 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Effectiveness of Multimedia Information Search Using the Epsilon-Greedy Algorithm
Nov 22, 2019


In the search and retrieval of multimedia objects, it is impractical to either manually or automatically extract the contents for indexing since most of the multimedia contents are not machine extractable, while manual extraction tends to be highly laborious and time-consuming. However, by systematically capturing and analyzing the feedback patterns of human users, vital information concerning the multimedia contents can be harvested for effective indexing and subsequent search. By learning from the human judgment and mental evaluation of users, effective search indices can be gradually developed and built up, and subsequently be exploited to find the most relevant multimedia objects. To avoid hovering around a local maximum, we apply the epsilon-greedy method to systematically explore the search space. Through such methodic exploration, we show that the proposed approach is able to guarantee that the most relevant objects can always be discovered, even though initially it may have been overlooked or not regarded as relevant. The search behavior of the present approach is quantitatively analyzed, and closed-form expressions are obtained for the performance of two variants of the epsilon-greedy algorithm, namely EGSE-A and EGSE-B. Simulations and experiments on real data set have been performed which show good agreement with the theoretical findings. The present method is able to leverage exploration in an effective way to significantly raise the performance of multimedia information search, and enables the certain discovery of relevant objects which may be otherwise undiscoverable.
Analysis of Evolutionary Behavior in Self-Learning Media Search Engines
Nov 22, 2019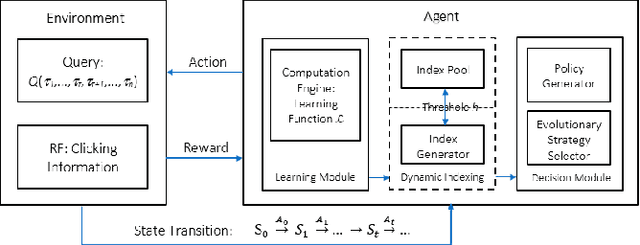


The diversity of intrinsic qualities of multimedia entities tends to impede their effective retrieval. In a SelfLearning Search Engine architecture, the subtle nuances of human perceptions and deep knowledge are taught and captured through unsupervised reinforcement learning, where the degree of reinforcement may be suitably calibrated. Such architectural paradigm enables indexes to evolve naturally while accommodating the dynamic changes of user interests. It operates by continuously constructing indexes over time, while injecting progressive improvement in search performance. For