 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach for Improving Automatic Mouth Emotion Recognition
Dec 12, 2022The study proposes and tests a technique for automated emotion recognition through mouth detection via Convolutional Neural Networks (CNN), meant to be applied for supporting people with health disorders with communication skills issues (e.g. muscle wasting, stroke, autism, or, more simply, pain) in order to recognize emotions and generate real-time feedback, or data feeding supporting systems. The software system starts the computation identifying if a face is present on the acquired image, then it looks for the mouth location and extracts the corresponding features. Both tasks are carried out using Haar Feature-based Classifiers, which guarantee fast execution and promising performance. If our previous works focused on visual micro-expressions for personalized training on a single user, this strategy aims to train the system also on generalized faces data sets.
Sharing Linkable Learning Objects with the use of Metadata and a Taxonomy Assistant for Categorization
Dec 09, 2022In this work, a re-design of the Moodledata module functionalities is presented to share learning objects between e-learning content platforms, e.g., Moodle and G-Lorep, in a linkable object format. The e-learning courses content of the Drupal-based Content Management System G-Lorep for academic learning is exchanged designing an object incorporating metadata to support the reuse and the classification in its context. In such an Artificial Intelligence environment, the exchange of Linkable Learning Objects can be used for dialogue between Learning Systems to obtain information, especially with the use of semantic or structural similarity measures to enhance the existent Taxonomy Assistant for advanced automated classification.
Semantic Evolutionary Concept Distances for Effective Information Retrieval in Query Expansion
Jan 19, 2017
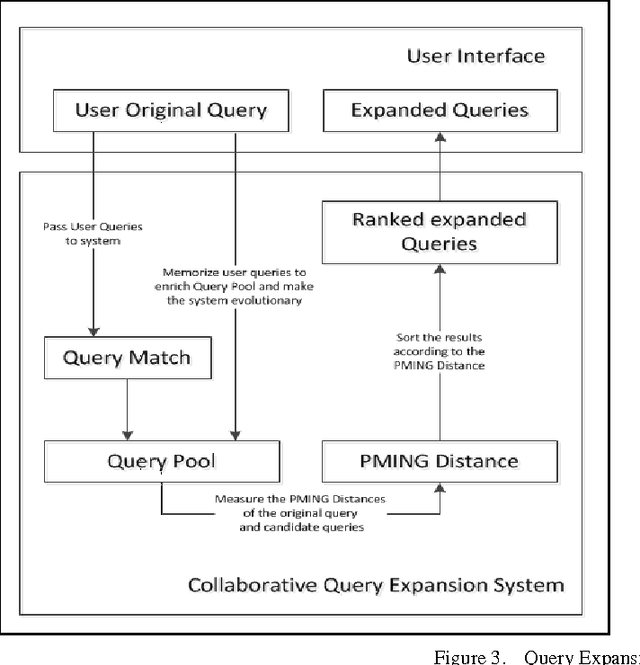

In this work several semantic approaches to concept-based query expansion and reranking schemes are studied and compared with different ontology-based expansion methods in web document search and retrieval. In particular, we focus on concept-based query expansion schemes, where, in order to effectively increase the precision of web document retrieval and to decrease the users browsing time, the main goal is to quickly provide users with the most suitable query expansion. Two key tasks for query expansion in web document retrieval are to find the expansion candidates, as the closest concepts in web document domain, and to rank the expanded queries properly. The approach we propose aims at improving the expansion phase for better web document retrieval and precision. The basic idea is to measure the distance between candidate concepts using the PMING distance, a collaborative semantic proximity measure, i.e. a measure which can be computed by using statistical results from web search engine. Experiments show that the proposed technique can provide users with more satisfying expansion results and improve the quality of web document retrieval.
