 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-based Semantic Similarity for Emotion Recognition in Web Objects
Paper and Code
Dec 17, 2016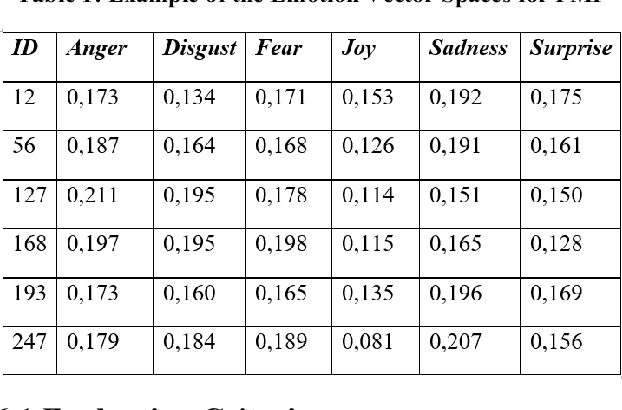

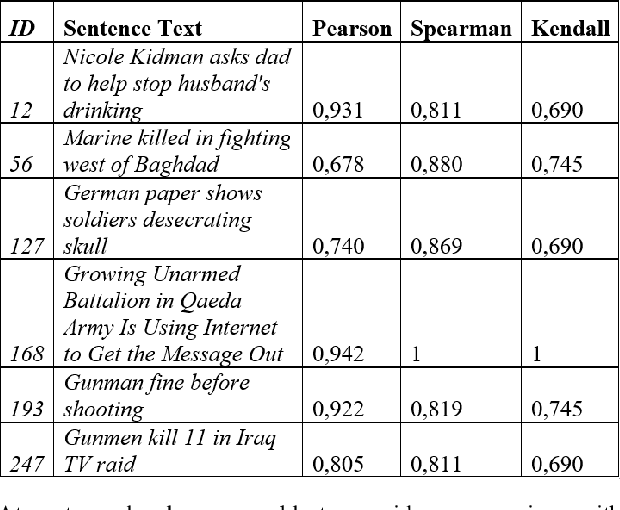
In this project we propose a new approach for emotion recognition using web-based similarity (e.g. confidence, PMI and PMING). We aim to extract basic emotions from short sentences with emotional content (e.g. news titles, tweets, captions), performing a web-based quantitative evaluation of semantic proximity between each word of the analyzed sentence and each emotion of a psychological model (e.g. Plutchik, Ekman, Lovheim). The phases of the extraction include: text preprocessing (tokenization, stop words, filtering), search engine automated query, HTML parsing of results (i.e. scraping), estimation of semantic proximity, ranking of emotions according to proximity measures. The main idea is that, since it is possible to generalize semantic similarity under the assumption that similar concepts co-occur in documents indexed in search engines, therefore also emotions can be generalized in the same way, through tags or terms that express them in a particular language, ranking emotions. Training results are compared to human evaluation, then additional comparative tests on results are performed, both for the global ranking correlation (e.g. Kendall, Spearman, Pearson) both for the evaluation of the emotion linked to each single word. Different from sentiment analysis, our approach works at a deeper level of abstraction, aiming at recognizing specific emotions and not only the positive/negative sentiment, in order to predict emotions as semantic data.