search operations to be effective, convergence of index learning is of crucial importance to ensure efficiency and robustness. In this paper, we develop a Self-Learning Search Engine architecture based on reinforcement learning using a Markov Decision Process framework. The balance between exploration and exploitation is achieved through evolutionary exploration Strategies. The evolutionary index learning behavior is then studied and formulated using stochastic analysis. Experimental results are presented which corroborate the steady convergence of the index evolution mechanism. Index Term
Leveraging Reinforcement Learning Techniques for Effective Policy Adoption and Validation
Jun 21, 2019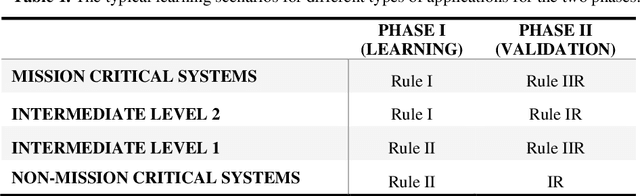
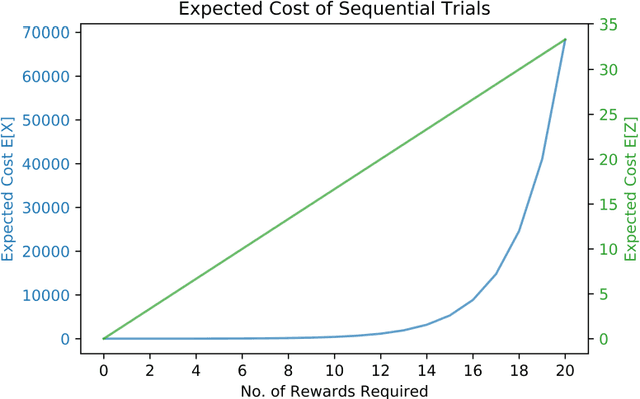
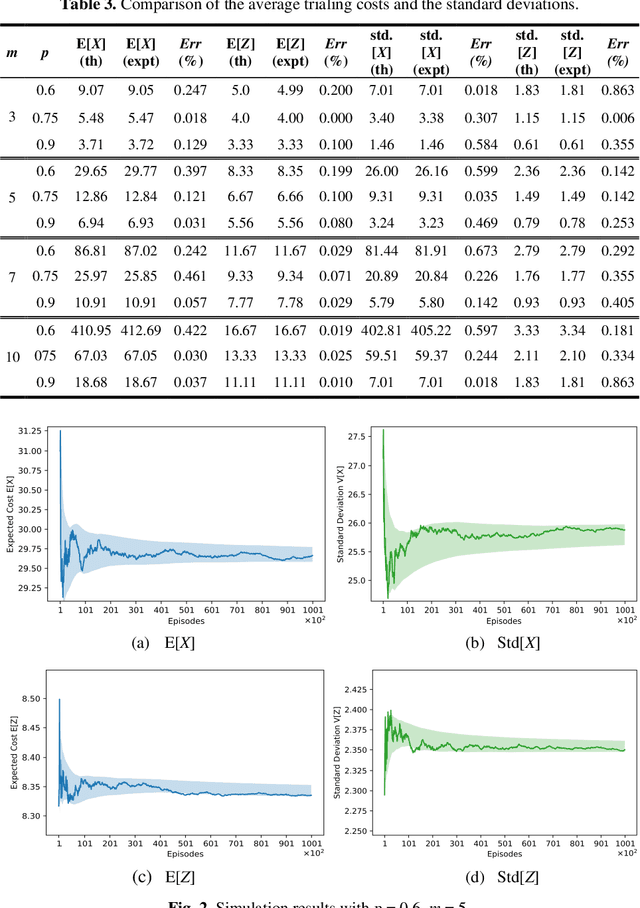
Rewards and punishments in different forms are pervasive and present in a wide variety of decision-making scenarios. By observing the outcome of a sufficient number of repeated trials, one would gradually learn the value and usefulness of a particular policy or strategy. However, in a given environment, the outcomes resulting from different trials are subject to chance influence and variations. In learning about the usefulness of a given policy, significant costs are involved in systematically undertaking the sequential trials; therefore, in most learning episodes, one would wish to keep the cost within bounds by adopting learning stopping rules. In this paper, we examine the deployment of different stopping strategies in given learning environments which vary from highly stringent for mission critical operations to highly tolerant for non-mission critical operations, and emphasis is placed on the former with particular application to aviation safety. In policy evaluation, two sequential phases of learning are identified, and we describe the outcomes variations using a probabilistic model, with closedform expressions obtained for the key measures of performance. Decision rules that map the trial observations to policy choices are also formulated. In addition, simulation experiments are performed, which corroborate the validity of the theoretical results.
Performance Dynamics and Termination Errors in Reinforcement Learning: A Unifying Perspective
Feb 11, 2019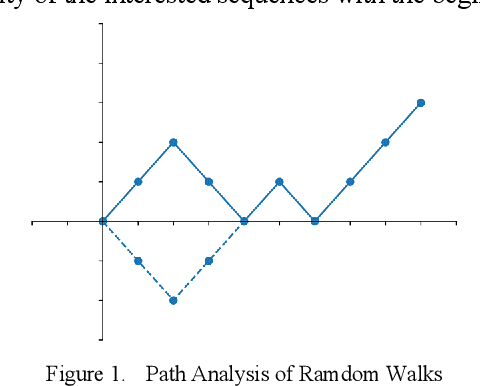
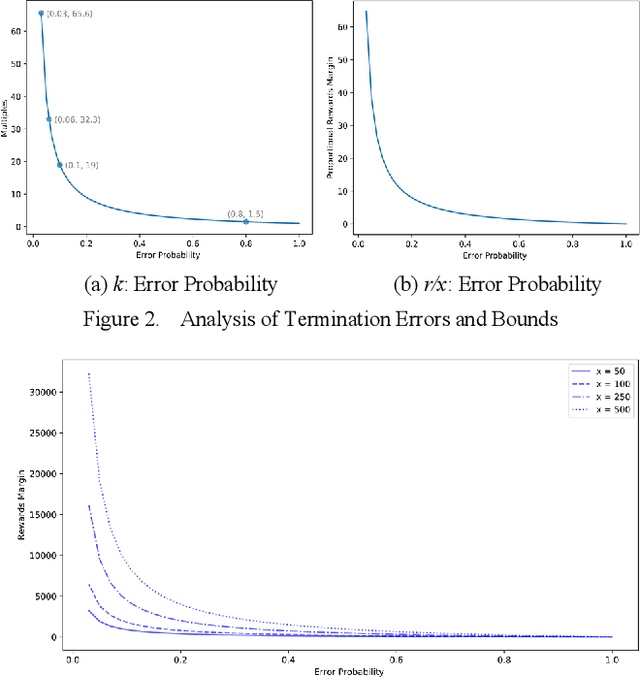
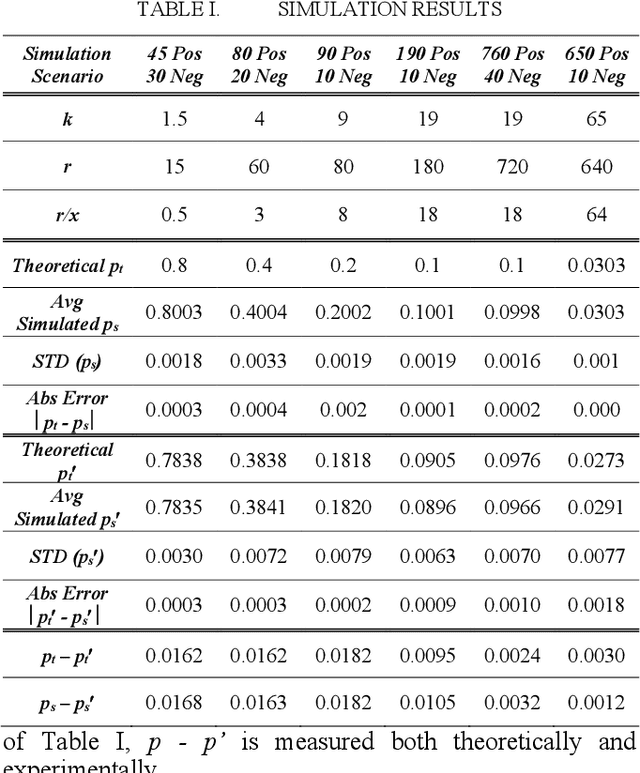
