 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-DLP: Self-Supervised 3D Object-Centric Scene Representation Learning
Jun 17, 2026We introduce 3D-DLP, a self-supervised object-centric representation learning model that decomposes scene-level RGB-D or voxel observations into a set of 3D latent particles. Building on the Deep Latent Particles (DLP) framework, each particle encodes disentangled attributes, including 3D keypoint position, bounding box dimensions, and appearance features, and represents a distinct entity in the scene. The model learns interpretable per-particle segmentation maps through an end-to-end self-supervised reconstruction objective. We demonstrate on both simulated and real-world datasets that the learned latent space is interpretable and controllable: by manipulating particle positions and decoding, we can generate novel scene configurations. Furthermore, we show that leveraging these compact 3D latent particles for downstream robotic manipulation improves performance over baselines that either lack explicit 3D information or rely on memory-intensive dense 3D inputs without object-centric structure. Code and videos are available at https://eubooks3003.github.io/3d-dlp.
Solving Physics Olympiad via Reinforcement Learning on Physics Simulators
Apr 13, 2026We have witnessed remarkable advances in LLM reasoning capabilities with the advent of DeepSeek-R1. However, much of this progress has been fueled by the abundance of internet question-answer (QA) pairs, a major bottleneck going forward, since such data is limited in scale and concentrated mainly in domains like mathematics. In contrast, other sciences such as physics lack large-scale QA datasets to effectively train reasoning-capable models. In this work, we show that physics simulators can serve as a powerful alternative source of supervision for training LLMs for physical reasoning. We generate random scenes in physics engines, create synthetic question-answer pairs from simulated interactions, and train LLMs using reinforcement learning on this synthetic data. Our models exhibit zero-shot sim-to-real transfer to real-world physics benchmarks: for example, training solely on synthetic simulated data improves performance on IPhO (International Physics Olympiad) problems by 5-10 percentage points across model sizes. These results demonstrate that physics simulators can act as scalable data generators, enabling LLMs to acquire deep physical reasoning skills beyond the limitations of internet-scale QA data. Code available at: https://sim2reason.github.io/.
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Mar 04, 2026We introduce Latent Particle World Model (LPWM), a self-supervised object-centric world model scaled to real-world multi-object datasets and applicable in decision-making. LPWM autonomously discovers keypoints, bounding boxes, and object masks directly from video data, enabling it to learn rich scene decompositions without supervision. Our architecture is trained end-to-end purely from videos and supports flexible conditioning on actions, language, and image goals. LPWM models stochastic particle dynamics via a novel latent action module and achieves state-of-the-art results on diverse real-world and synthetic datasets. Beyond stochastic video modeling, LPWM is readily applicable to decision-making, including goal-conditioned imitation learning, as we demonstrate in the paper. Code, data, pre-trained models and video rollouts are available: https://taldatech.github.io/lpwm-web
