 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Answer: Decoding the Behavior of LLMs as Scientific Reasoners
Mar 30, 2026As Large Language Models (LLMs) achieve increasingly sophisticated performance on complex reasoning tasks, current architectures serve as critical proxies for the internal heuristics of frontier models. Characterizing emergent reasoning is vital for long-term interpretability and safety. Furthermore, understanding how prompting modulates these processes is essential, as natural language will likely be the primary interface for interacting with AGI systems. In this work, we use a custom variant of Genetic Pareto (GEPA) to systematically optimize prompts for scientific reasoning tasks, and analyze how prompting can affect reasoning behavior. We investigate the structural patterns and logical heuristics inherent in GEPA-optimized prompts, and evaluate their transferability and brittleness. Our findings reveal that gains in scientific reasoning often correspond to model-specific heuristics that fail to generalize across systems, which we call "local" logic. By framing prompt optimization as a tool for model interpretability, we argue that mapping these preferred reasoning structures for LLMs is an important prerequisite for effectively collaborating with superhuman intelligence.
CircuitBuilder: From Polynomials to Circuits via Reinforcement Learning
Mar 17, 2026Motivated by auto-proof generation and Valiant's VP vs. VNP conjecture, we study the problem of discovering efficient arithmetic circuits to compute polynomials, using addition and multiplication gates. We formulate this problem as a single-player game, where an RL agent attempts to build the circuit within a fixed number of operations. We implement an AlphaZero-style training loop and compare two approaches: Proximal Policy Optimization with Monte Carlo Tree Search (PPO+MCTS) and Soft Actor-Critic (SAC). SAC achieves the highest success rates on two-variable targets, while PPO+MCTS scales to three variables and demonstrates steady improvement on harder instances. These results suggest that polynomial circuit synthesis is a compact, verifiable setting for studying self-improving search policies.
Predicting first-episode homelessness among US Veterans using longitudinal EHR data: time-varying models and social risk factors
Feb 02, 2026Homelessness among US veterans remains a critical public health challenge, yet risk prediction offers a pathway for proactive intervention. In this retrospective prognostic study, we analyzed electronic health record (EHR) data from 4,276,403 Veterans Affairs patients during a 2016 observation period to predict first-episode homelessness occurring 3-12 months later in 2017 (prevalence: 0.32-1.19%). We constructed static and time-varying EHR representations, utilizing clinician-informed logic to model the persistence of clinical conditions and social risks over time. We then compared the performance of classical machine learning, transformer-based masked language models, and fine-tuned large language models (LLMs). We demonstrate that incorporating social and behavioral factors into longitudinal models improved precision-recall area under the curve (PR-AUC) by 15-30%. In the top 1% risk tier, models yielded positive predictive values ranging from 3.93-4.72% at 3 months, 7.39-8.30% at 6 months, 9.84-11.41% at 9 months, and 11.65-13.80% at 12 months across model architectures. Large language models underperformed encoder-based models on discrimination but showed smaller performance disparities across racial groups. These results demonstrate that longitudinal, socially informed EHR modeling concentrates homelessness risk into actionable strata, enabling targeted and data-informed prevention strategies for at-risk veterans.
Amortized Inference for Model Rocket Aerodynamics: Learning to Estimate Physical Parameters from Simulation
Dec 24, 2025Accurate prediction of model rocket flight performance requires estimating aerodynamic parameters that are difficult to measure directly. Traditional approaches rely on computational fluid dynamics or empirical correlations, while data-driven methods require extensive real flight data that is expensive and time-consuming to collect. We present a simulation-based amortized inference approach that trains a neural network on synthetic flight data generated from a physics simulator, then applies the learned model to real flights without any fine-tuning. Our method learns to invert the forward physics model, directly predicting drag coefficient and thrust correction factor from a single apogee measurement combined with motor and configuration features. In this proof-of-concept study, we train on 10,000 synthetic flights and evaluate on 8 real flights, achieving a mean absolute error of 12.3 m in apogee prediction - demonstrating promising sim-to-real transfer with zero real training examples. Analysis reveals a systematic positive bias in predictions, providing quantitative insight into the gap between idealized physics and real-world flight conditions. We additionally compare against OpenRocket baseline predictions, showing that our learned approach reduces apogee prediction error. Our implementation is publicly available to support reproducibility and adoption in the amateur rocketry community.
gzip Predicts Data-dependent Scaling Laws
May 26, 2024Past work has established scaling laws that predict the performance of a neural language model (LM) as a function of its parameter count and the number of tokens it's trained on, enabling optimal allocation of a fixed compute budget. Are these scaling laws agnostic to training data as some prior work suggests? We generate training datasets of varying complexities by modulating the syntactic properties of a PCFG, finding that 1) scaling laws are sensitive to differences in data complexity and that 2) gzip, a compression algorithm, is an effective predictor of how data complexity impacts scaling properties. We propose a new data-dependent scaling law for LM's that accounts for the training data's gzip-compressibility; its compute-optimal frontier increases in dataset size preference (over parameter count preference) as training data becomes harder to compress.
Towards Vision-Language Mechanistic Interpretability: A Causal Tracing Tool for BLIP
Aug 27, 2023



Mechanistic interpretability seeks to understand the neural mechanisms that enable specific behaviors in Large Language Models (LLMs) by leveraging causality-based methods. While these approaches have identified neural circuits that copy spans of text, capture factual knowledge, and more, they remain unusable for multimodal models since adapting these tools to the vision-language domain requires considerable architectural changes. In this work, we adapt a unimodal causal tracing tool to BLIP to enable the study of the neural mechanisms underlying image-conditioned text generation. We demonstrate our approach on a visual question answering dataset, highlighting the causal relevance of later layer representations for all tokens. Furthermore, we release our BLIP causal tracing tool as open source to enable further experimentation in vision-language mechanistic interpretability by the community. Our code is available at https://github.com/vedantpalit/Towards-Vision-Language-Mechanistic-Interpretability.
