 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Caption: Evaluating Social Understanding in Multimodal Models
Jan 21, 2026Social understanding abilities are crucial for multimodal large language models (MLLMs) to interpret human social interactions. We introduce Social Caption, a framework grounded in interaction theory to evaluate social understanding abilities of MLLMs along three dimensions: Social Inference (SI), the ability to make accurate inferences about interactions; Holistic Social Analysis (HSA), the ability to generate comprehensive descriptions of interactions; Directed Social Analysis (DSA), the ability to extract relevant social information from interactions. We analyze factors influencing model performance in social understanding, such as scale, architectural design, and spoken context. Experiments with MLLM judges contribute insights about scaling automated evaluation of multimodal social understanding.
Social Genome: Grounded Social Reasoning Abilities of Multimodal Models
Feb 21, 2025Social reasoning abilities are crucial for AI systems to effectively interpret and respond to multimodal human communication and interaction within social contexts. We introduce Social Genome, the first benchmark for fine-grained, grounded social reasoning abilities of multimodal models. Social Genome contains 272 videos of interactions and 1,486 human-annotated reasoning traces related to inferences about these interactions. These traces contain 5,777 reasoning steps that reference evidence from visual cues, verbal cues, vocal cues, and external knowledge (contextual knowledge external to videos). Social Genome is also the first modeling challenge to study external knowledge in social reasoning. Social Genome computes metrics to holistically evaluate semantic and structural qualities of model-generated social reasoning traces. We demonstrate the utility of Social Genome through experiments with state-of-the-art models, identifying performance gaps and opportunities for future research to improve the grounded social reasoning abilities of multimodal models.
HEMM: Holistic Evaluation of Multimodal Foundation Models
Jul 03, 2024



Multimodal foundation models that can holistically process text alongside images, video, audio, and other sensory modalities are increasingly used in a variety of real-world applications. However, it is challenging to characterize and study progress in multimodal foundation models, given the range of possible modeling decisions, tasks, and domains. In this paper, we introduce Holistic Evaluation of Multimodal Models (HEMM) to systematically evaluate the capabilities of multimodal foundation models across a set of 3 dimensions: basic skills, information flow, and real-world use cases. Basic multimodal skills are internal abilities required to solve problems, such as learning interactions across modalities, fine-grained alignment, multi-step reasoning, and the ability to handle external knowledge. Information flow studies how multimodal content changes during a task through querying, translation, editing, and fusion. Use cases span domain-specific challenges introduced in real-world multimedia, affective computing, natural sciences, healthcare, and human-computer interaction applications. Through comprehensive experiments across the 30 tasks in HEMM, we (1) identify key dataset dimensions (e.g., basic skills, information flows, and use cases) that pose challenges to today's models, and (2) distill performance trends regarding how different modeling dimensions (e.g., scale, pre-training data, multimodal alignment, pre-training, and instruction tuning objectives) influence performance. Our conclusions regarding challenging multimodal interactions, use cases, and tasks requiring reasoning and external knowledge, the benefits of data and model scale, and the impacts of instruction tuning yield actionable insights for future work in multimodal foundation models.
Advancing Social Intelligence in AI Agents: Technical Challenges and Open Questions
Apr 17, 2024Building socially-intelligent AI agents (Social-AI) is a multidisciplinary, multimodal research goal that involves creating agents that can sense, perceive, reason about, learn from, and respond to affect, behavior, and cognition of other agents (human or artificial). Progress towards Social-AI has accelerated in the past decade across several computing communities, including natural language processing, machine learning, robotics, human-machine interaction, computer vision, and speech. Natural language processing, in particular, has been prominent in Social-AI research, as language plays a key role in constructing the social world. In this position paper, we identify a set of underlying technical challenges and open questions for researchers across computing communities to advance Social-AI. We anchor our discussion in the context of social intelligence concepts and prior progress in Social-AI research.
SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents
Oct 18, 2023



Humans are social beings; we pursue social goals in our daily interactions, which is a crucial aspect of social intelligence. Yet, AI systems' abilities in this realm remain elusive. We present SOTOPIA, an open-ended environment to simulate complex social interactions between artificial agents and evaluate their social intelligence. In our environment, agents role-play and interact under a wide variety of scenarios; they coordinate, collaborate, exchange, and compete with each other to achieve complex social goals. We simulate the role-play interaction between LLM-based agents and humans within this task space and evaluate their performance with a holistic evaluation framework called SOTOPIA-Eval. With SOTOPIA, we find significant differences between these models in terms of their social intelligence, and we identify a subset of SOTOPIA scenarios, SOTOPIA-hard, that is generally challenging for all models. We find that on this subset, GPT-4 achieves a significantly lower goal completion rate than humans and struggles to exhibit social commonsense reasoning and strategic communication skills. These findings demonstrate SOTOPIA's promise as a general platform for research on evaluating and improving social intelligence in artificial agents.