In reinforcement learning, a decision needs to be made at some point as to whether it is worthwhile to carry on with the learning process or to terminate it. In many such situations, stochastic elements are often present which govern the occurrence of rewards, with the sequential occurrences of positive rewards randomly interleaved with negative rewards. For most practical learners, the learning is considered useful if the number of positive rewards always exceeds the negative ones. A situation that often calls for learning termination is when the number of negative rewards exceeds the number of positive rewards. However, while this seems reasonable, the error of premature termination, whereby termination is enacted along with the conclusion of learning failure despite the positive rewards eventually far outnumber the negative ones, can be significant. In this paper, using combinatorial analysis we study the error probability in wrongly terminating a reinforcement learning activity which undermines the effectiveness of an optimal policy, and we show that the resultant error can be quite high. Whilst we demonstrate mathematically that such errors can never be eliminated, we propose some practical mechanisms that can effectively reduce such errors. Simulation experiments have been carried out, the results of which are in close agreement with our theoretical findings.
Stochastic Reinforcement Learning
Feb 11, 2019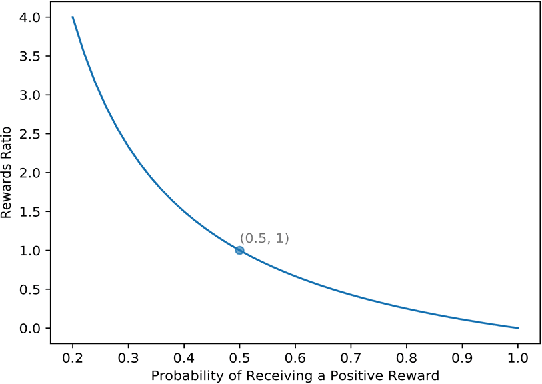


In reinforcement learning episodes, the rewards and punishments are often non-deterministic, and there are invariably stochastic elements governing the underlying situation. Such stochastic elements are often numerous and cannot be known in advance, and they have a tendency to obscure the underlying rewards and punishments patterns. Indeed, if stochastic elements were absent, the same outcome would occur every time and the learning problems involved could be greatly simplified. In addition, in most practical situations, the cost of an observation to receive either a reward or punishment can be significant, and one would wish to arrive at the correct learning conclusion by incurring minimum cost. In this paper, we present a stochastic approach to reinforcement learning which explicitly models the variability present in the learning environment and the cost of observation. Criteria and rules for learning success are quantitatively analyzed, and probabilities of exceeding the observation cost bounds are also obtained.
