 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Paper and Code
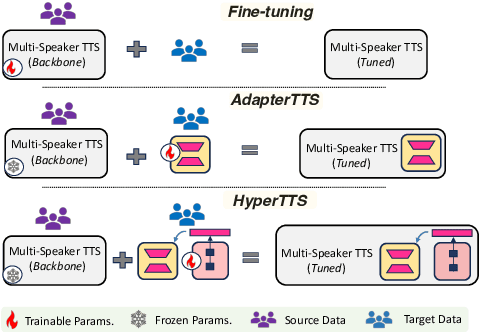
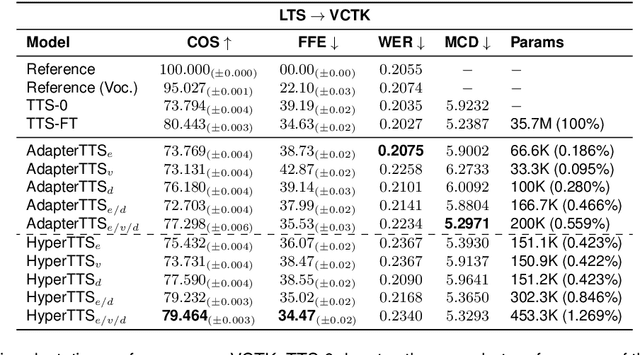
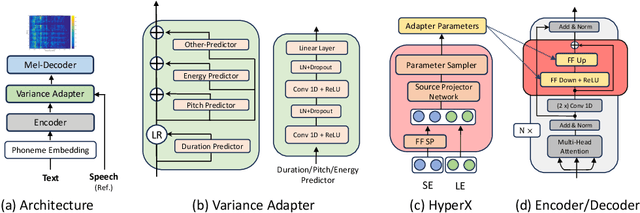

Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, "hypernetwork", that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.