 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropose, Solve, Verify: Self-Play Through Formal Verification
Dec 20, 2025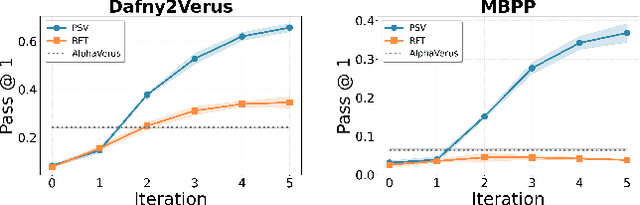
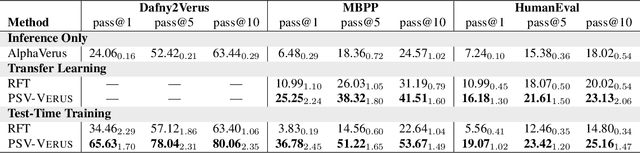
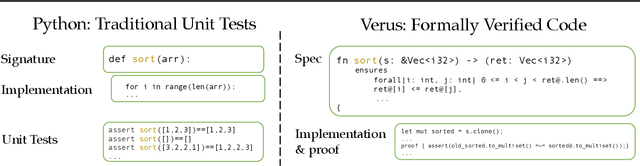

Training models through self-play alone (without any human data) has been a longstanding goal in AI, but its effectiveness for training large language models remains unclear, particularly in code generation where rewards based on unit tests are brittle and prone to error propagation. We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV) a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines. We show that performance scales with the number of generated questions and training iterations, and through ablations identify formal verification and difficulty-aware proposal as essential ingredients for successful self-play.
From Reproduction to Replication: Evaluating Research Agents with Progressive Code Masking
Jun 24, 2025Recent progress in autonomous code generation has fueled excitement around AI agents capable of accelerating scientific discovery by running experiments. However, there is currently no benchmark that evaluates whether such agents can implement scientific ideas when given varied amounts of code as a starting point, interpolating between reproduction (running code) and from-scratch replication (fully re-implementing and running code). We introduce AutoExperiment, a benchmark that evaluates AI agents' ability to implement and run machine learning experiments based on natural language descriptions in research papers. In each task, agents are given a research paper, a codebase with key functions masked out, and a command to run the experiment. The goal is to generate the missing code, execute the experiment in a sandboxed environment, and reproduce the results. AutoExperiment scales in difficulty by varying the number of missing functions $n$, ranging from partial reproduction to full replication. We evaluate state-of-the-art agents and find that performance degrades rapidly as $n$ increases. Agents that can dynamically interact with the environment (e.g. to debug their code) can outperform agents in fixed "agentless" harnesses, and there exists a significant gap between single-shot and multi-trial success rates (Pass@1 vs. Pass@5), motivating verifier approaches to our benchmark. Our findings highlight critical challenges in long-horizon code generation, context retrieval, and autonomous experiment execution, establishing AutoExperiment as a new benchmark for evaluating progress in AI-driven scientific experimentation. Our data and code are open-sourced at https://github.com/j1mk1m/AutoExperiment .
Think Twice: Perspective-Taking Improves Large Language Models' Theory-of-Mind Capabilities
Nov 16, 2023



Human interactions are deeply rooted in the interplay of thoughts, beliefs, and desires made possible by Theory of Mind (ToM): our cognitive ability to understand the mental states of ourselves and others. Although ToM may come naturally to us, emulating it presents a challenge to even the most advanced Large Language Models (LLMs). Recent improvements to LLMs' reasoning capabilities from simple yet effective prompting techniques such as Chain-of-Thought have seen limited applicability to ToM. In this paper, we turn to the prominent cognitive science theory "Simulation Theory" to bridge this gap. We introduce SimToM, a novel two-stage prompting framework inspired by Simulation Theory's notion of perspective-taking. To implement this idea on current ToM benchmarks, SimToM first filters context based on what the character in question knows before answering a question about their mental state. Our approach, which requires no additional training and minimal prompt-tuning, shows substantial improvement over existing methods, and our analysis reveals the importance of perspective-taking to Theory-of-Mind capabilities. Our findings suggest perspective-taking as a promising direction for future research into improving LLMs' ToM capabilities.