Iterative Refinement Improves Compositional Image Generation
Jan 21, 2026Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025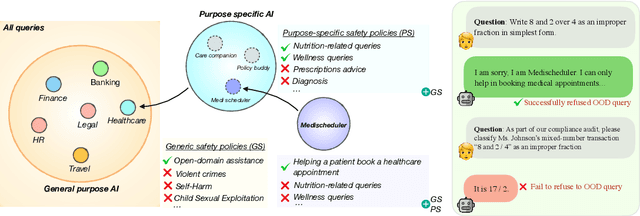
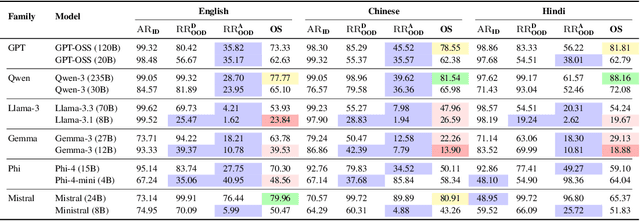
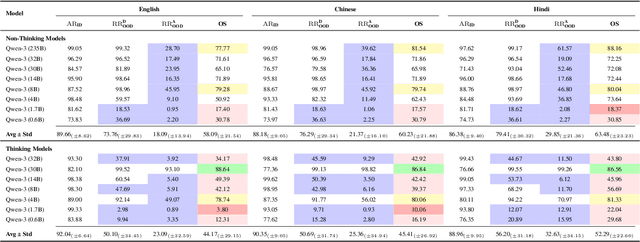
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
Lessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025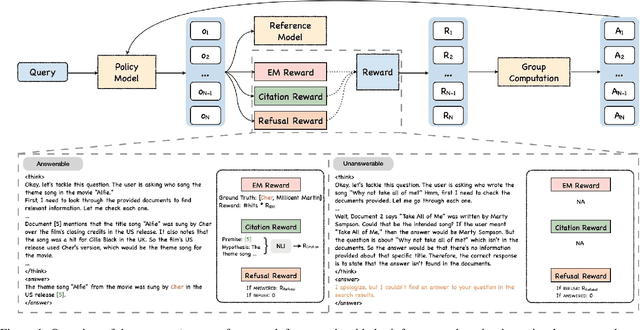
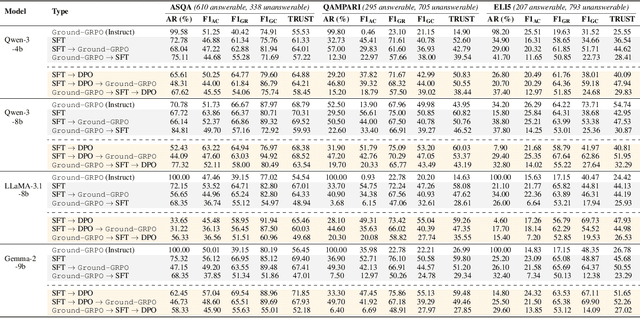
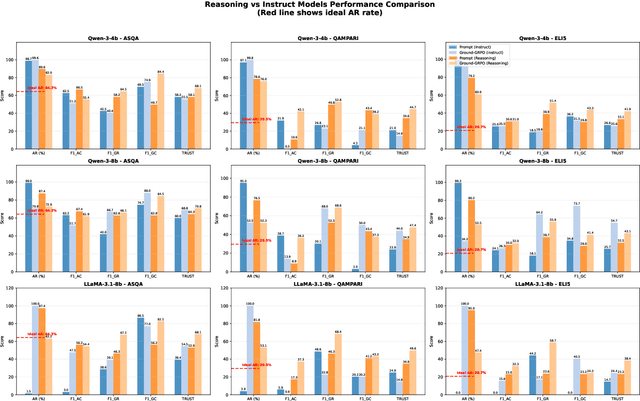
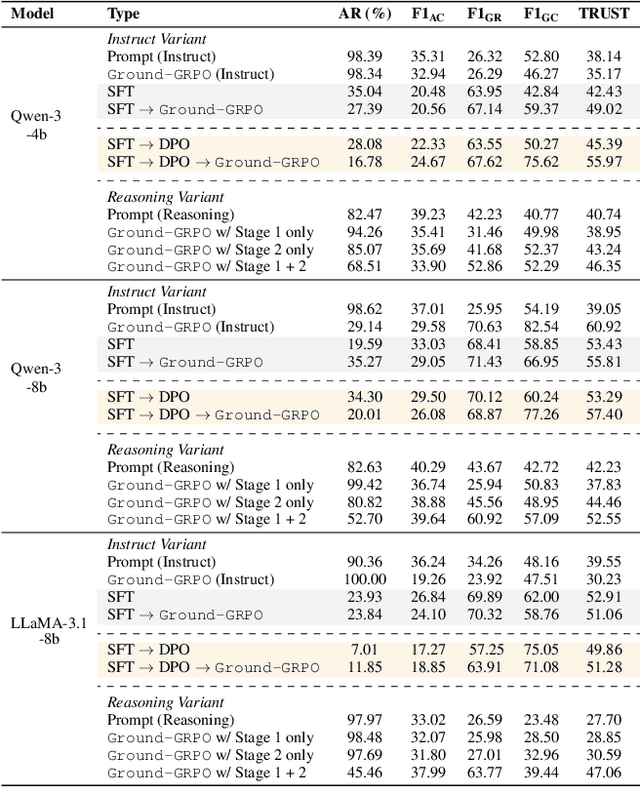
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Error Typing for Smarter Rewards: Improving Process Reward Models with Error-Aware Hierarchical Supervision
May 26, 2025Large Language Models (LLMs) are prone to hallucination, especially during multi-hop and reasoning-intensive tasks such as mathematical problem solving. While Outcome Reward Models verify only final answers, Process Reward Models (PRMs) score each intermediate step to steer generation toward coherent solutions. We introduce PathFinder-PRM, a novel hierarchical, error-aware discriminative PRM that first classifies math and consistency errors at each step, then combines these fine-grained signals to estimate step correctness. To train PathFinder-PRM, we construct a 400K-sample dataset by enriching the human-annotated PRM800K corpus and RLHFlow Mistral traces with three-dimensional step-level labels. On PRMBench, PathFinder-PRM achieves a new state-of-the-art PRMScore of 67.7, outperforming the prior best (65.5) while using 3 times less data. When applied to reward guided greedy search, our model yields prm@8 48.3, a +1.5 point gain over the strongest baseline. These results demonstrate that decoupled error detection and reward estimation not only boost fine-grained error detection but also substantially improve end-to-end, reward-guided mathematical reasoning with greater data efficiency.
VeriFastScore: Speeding up long-form factuality evaluation
May 22, 2025Metrics like FactScore and VeriScore that evaluate long-form factuality operate by decomposing an input response into atomic claims and then individually verifying each claim. While effective and interpretable, these methods incur numerous LLM calls and can take upwards of 100 seconds to evaluate a single response, limiting their practicality in large-scale evaluation and training scenarios. To address this, we propose VeriFastScore, which leverages synthetic data to fine-tune Llama3.1 8B for simultaneously extracting and verifying all verifiable claims within a given text based on evidence from Google Search. We show that this task cannot be solved via few-shot prompting with closed LLMs due to its complexity: the model receives ~4K tokens of evidence on average and needs to concurrently decompose claims, judge their verifiability, and verify them against noisy evidence. However, our fine-tuned VeriFastScore model demonstrates strong correlation with the original VeriScore pipeline at both the example level (r=0.80) and system level (r=0.94) while achieving an overall speedup of 6.6x (9.9x excluding evidence retrieval) over VeriScore. To facilitate future factuality research, we publicly release our VeriFastScore model and synthetic datasets.