 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Evolutionary Concept Distances for Effective Information Retrieval in Query Expansion
Jan 19, 2017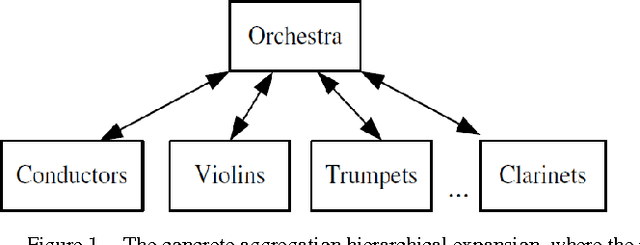
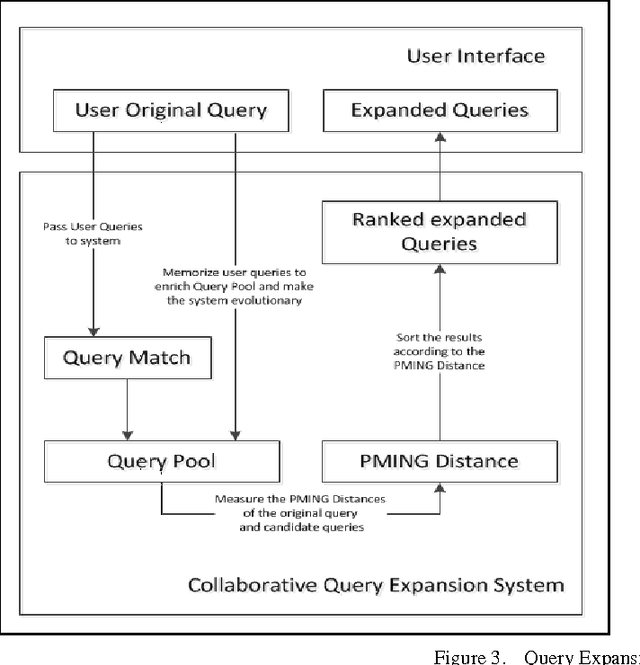

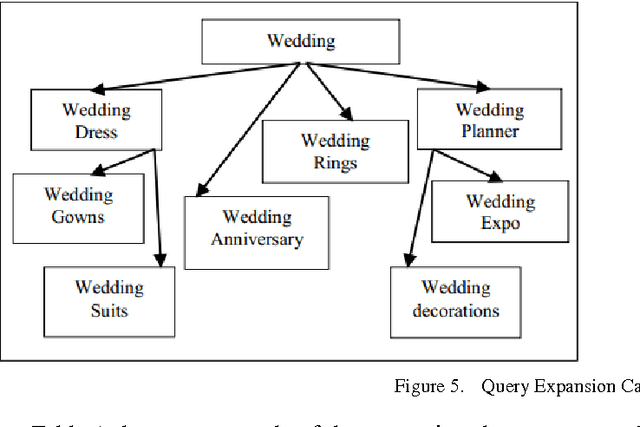
In this work several semantic approaches to concept-based query expansion and reranking schemes are studied and compared with different ontology-based expansion methods in web document search and retrieval. In particular, we focus on concept-based query expansion schemes, where, in order to effectively increase the precision of web document retrieval and to decrease the users browsing time, the main goal is to quickly provide users with the most suitable query expansion. Two key tasks for query expansion in web document retrieval are to find the expansion candidates, as the closest concepts in web document domain, and to rank the expanded queries properly. The approach we propose aims at improving the expansion phase for better web document retrieval and precision. The basic idea is to measure the distance between candidate concepts using the PMING distance, a collaborative semantic proximity measure, i.e. a measure which can be computed by using statistical results from web search engine. Experiments show that the proposed technique can provide users with more satisfying expansion results and improve the quality of web document retrieval.
* author's copy of publication in NLCS ICCSA 2013 proceedings: Collective Evolutionary Concept Distance Based Query Expansion for Effective Web Document Retrieval
Web-based Semantic Similarity for Emotion Recognition in Web Objects
Dec 17, 2016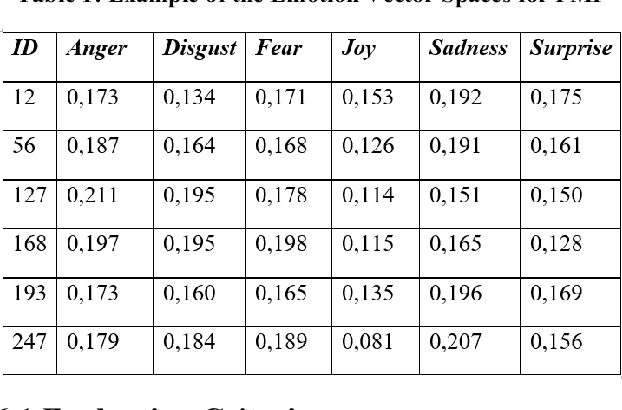

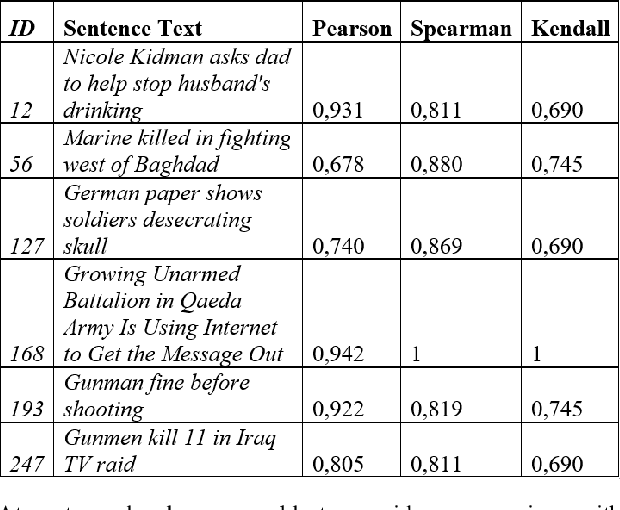
In this project we propose a new approach for emotion recognition using web-based similarity (e.g. confidence, PMI and PMING). We aim to extract basic emotions from short sentences with emotional content (e.g. news titles, tweets, captions), performing a web-based quantitative evaluation of semantic proximity between each word of the analyzed sentence and each emotion of a psychological model (e.g. Plutchik, Ekman, Lovheim). The phases of the extraction include: text preprocessing (tokenization, stop words, filtering), search engine automated query, HTML parsing of results (i.e. scraping), estimation of semantic proximity, ranking of emotions according to proximity measures. The main idea is that, since it is possible to generalize semantic similarity under the assumption that similar concepts co-occur in documents indexed in search engines, therefore also emotions can be generalized in the same way, through tags or terms that express them in a particular language, ranking emotions. Training results are compared to human evaluation, then additional comparative tests on results are performed, both for the global ranking correlation (e.g. Kendall, Spearman, Pearson) both for the evaluation of the emotion linked to each single word. Different from sentiment analysis, our approach works at a deeper level of abstraction, aiming at recognizing specific emotions and not only the positive/negative sentiment, in order to predict emotions as semantic data.
* Authors preprint, including revision differences with respect to the main publication 'Web-based Similarity for Emotion Recognition in Web Objects' published in the UCC '16 workshop in IEEE UCC, December 06 - 09, 2016, Shanghai, China. DOI: http://dx.doi.org/10.1145/2996890.3007883