Semantic Evolutionary Concept Distances for Effective Information Retrieval in Query Expansion
Jan 19, 2017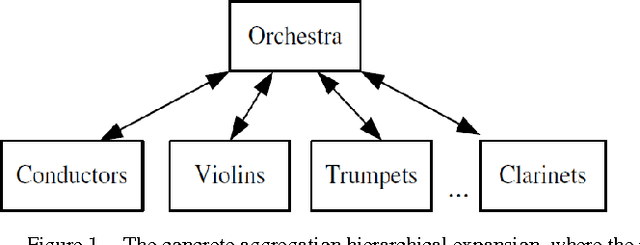
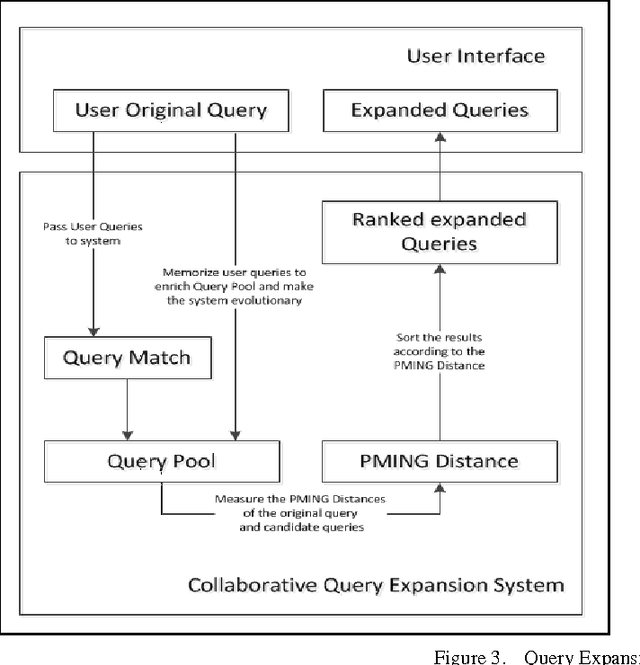

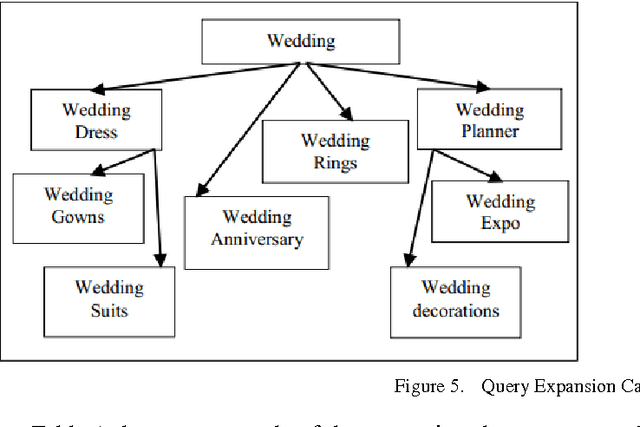
In this work several semantic approaches to concept-based query expansion and reranking schemes are studied and compared with different ontology-based expansion methods in web document search and retrieval. In particular, we focus on concept-based query expansion schemes, where, in order to effectively increase the precision of web document retrieval and to decrease the users browsing time, the main goal is to quickly provide users with the most suitable query expansion. Two key tasks for query expansion in web document retrieval are to find the expansion candidates, as the closest concepts in web document domain, and to rank the expanded queries properly. The approach we propose aims at improving the expansion phase for better web document retrieval and precision. The basic idea is to measure the distance between candidate concepts using the PMING distance, a collaborative semantic proximity measure, i.e. a measure which can be computed by using statistical results from web search engine. Experiments show that the proposed technique can provide users with more satisfying expansion results and improve the quality of web document retrieval.
* author's copy of publication in NLCS ICCSA 2013 proceedings: Collective Evolutionary Concept Distance Based Query Expansion for Effective Web Document Retrieval