Difference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023
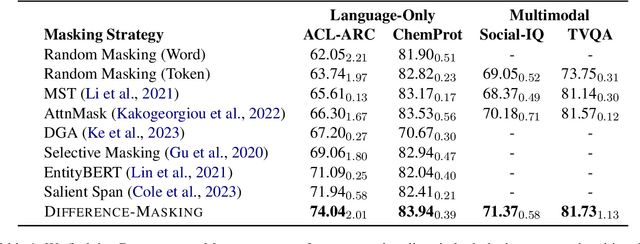
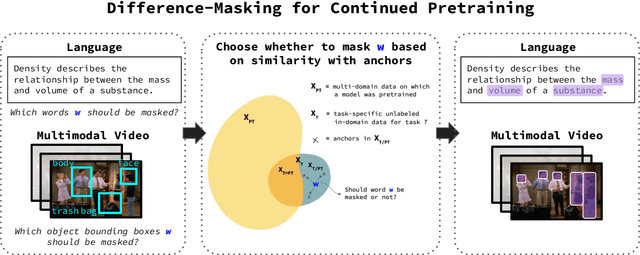
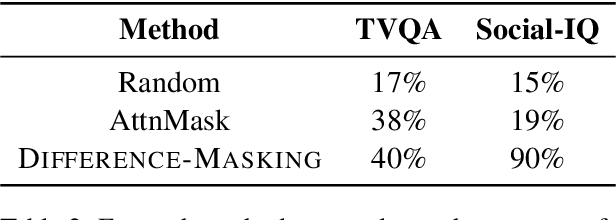
Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.
Expanding the Role of Affective Phenomena in Multimodal Interaction Research
May 18, 2023



In recent decades, the field of affective computing has made substantial progress in advancing the ability of AI systems to recognize and express affective phenomena, such as affect and emotions, during human-human and human-machine interactions. This paper describes our examination of research at the intersection of multimodal interaction and affective computing, with the objective of observing trends and identifying understudied areas. We examined over 16,000 papers from selected conferences in multimodal interaction, affective computing, and natural language processing: ACM International Conference on Multimodal Interaction, AAAC International Conference on Affective Computing and Intelligent Interaction, Annual Meeting of the Association for Computational Linguistics, and Conference on Empirical Methods in Natural Language Processing. We identified 910 affect-related papers and present our analysis of the role of affective phenomena in these papers. We find that this body of research has primarily focused on enabling machines to recognize and express affect and emotion. However, we find limited research on how affect and emotion predictions might be used by AI systems to enhance machine understanding of human social behaviors and cognitive states. Based on our analysis, we discuss directions to expand the role of affective phenomena in multimodal interaction research.
Towards Intercultural Affect Recognition: Audio-Visual Affect Recognition in the Wild Across Six Cultures
Jul 31, 2022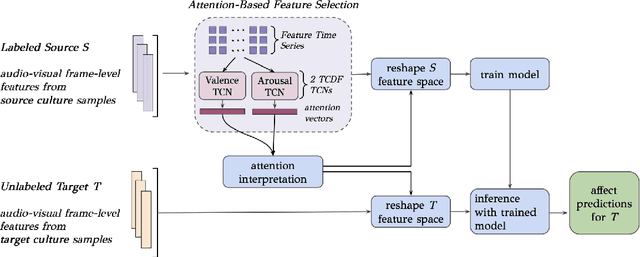

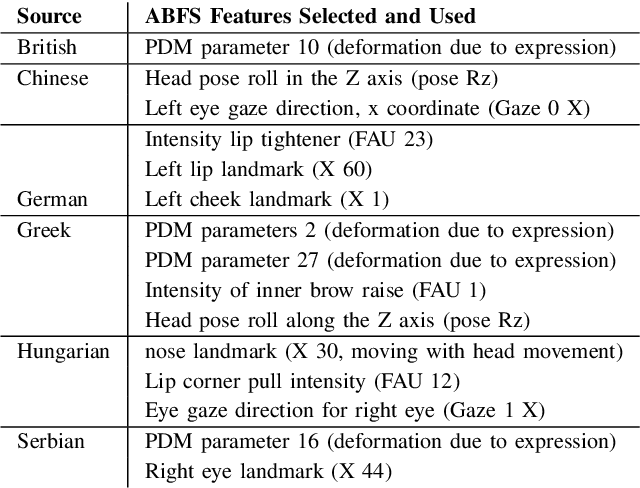
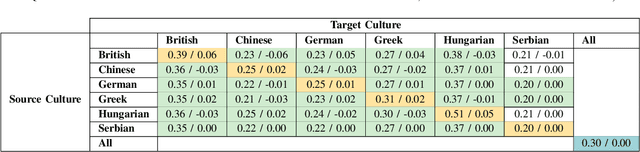
In our multicultural world, affect-aware AI systems that support humans need the ability to perceive affect across variations in emotion expression patterns across cultures. These models must perform well in cultural contexts on which they have not been trained. A standard assumption in affective computing is that affect recognition models trained and used within the same culture (intracultural) will perform better than models trained on one culture and used on different cultures (intercultural). We test this assumption and present the