 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Layer Customization for Noise Robust Speech Emotion Recognition in Heterogeneous Condition Training
Paper and Code
Oct 21, 2020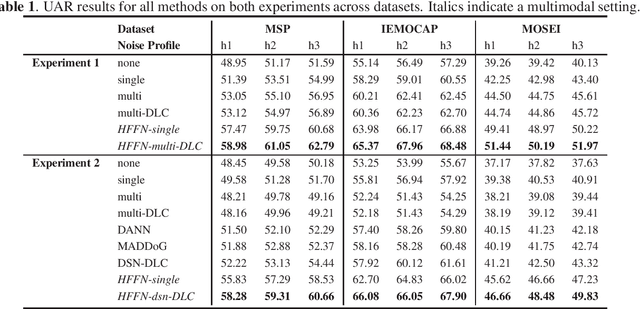
Robustness to environmental noise is important to creating automatic speech emotion recognition systems that are deployable in the real world. Prior work on noise robustness has assumed that systems would not make use of sample-by-sample training noise conditions, or that they would have access to unlabelled testing data to generalize across noise conditions. We avoid these assumptions and introduce the resulting task as heterogeneous condition training. We show that with full knowledge of the test noise conditions, we can improve performance by dynamically routing samples to specialized feature encoders for each noise condition, and with partial knowledge, we can use known noise conditions and domain adaptation algorithms to train systems that generalize well to unseen noise conditions. We then extend these improvements to the multimodal setting by dynamically routing samples to maintain temporal ordering, resulting in significant improvements over approaches that do not specialize or generalize based on noise type.