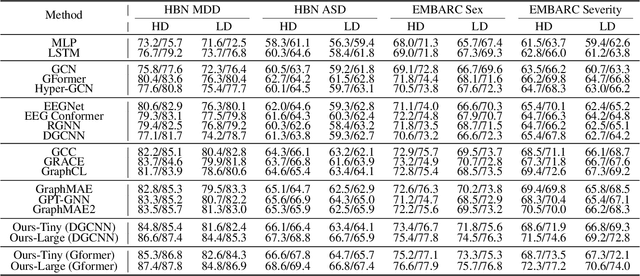


Effectively utilizing extensive unlabeled high-density EEG data to improve performance in scenarios with limited labeled low-density EEG data presents a significant challenge. In this paper, we address this by framing it as a graph transfer learning and knowledge distillation problem. We propose a Unified Pre-trained Graph Contrastive Masked Autoencoder Distiller, named EEG-DisGCMAE, to bridge the gap between unlabeled/labeled and high/low-density EEG data. To fully leverage the abundant unlabeled EEG data, we introduce a novel unified graph self-supervised pre-training paradigm, which seamlessly integrates Graph Contrastive Pre-training and Graph Masked Autoencoder Pre-training. This approach synergistically combines contrastive and generative pre-training techniques by reconstructing contrastive samples and contrasting the reconstructions. For knowledge distillation from high-density to low-density EEG data, we propose a Graph Topology Distillation loss function, allowing a lightweight student model trained on low-density data to learn from a teacher model trained on high-density data, effectively handling missing electrodes through contrastive distillation. To integrate transfer learning and distillation, we jointly pre-train the teacher and student models by contrasting their queries and keys during pre-training, enabling robust distillers for downstream tasks. We demonstrate the effectiveness of our method on four classification tasks across two clinical EEG datasets with abundant unlabeled data and limited labeled data. The experimental results show that our approach significantly outperforms contemporary methods in both efficiency and accuracy.