Athena 2.0: Discourse and User Modeling in Open Domain Dialogue
Aug 03, 2023



Conversational agents are consistently growing in popularity and many people interact with them every day. While many conversational agents act as personal assistants, they can have many different goals. Some are task-oriented, such as providing customer support for a bank or making a reservation. Others are designed to be empathetic and to form emotional connections with the user. The Alexa Prize Challenge aims to create a socialbot, which allows the user to engage in coherent conversations, on a range of popular topics that will interest the user. Here we describe Athena 2.0, UCSC's conversational agent for Amazon's Socialbot Grand Challenge 4. Athena 2.0 utilizes a novel knowledge-grounded discourse model that tracks the entity links that Athena introduces into the dialogue, and uses them to constrain named-entity recognition and linking, and coreference resolution. Athena 2.0 also relies on a user model to personalize topic selection and other aspects of the conversation to individual users.
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023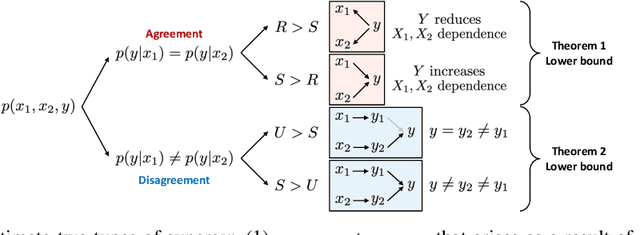
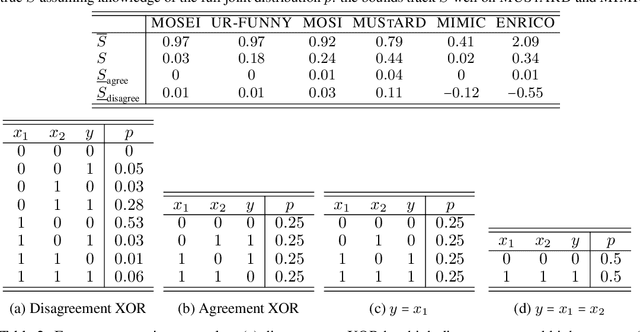
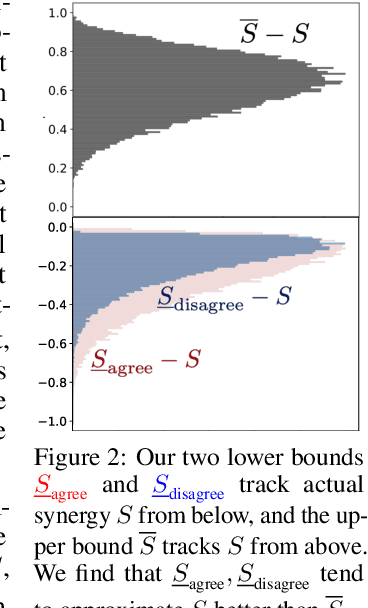
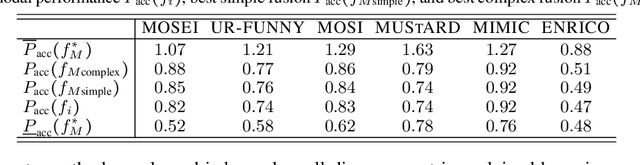
In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.
Semantic Composition in Visually Grounded Language Models
May 15, 2023What is sentence meaning and its ideal representation? Much of the expressive power of human language derives from semantic composition, the mind's ability to represent meaning hierarchically & relationally over constituents. At the same time, much sentential meaning is outside the text and requires grounding in sensory, motor, and experiential modalities to be adequately learned. Although large language models display considerable compositional ability, recent work shows that visually-grounded language models drastically fail to represent compositional structure. In this thesis, we explore whether & how models compose visually grounded semantics, and how we might improve their ability to do so. Specifically, we introduce 1) WinogroundVQA, a new compositional visual question answering benchmark, 2) Syntactic Neural Module Distillation, a measure of compositional ability in sentence embedding models, 3) Causal Tracing for Image Captioning Models to locate neural representations vital for vision-language composition, 4) Syntactic MeanPool to inject a compositional inductive bias into sentence embeddings, and 5) Cross-modal Attention Congruence Regularization, a self-supervised objective function for vision-language relation alignment. We close by discussing connections of our work to neuroscience, psycholinguistics, formal semantics, and philosophy.
Syntax-guided Neural Module Distillation to Probe Compositionality in Sentence Embeddings
Jan 21, 2023Past work probing compositionality in sentence embedding models faces issues determining the causal impact of implicit syntax representations. Given a sentence, we construct a neural module net based on its syntax parse and train it end-to-end to approximate the sentence's embedding generated by a transformer model. The distillability of a transformer to a Syntactic NeurAl Module Net (SynNaMoN) then captures whether syntax is a strong causal model of its compositional ability. Furthermore, we address questions about the geometry of semantic composition by specifying individual SynNaMoN modules' internal architecture & linearity. We find differences in the distillability of various sentence embedding models that broadly correlate with their performance, but observe that distillability doesn't considerably vary by model size. We also present preliminary evidence that much syntax-guided composition in sentence embedding models is linear, and that non-linearities may serve primarily to handle non-compositional phrases.