 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSotopia-RL: Reward Design for Social Intelligence
Aug 05, 2025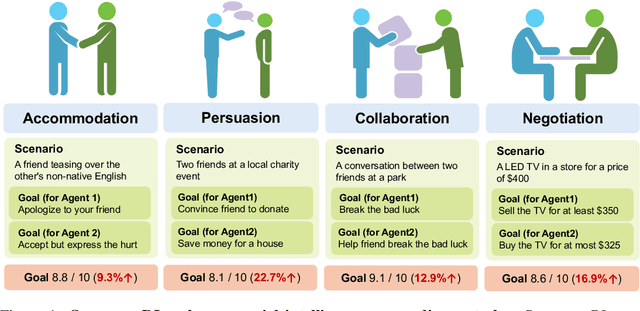
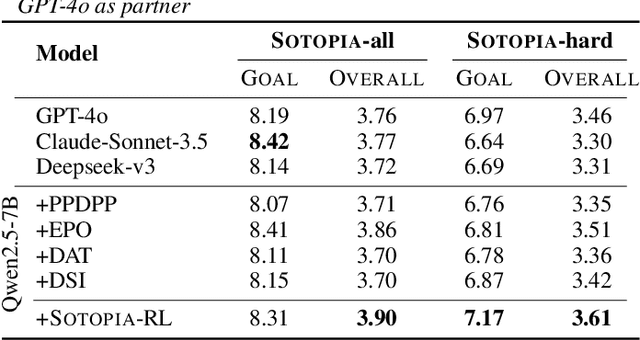
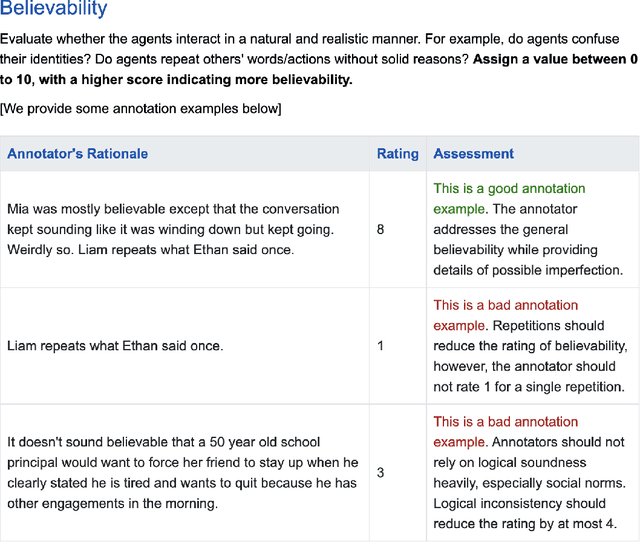
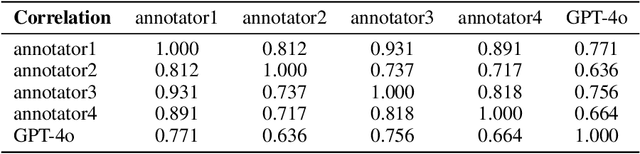
Social intelligence has become a critical capability for large language models (LLMs), enabling them to engage effectively in real-world social tasks such as accommodation, persuasion, collaboration, and negotiation. Reinforcement learning (RL) is a natural fit for training socially intelligent agents because it allows models to learn sophisticated strategies directly through social interactions. However, social interactions have two key characteristics that set barriers for RL training: (1) partial observability, where utterances have indirect and delayed effects that complicate credit assignment, and (2) multi-dimensionality, where behaviors such as rapport-building or knowledge-seeking contribute indirectly to goal achievement. These characteristics make Markov decision process (MDP)-based RL with single-dimensional episode-level rewards inefficient and unstable. To address these challenges, we propose Sotopia-RL, a novel framework that refines coarse episode-level feedback into utterance-level, multi-dimensional rewards. Utterance-level credit assignment mitigates partial observability by attributing outcomes to individual utterances, while multi-dimensional rewards capture the full richness of social interactions and reduce reward hacking. Experiments in Sotopia, an open-ended social learning environment, demonstrate that Sotopia-RL achieves state-of-the-art social goal completion scores (7.17 on Sotopia-hard and 8.31 on Sotopia-full), significantly outperforming existing approaches. Ablation studies confirm the necessity of both utterance-level credit assignment and multi-dimensional reward design for RL training. Our implementation is publicly available at: https://github.com/sotopia-lab/sotopia-rl.