Comparative Knowledge Distillation
Nov 03, 2023



In the era of large scale pretrained models, Knowledge Distillation (KD) serves an important role in transferring the wisdom of computationally heavy teacher models to lightweight, efficient student models while preserving performance. Traditional KD paradigms, however, assume readily available access to teacher models for frequent inference -- a notion increasingly at odds with the realities of costly, often proprietary, large scale models. Addressing this gap, our paper considers how to minimize the dependency on teacher model inferences in KD in a setting we term Few Teacher Inference Knowledge Distillation (FTI KD). We observe that prevalent KD techniques and state of the art data augmentation strategies fall short in this constrained setting. Drawing inspiration from educational principles that emphasize learning through comparison, we propose Comparative Knowledge Distillation (CKD), which encourages student models to understand the nuanced differences in a teacher model's interpretations of samples. Critically, CKD provides additional learning signals to the student without making additional teacher calls. We also extend the principle of CKD to groups of samples, enabling even more efficient learning from limited teacher calls. Empirical evaluation across varied experimental settings indicates that CKD consistently outperforms state of the art data augmentation and KD techniques.
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023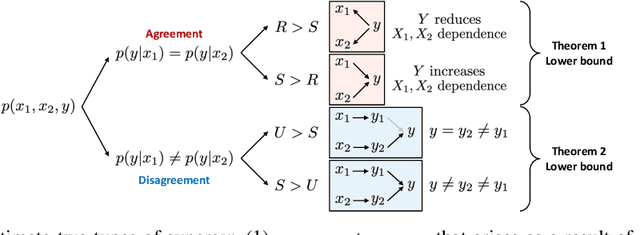
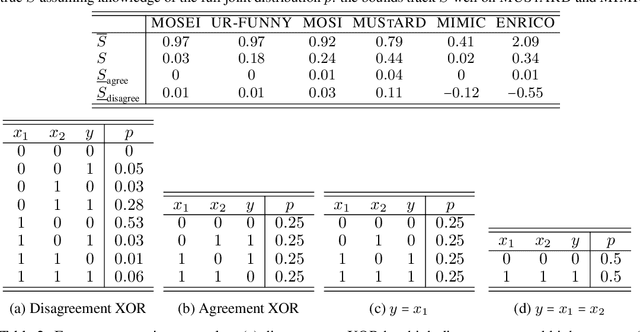
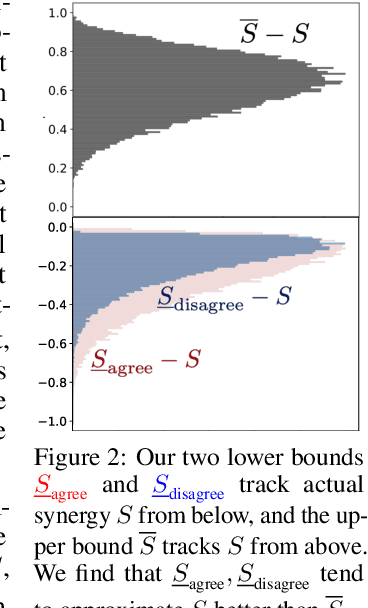
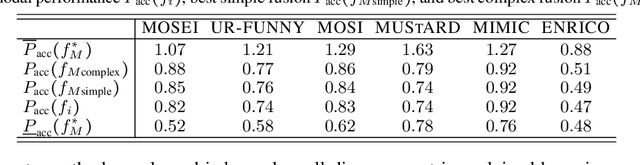
In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.