first systematic study of intercultural affect recognition models using videos of real-world dyadic interactions from six cultures. We develop an attention-based feature selection approach under temporal causal discovery to identify behavioral cues that can be leveraged in intercultural affect recognition models. Across all six cultures, our findings demonstrate that intercultural affect recognition models were as effective or more effective than intracultural models. We identify and contribute useful behavioral features for intercultural affect recognition; facial features from the visual modality were more useful than the audio modality in this study's context. Our paper presents a proof-of-concept and motivation for the future development of intercultural affect recognition systems.
Speech Representations and Phoneme Classification for Preserving the Endangered Language of Ladin
Aug 27, 2021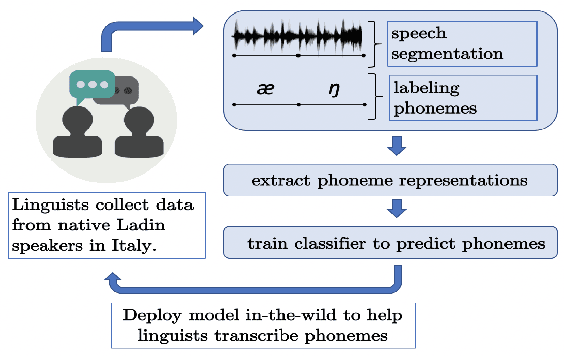
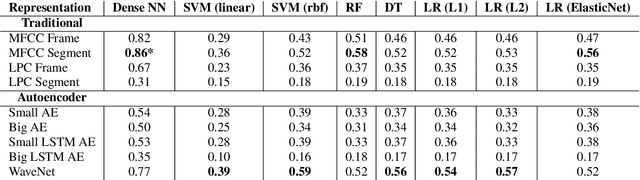
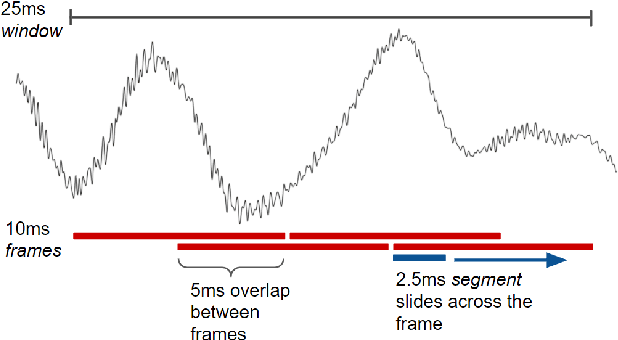
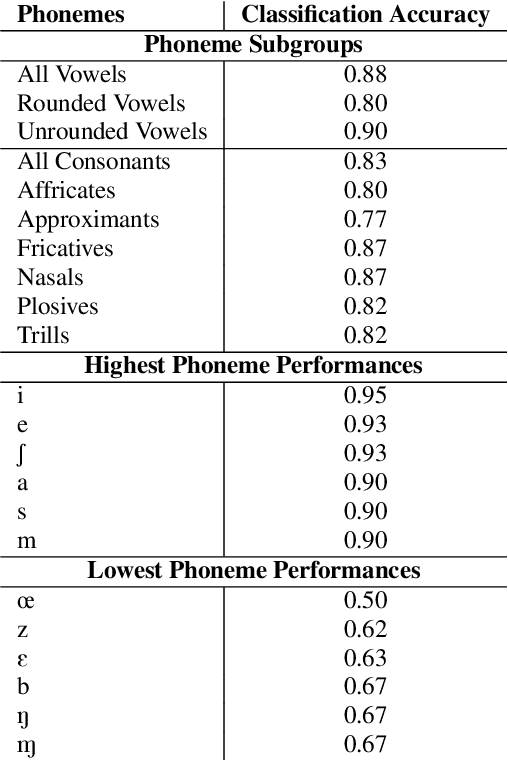
A vast majority of the world's 7,000 spoken languages are predicted to become extinct within this century, including the endangered language of Ladin from the Italian Alps. Linguists who work to preserve a language's phonetic and phonological structure can spend hours transcribing each minute of speech from native speakers. To address this problem in the context of Ladin, our paper presents the first analysis of speech representations and machine learning models for classifying 32 phonemes of Ladin. We experimented with a novel dataset of the Fascian dialect of Ladin, collected from native speakers in Italy. We created frame-level and segment-level speech feature extraction approaches and conducted extensive experiments with 8 different classifiers trained on 9 different speech representations. Our speech representations ranged from traditional features (MFCC, LPC) to features learned with deep neural network models (autoencoders, LSTM autoencoders, and WaveNet). Our highest-performing classifier, trained on MFCC representations of speech signals, achieved an 86% average accuracy across all Ladin phonemes. We also obtained average accuracies above 77% for all Ladin phoneme subgroups examined. Our findings contribute insights for learning discriminative Ladin phoneme representations and demonstrate the potential for leveraging machine learning and speech signal processing to preserve Ladin and other endangered languages.
