 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLP: Dynamic Layerwise Pruning in Large Language Models
May 27, 2025Pruning has recently been widely adopted to reduce the parameter scale and improve the inference efficiency of Large Language Models (LLMs). Mainstream pruning techniques often rely on uniform layerwise pruning strategies, which can lead to severe performance degradation at high sparsity levels. Recognizing the varying contributions of different layers in LLMs, recent studies have shifted their focus toward non-uniform layerwise pruning. However, these approaches often rely on pre-defined values, which can result in suboptimal performance. To overcome these limitations, we propose a novel method called Dynamic Layerwise Pruning (DLP). This approach adaptively determines the relative importance of each layer by integrating model weights with input activation information, assigning pruning rates accordingly. Experimental results show that DLP effectively preserves model performance at high sparsity levels across multiple LLMs. Specifically, at 70% sparsity, DLP reduces the perplexity of LLaMA2-7B by 7.79 and improves the average accuracy by 2.7% compared to state-of-the-art methods. Moreover, DLP is compatible with various existing LLM compression techniques and can be seamlessly integrated into Parameter-Efficient Fine-Tuning (PEFT). We release the code at https://github.com/ironartisan/DLP to facilitate future research.
PROEMO: Prompt-Driven Text-to-Speech Synthesis Based on Emotion and Intensity Control
Jan 10, 2025Speech synthesis has significantly advanced from statistical methods to deep neural network architectures, leading to various text-to-speech (TTS) models that closely mimic human speech patterns. However, capturing nuances such as emotion and style in speech synthesis is challenging. To address this challenge, we introduce an approach centered on prompt-based emotion control. The proposed architecture incorporates emotion and intensity control across multi-speakers. Furthermore, we leverage large language models (LLMs) to manipulate speech prosody while preserving linguistic content. Using embedding emotional cues, regulating intensity levels, and guiding prosodic variations with prompts, our approach infuses synthesized speech with human-like expressiveness and variability. Lastly, we demonstrate the effectiveness of our approach through a systematic exploration of the control mechanisms mentioned above.
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Jun 25, 2024
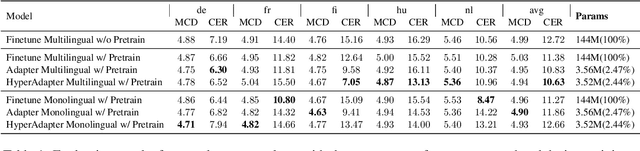


Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $\sim$2.5\% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Apr 06, 2024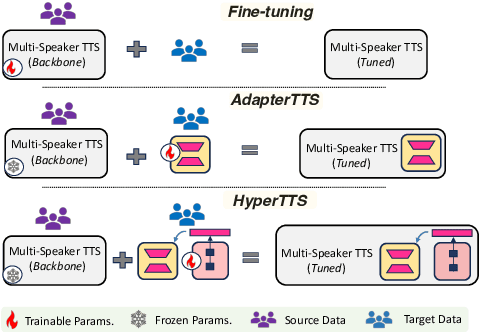
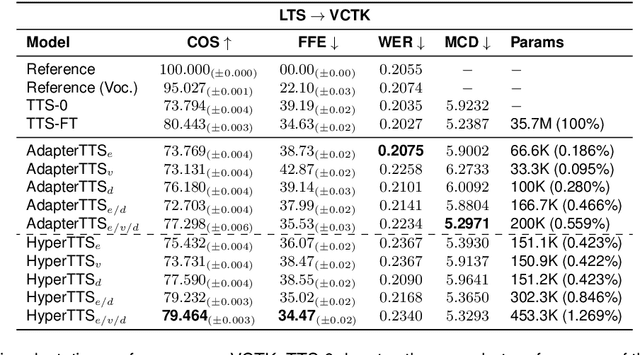
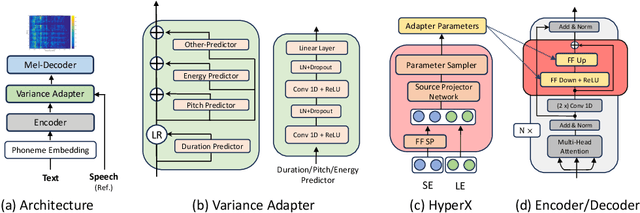

Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, "hypernetwork", that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024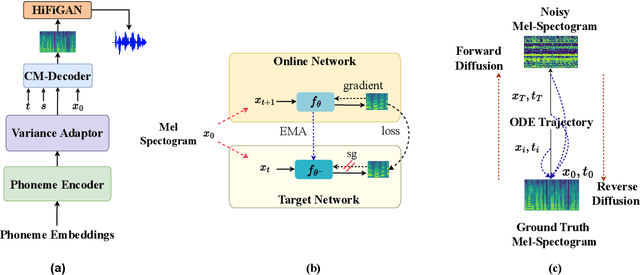
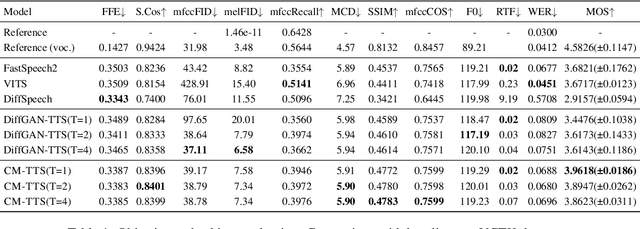
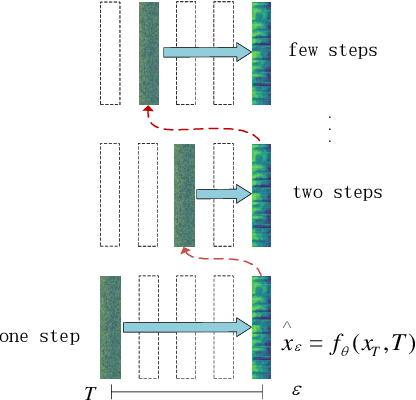

Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.
Evaluating Parameter-Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding
Mar 02, 2023Fine-tuning is widely used as the default algorithm for transfer learning from pre-trained models. Parameter inefficiency can however arise when, during transfer learning, all the parameters of a large pre-trained model need to be updated for individual downstream tasks. As the number of parameters grows, fine-tuning is prone to overfitting and catastrophic forgetting. In addition, full fine-tuning can become prohibitively expensive when the model is used for many tasks. To mitigate this issue, parameter-efficient transfer learning algorithms, such as adapters and prefix tuning, have been proposed as a way to introduce a few trainable parameters that can be plugged into large pre-trained language models such as BERT, and HuBERT. In this paper, we introduce the Speech UndeRstanding Evaluation (SURE) benchmark for parameter-efficient learning for various speech-processing tasks. Additionally, we introduce a new adapter, ConvAdapter, based on 1D convolution. We show that ConvAdapter outperforms the standard adapters while showing comparable performance against prefix tuning and LoRA with only 0.94% of trainable parameters on some of the task in SURE. We further explore the effectiveness of parameter efficient transfer learning for speech synthesis task such as Text-to-Speech (TTS).
Analyzing Modality Robustness in Multimodal Sentiment Analysis
May 30, 2022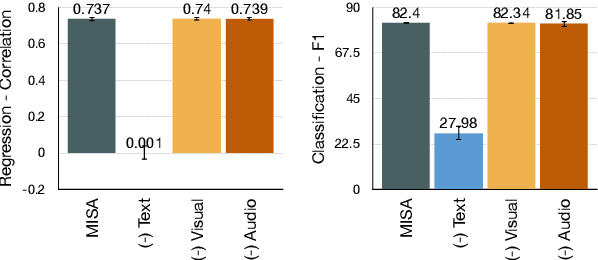

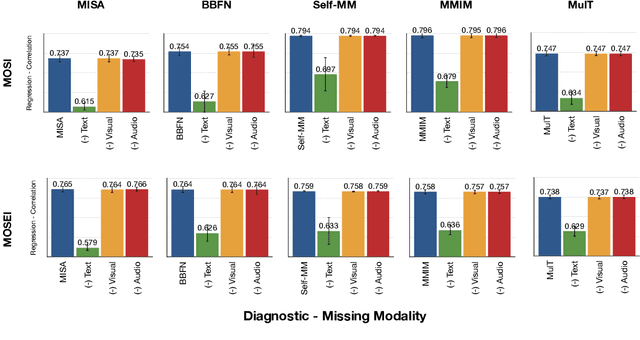
Building robust multimodal models are crucial for achieving reliable deployment in the wild. Despite its importance, less attention has been paid to identifying and improving the robustness of Multimodal Sentiment Analysis (MSA) models. In this work, we hope to address that by (i) Proposing simple diagnostic checks for modality robustness in a trained multimodal model. Using these checks, we find MSA models to be highly sensitive to a single modality, which creates issues in their robustness; (ii) We analyze well-known robust training strategies to alleviate the issues. Critically, we observe that robustness can be achieved without compromising on the original performance. We hope our extensive study-performed across five models and two benchmark datasets-and proposed procedures would make robustness an integral component in MSA research. Our diagnostic checks and robust training solutions are simple to implement and available at https://github. com/declare-lab/MSA-Robustness.
