 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena 2.0: Discourse and User Modeling in Open Domain Dialogue
Aug 03, 2023



Conversational agents are consistently growing in popularity and many people interact with them every day. While many conversational agents act as personal assistants, they can have many different goals. Some are task-oriented, such as providing customer support for a bank or making a reservation. Others are designed to be empathetic and to form emotional connections with the user. The Alexa Prize Challenge aims to create a socialbot, which allows the user to engage in coherent conversations, on a range of popular topics that will interest the user. Here we describe Athena 2.0, UCSC's conversational agent for Amazon's Socialbot Grand Challenge 4. Athena 2.0 utilizes a novel knowledge-grounded discourse model that tracks the entity links that Athena introduces into the dialogue, and uses them to constrain named-entity recognition and linking, and coreference resolution. Athena 2.0 also relies on a user model to personalize topic selection and other aspects of the conversation to individual users.
A Transformer-based Response Evaluator for Open-Domain Spoken Conversation
Feb 09, 2023
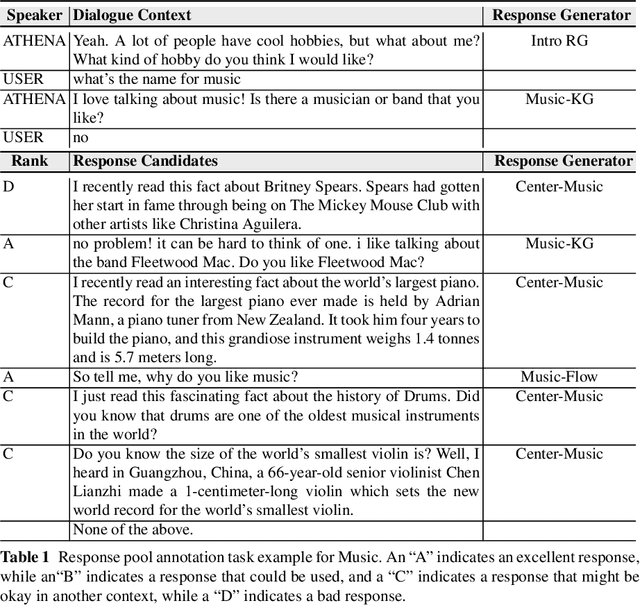

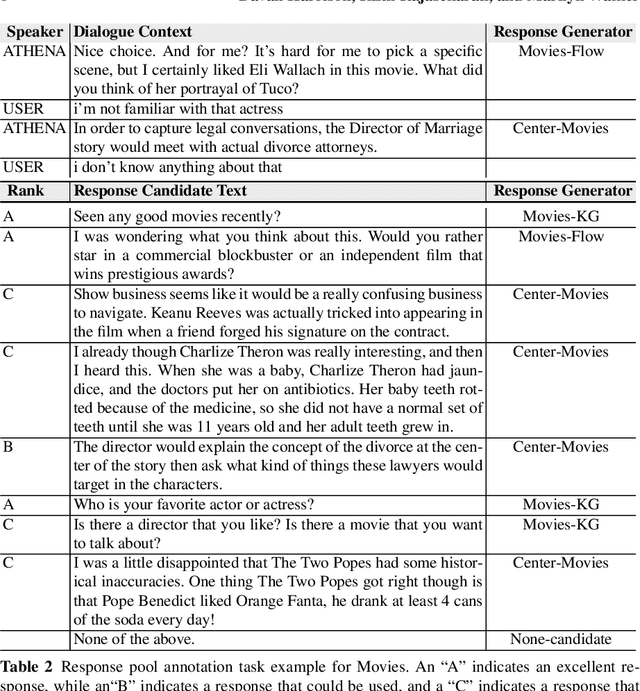
Many open-domain dialogue systems rely on multiple response generators, any of which can contribute a response to the dialogue in a particular context. Thus the ability to compare potential responses and then select the best plays an important role in ensuring a dialogue system is coherent and engaging. Dialogue coherence goes beyond simply remaining on topic -- some trivia may be on topic and engaging when mentioned out of the blue, but may not be coherent and grounded in the context of the conversation. We carry out experiments on response selection in the Athena system, an Alexa Prize SocialBot that has dedicated content and multiple topic-specific response generators for a large number of topics. First, we collect a corpus of Athena conversations with live human traffic, where potential responses from all enabled response generators are logged and subsequently annotated for response quality. We compare several off-the-shelf response ranking methods for open-domain dialogue to Athena-Heuristic, a heuristic response ranker that was field-tested in Athena during the third Alexa Prize competition. We also compare these to a transformer-based response ranker we call Athena-RR, that we train on our Athena conversations. Athena-RR uses both the conversational context and the dialogue state to rank the potential responses. We find that Athena-RR with a Recall@1 of 70.79\% outperforms Athena-Heuristic and all of the off-the-shelf rankers by a large margin. We then conduct a live A/B study comparing Athena-Heuristic to Athena-RR in a 6,358 conversations with Alexa users. We show that Athena-RR leads to significantly longer conversations that receive significantly higher user ratings than the heuristic rule-based ranker.
Athena 2.0: Contextualized Dialogue Management for an Alexa Prize SocialBot
Nov 03, 2021