Affect-Aware Deep Belief Network Representations for Multimodal Unsupervised Deception Detection
Aug 17, 2021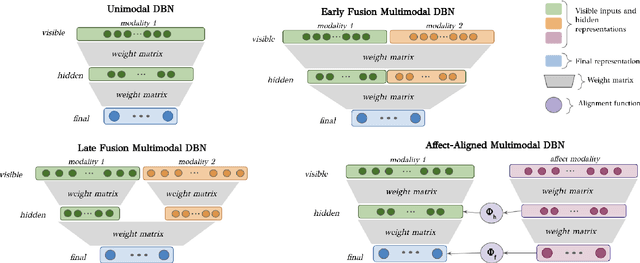
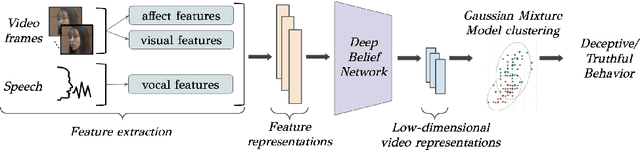
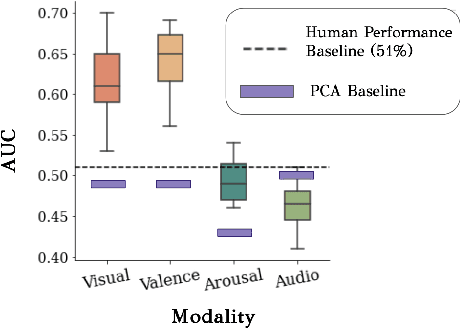
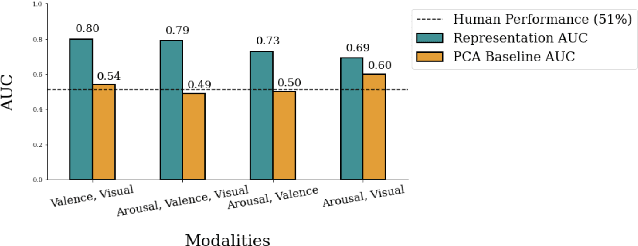
Automated systems that detect the social behavior of deception can enhance human well-being across medical, social work, and legal domains. Labeled datasets to train supervised deception detection models can rarely be collected for real-world, high-stakes contexts. To address this challenge, we propose the first unsupervised approach for detecting real-world, high-stakes deception in videos without requiring labels. This paper presents our novel approach for affect-aware unsupervised Deep Belief Networks (DBN) to learn discriminative representations of deceptive and truthful behavior. Drawing on psychology theories that link affect and deception, we experimented with unimodal and multimodal DBN-based approaches trained on facial valence, facial arousal, audio, and visual features. In addition to using facial affect as a feature on which DBN models are trained, we also introduce a DBN training procedure that uses facial affect as an aligner of audio-visual representations. We conducted classification experiments with unsupervised Gaussian Mixture Model clustering to evaluate our approaches. Our best unsupervised approach (trained on facial valence and visual features) achieved an AUC of 80%, outperforming human ability and performing comparably to fully-supervised models. Our results motivate future work on unsupervised, affect-aware computational approaches for detecting deception and other social behaviors in the wild.