 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023
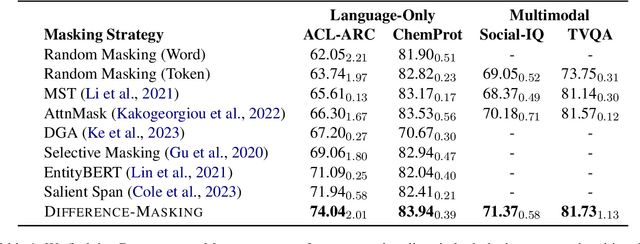
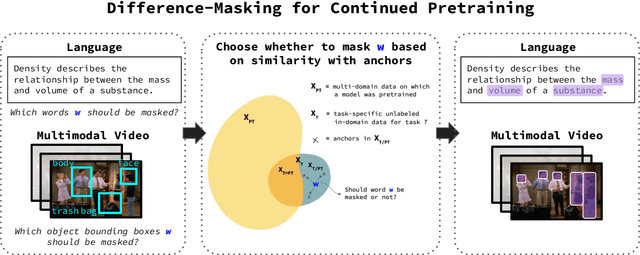
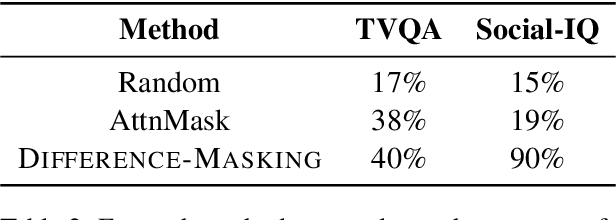
Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.