Integrating Subgraph-aware Relation and DirectionReasoning for Question Answering
Apr 01, 2021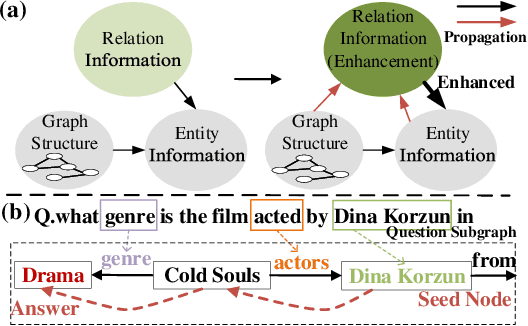
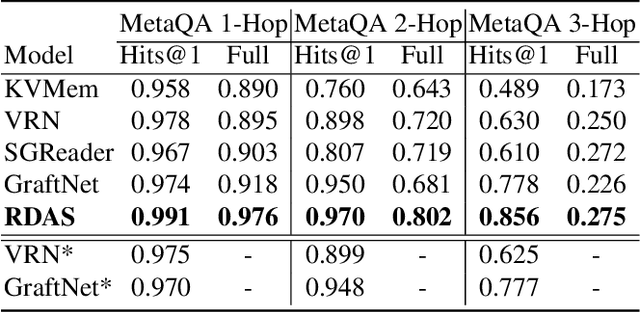
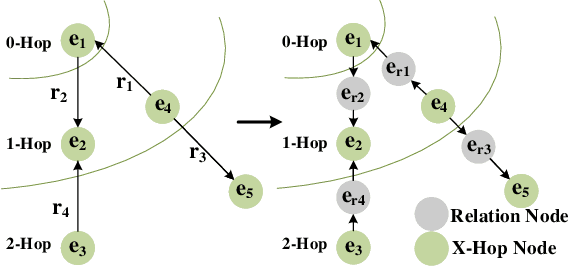
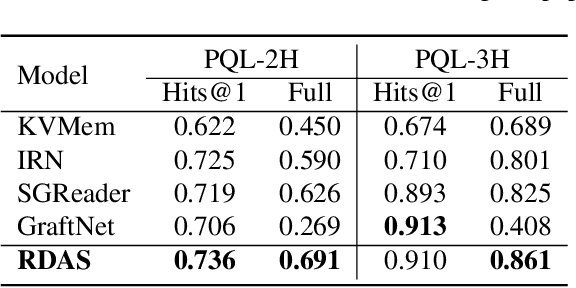
Question Answering (QA) models over Knowledge Bases (KBs) are capable of providing more precise answers by utilizing relation information among entities. Although effective, most of these models solely rely on fixed relation representations to obtain answers for different question-related KB subgraphs. Hence, the rich structured information of these subgraphs may be overlooked by the relation representation vectors. Meanwhile, the direction information of reasoning, which has been proven effective for the answer prediction on graphs, has not been fully explored in existing work. To address these challenges, we propose a novel neural model, Relation-updated Direction-guided Answer Selector (RDAS), which converts relations in each subgraph to additional nodes to learn structure information. Additionally, we utilize direction information to enhance the reasoning ability. Experimental results show that our model yields substantial improvements on two widely used datasets.
