 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023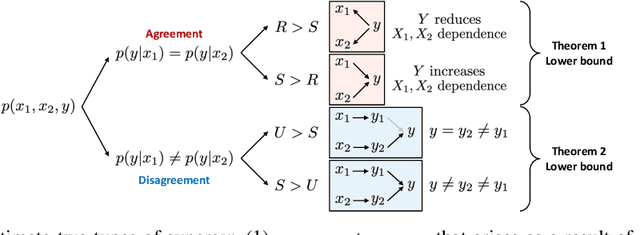
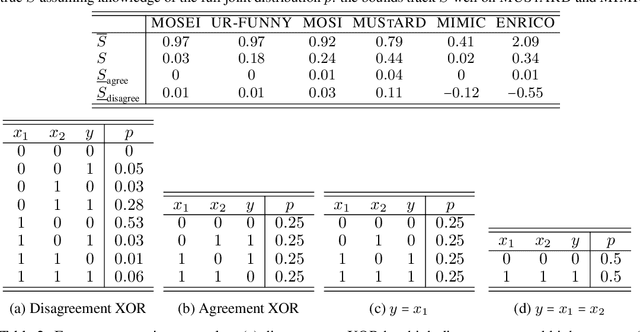
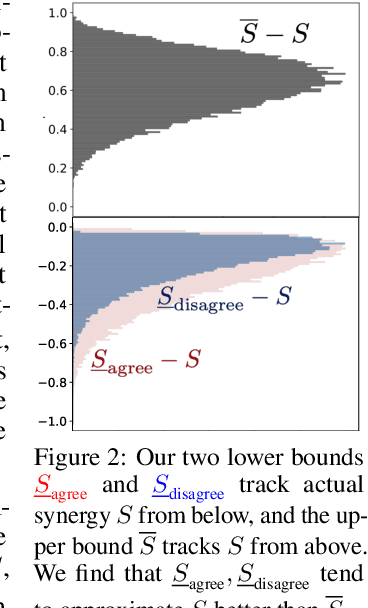
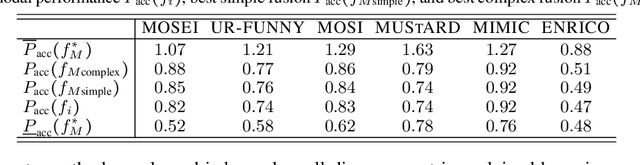
In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.