* author's copy of publication in NLCS ICCSA 2013 proceedings: Collective Evolutionary Concept Distance Based Query Expansion for Effective Web Document Retrieval
Just an Update on PMING Distance for Web-based Semantic Similarity in Artificial Intelligence and Data Mining
Jan 09, 2017One of the main problems that emerges in the classic approach to semantics is the difficulty in acquisition and maintenance of ontologies and semantic annotations. On the other hand, the Internet explosion and the massive diffusion of mobile smart devices lead to the creation of a worldwide system, which information is daily checked and fueled by the contribution of millions of users who interacts in a collaborative way. Search engines, continually exploring the Web, are a natural source of information on which to base a modern approach to semantic annotation. A promising idea is that it is possible to generalize the semantic similarity, under the assumption that semantically similar terms behave similarly, and define collaborative proximity measures based on the indexing information returned by search engines. The PMING Distance is a proximity measure used in data mining and information retrieval, which collaborative information express the degree of relationship between two terms, using only the number of documents returned as result for a query on a search engine. In this work, the PMINIG Distance is updated, providing a novel formal algebraic definition, which corrects previous works. The novel point of view underlines the features of the PMING to be a locally normalized linear combination of the Pointwise Mutual Information and Normalized Google Distance. The analyzed measure dynamically reflects the collaborative change made on the web resources.
Web-based Semantic Similarity for Emotion Recognition in Web Objects
Dec 17, 2016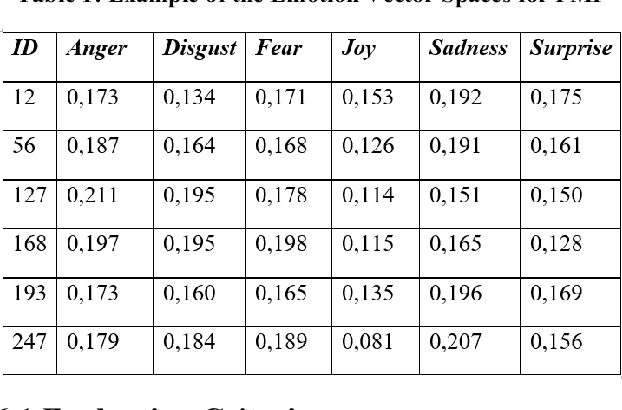

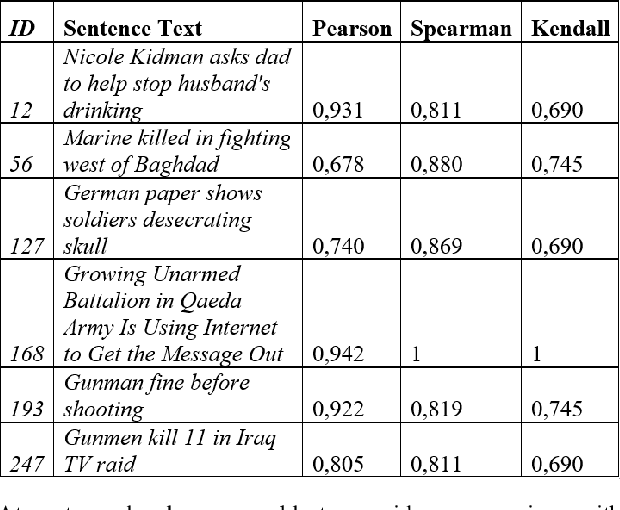
In this project we propose a new approach for emotion recognition using web-based similarity (e.g. confidence, PMI and PMING). We aim to extract basic emotions from short sentences with emotional content (e.g. news titles, tweets, captions), performing a web-based quantitative evaluation of semantic proximity between each word of the analyzed sentence and each emotion of a psychological model (e.g. Plutchik, Ekman, Lovheim). The phases of the extraction include: text preprocessing (tokenization, stop words, filtering), search engine automated query, HTML parsing of results (i.e. scraping), estimation of semantic proximity, ranking of emotions according to proximity measures. The main idea is that, since it is possible to generalize semantic similarity under the assumption that similar concepts co-occur in documents indexed in search engines, therefore also emotions can be generalized in the same way, through tags or terms that express them in a particular language, ranking emotions. Training results are compared to human evaluation, then additional comparative tests on results are performed, both for the global ranking correlation (e.g. Kendall, Spearman, Pearson) both for the evaluation of the emotion linked to each single word. Different from sentiment analysis, our approach works at a deeper level of abstraction, aiming at recognizing specific emotions and not only the positive/negative sentiment, in order to predict emotions as semantic data.
* Authors preprint, including revision differences with respect to the main publication 'Web-based Similarity for Emotion Recognition in Web Objects' published in the UCC '16 workshop in IEEE UCC, December 06 - 09, 2016, Shanghai, China. DOI: http://dx.doi.org/10.1145/2996890.3007883