TrojFlow: Flow Models are Natural Targets for Trojan Attacks
Dec 21, 2024



Flow-based generative models (FMs) have rapidly advanced as a method for mapping noise to data, its efficient training and sampling process makes it widely applicable in various fields. FMs can be viewed as a variant of diffusion models (DMs). At the same time, previous studies have shown that DMs are vulnerable to Trojan/Backdoor attacks, a type of output manipulation attack triggered by a maliciously embedded pattern at model input. We found that Trojan attacks on generative models are essentially equivalent to image transfer tasks from the backdoor distribution to the target distribution, the unique ability of FMs to fit any two arbitrary distributions significantly simplifies the training and sampling setups for attacking FMs, making them inherently natural targets for backdoor attacks. In this paper, we propose TrojFlow, exploring the vulnerabilities of FMs through Trojan attacks. In particular, we consider various attack settings and their combinations and thoroughly explore whether existing defense methods for DMs can effectively defend against our proposed attack scenarios. We evaluate TrojFlow on CIFAR-10 and CelebA datasets, our experiments show that our method can compromise FMs with high utility and specificity, and can easily break through existing defense mechanisms.
SOTOPIA-$π$: Interactive Learning of Socially Intelligent Language Agents
Mar 14, 2024Humans learn social skills through both imitation and social interaction. This social learning process is largely understudied by existing research on building language agents. Motivated by this gap, we propose an interactive learning method, SOTOPIA-$\pi$, improving the social intelligence of language agents. This method leverages behavior cloning and self-reinforcement training on filtered social interaction data according to large language model (LLM) ratings. We show that our training method allows a 7B LLM to reach the social goal completion ability of an expert model (GPT-4-based agent), while improving the safety of language agents and maintaining general QA ability on the MMLU benchmark. We also find that this training paradigm uncovers some difficulties in LLM-based evaluation of social intelligence: LLM-based evaluators overestimate the abilities of the language agents trained specifically for social interaction.
Long-Horizon Dialogue Understanding for Role Identification in the Game of Avalon with Large Language Models
Nov 09, 2023Deception and persuasion play a critical role in long-horizon dialogues between multiple parties, especially when the interests, goals, and motivations of the participants are not aligned. Such complex tasks pose challenges for current Large Language Models (LLM) as deception and persuasion can easily mislead them, especially in long-horizon multi-party dialogues. To this end, we explore the game of Avalon: The Resistance, a social deduction game in which players must determine each other's hidden identities to complete their team's objective. We introduce an online testbed and a dataset containing 20 carefully collected and labeled games among human players that exhibit long-horizon deception in a cooperative-competitive setting. We discuss the capabilities of LLMs to utilize deceptive long-horizon conversations between six human players to determine each player's goal and motivation. Particularly, we discuss the multimodal integration of the chat between the players and the game's state that grounds the conversation, providing further insights into the true player identities. We find that even current state-of-the-art LLMs do not reach human performance, making our dataset a compelling benchmark to investigate the decision-making and language-processing capabilities of LLMs. Our dataset and online testbed can be found at our project website: https://sstepput.github.io/Avalon-NLU/
SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents
Oct 18, 2023



Humans are social beings; we pursue social goals in our daily interactions, which is a crucial aspect of social intelligence. Yet, AI systems' abilities in this realm remain elusive. We present SOTOPIA, an open-ended environment to simulate complex social interactions between artificial agents and evaluate their social intelligence. In our environment, agents role-play and interact under a wide variety of scenarios; they coordinate, collaborate, exchange, and compete with each other to achieve complex social goals. We simulate the role-play interaction between LLM-based agents and humans within this task space and evaluate their performance with a holistic evaluation framework called SOTOPIA-Eval. With SOTOPIA, we find significant differences between these models in terms of their social intelligence, and we identify a subset of SOTOPIA scenarios, SOTOPIA-hard, that is generally challenging for all models. We find that on this subset, GPT-4 achieves a significantly lower goal completion rate than humans and struggles to exhibit social commonsense reasoning and strategic communication skills. These findings demonstrate SOTOPIA's promise as a general platform for research on evaluating and improving social intelligence in artificial agents.