Difference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023
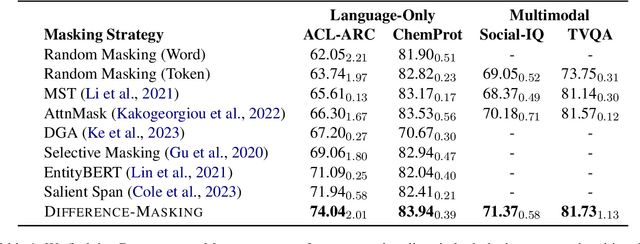
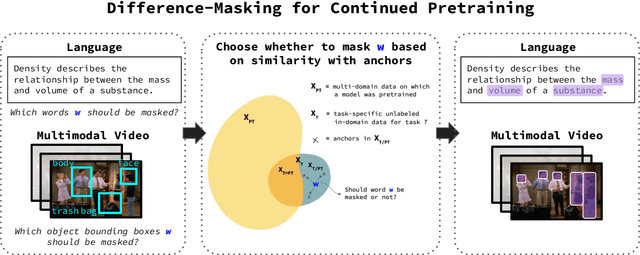
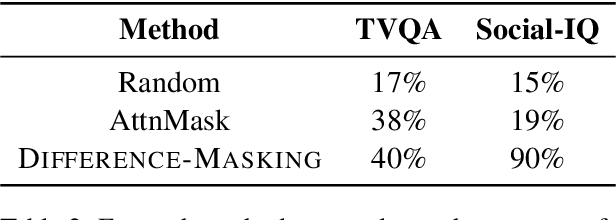
Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.
Face-to-Face Contrastive Learning for Social Intelligence Question-Answering
Aug 15, 2022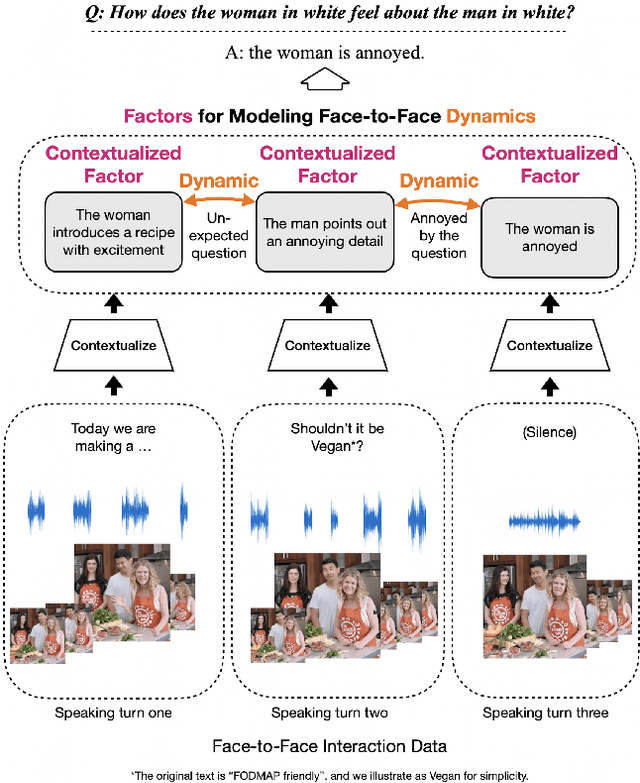
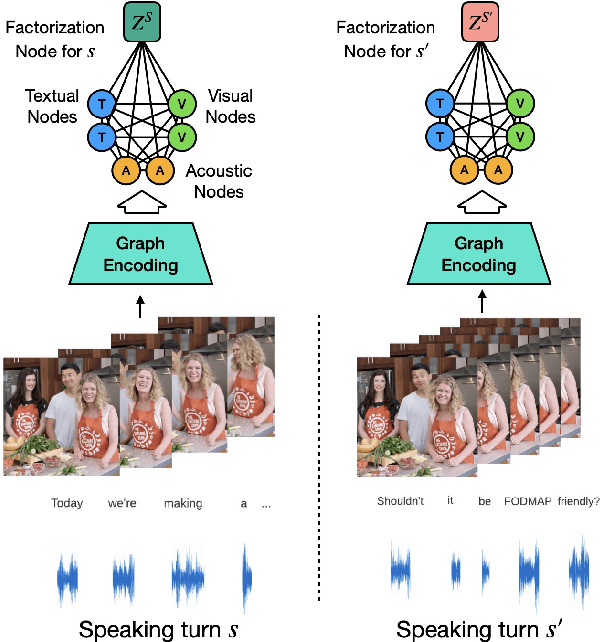
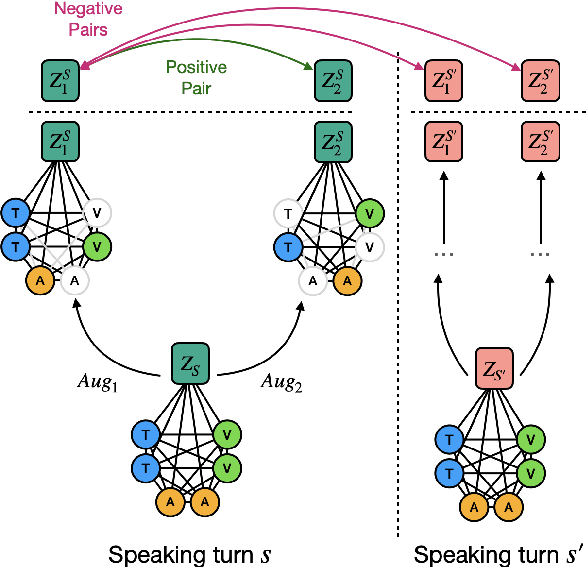
Creating artificial social intelligence - algorithms that can understand the nuances of multi-person interactions - is an exciting and emerging challenge in processing facial expressions and gestures from multimodal videos. Recent multimodal methods have set the state of the art on many tasks, but have difficulty modeling the complex face-to-face conversational dynamics across speaking turns in social interaction, particularly in a self-supervised setup. In this paper, we propose Face-to-Face Contrastive Learning (F2F-CL), a graph neural network designed to model social interactions using factorization nodes to contextualize the multimodal face-to-face interaction along the boundaries of the speaking turn. With the F2F-CL model, we propose to perform contrastive learning between the factorization nodes of different speaking turns within the same video. We experimentally evaluated the challenging Social-IQ dataset and show state-of-the-art results.