Certainty-Driven Consistency Loss for Semi-supervised Learning
Jan 17, 2019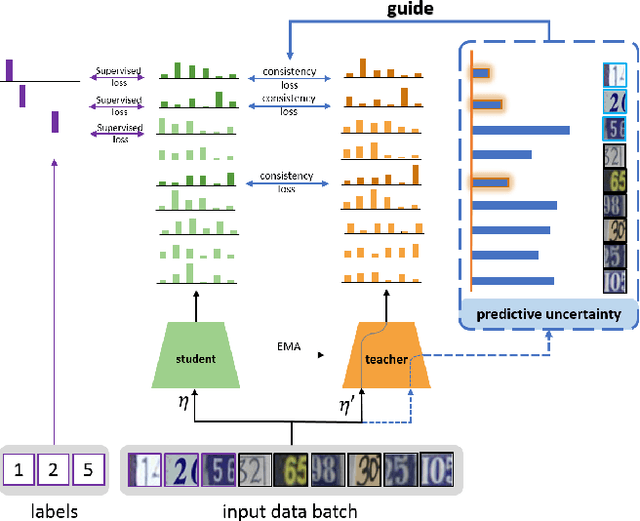
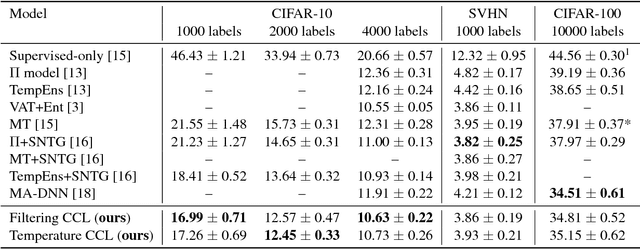
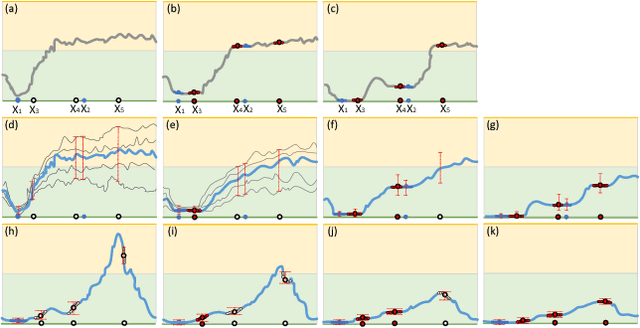
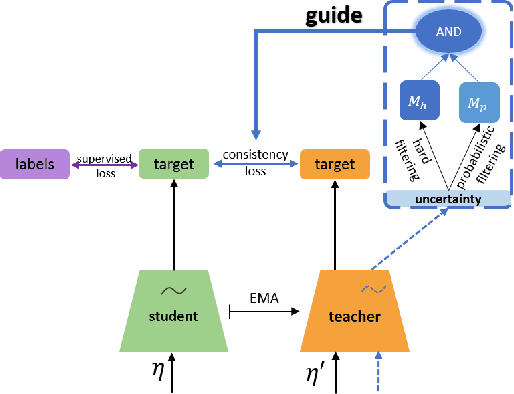
The recently proposed semi-supervised learning methods exploit consistency loss between different predictions under random perturbations. Typically, a student model is trained to predict consistently with the targets generated by a noisy teacher. However, they ignore the fact that not all training data provide meaningful and reliable information in terms of consistency. For misclassified data, blindly minimizing the consistency loss around them can hinder learning. In this paper, we propose a novel certainty-driven consistency loss (CCL) to dynamically select data samples that have relatively low uncertainty. Specifically, we measure the variance or entropy of multiple predictions under random augmentations and dropout as an estimation of uncertainty. Then, we introduce two approaches, i.e. Filtering CCL and Temperature CCL to guide the student learn more meaningful and certain/reliable targets, and hence improve the quality of the gradients backpropagated to the student. Experiments demonstrate the advantages of the proposed method over the state-of-the-art semi-supervised deep learning methods on three benchmark datasets: SVHN, CIFAR10, and CIFAR100. Our method also shows robustness to noisy labels.