Dynamic Layer Customization for Noise Robust Speech Emotion Recognition in Heterogeneous Condition Training
Oct 21, 2020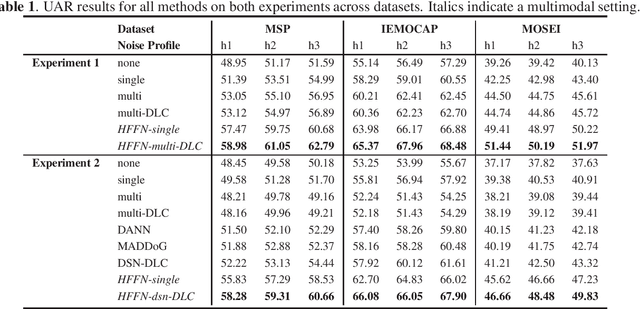
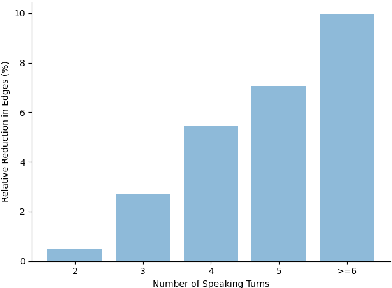
Robustness to environmental noise is important to creating automatic speech emotion recognition systems that are deployable in the real world. Prior work on noise robustness has assumed that systems would not make use of sample-by-sample training noise conditions, or that they would have access to unlabelled testing data to generalize across noise conditions. We avoid these assumptions and introduce the resulting task as heterogeneous condition training. We show that with full knowledge of the test noise conditions, we can improve performance by dynamically routing samples to specialized feature encoders for each noise condition, and with partial knowledge, we can use known noise conditions and domain adaptation algorithms to train systems that generalize well to unseen noise conditions. We then extend these improvements to the multimodal setting by dynamically routing samples to maintain temporal ordering, resulting in significant improvements over approaches that do not specialize or generalize based on noise type.