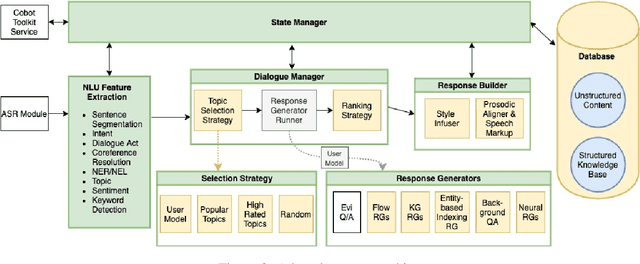
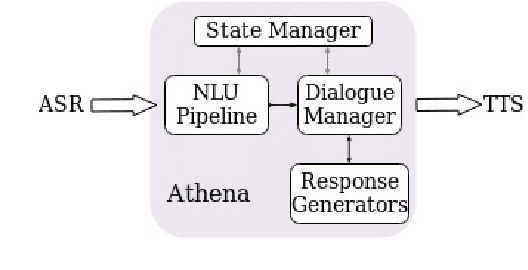
Athena 2.0 is an Alexa Prize SocialBot that has been a finalist in the last two Alexa Prize Grand Challenges. One reason for Athena's success is its novel dialogue management strategy, which allows it to dynamically construct dialogues and responses from component modules, leading to novel conversations with every interaction. Here we describe Athena's system design and performance in the Alexa Prize during the 20/21 competition. A live demo of Athena as well as video recordings will provoke discussion on the state of the art in conversational AI.
Athena: Constructing Dialogues Dynamically with Discourse Constraints
Nov 21, 2020
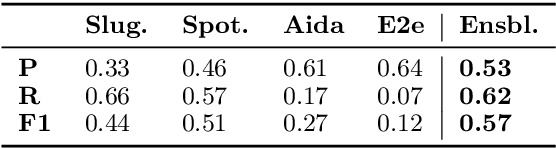

This report describes Athena, a dialogue system for spoken conversation on popular topics and current events. We develop a flexible topic-agnostic approach to dialogue management that dynamically configures dialogue based on general principles of entity and topic coherence. Athena's dialogue manager uses a contract-based method where discourse constraints are dispatched to clusters of response generators. This allows Athena to procure responses from dynamic sources, such as knowledge graph traversals and feature-based on-the-fly response retrieval methods. After describing the dialogue system architecture, we perform an analysis of conversations that Athena participated in during the 2019 Alexa Prize Competition. We conclude with a report on several user studies we carried out to better understand how individual user characteristics affect system ratings.
Learning from Mistakes: Combining Ontologies via Self-Training for Dialogue Generation
Sep 30, 2020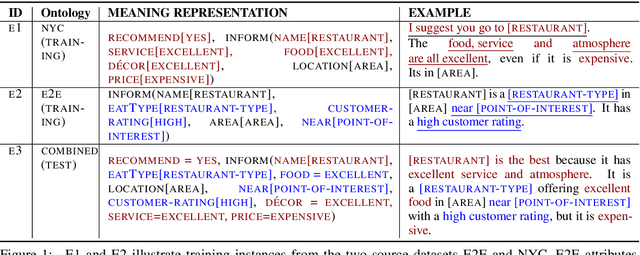
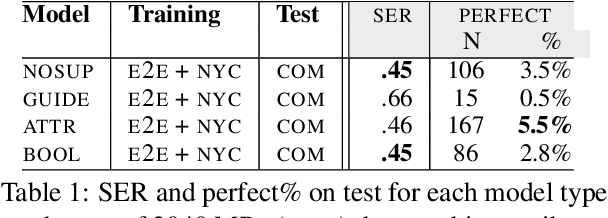
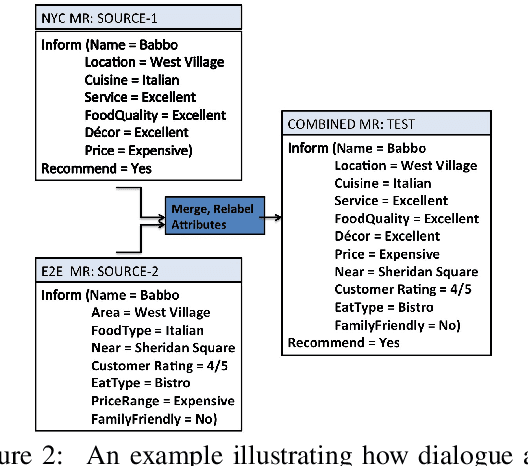
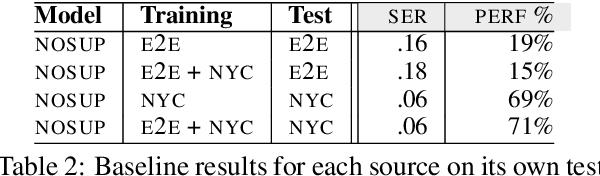
Natural language generators (NLGs) for task-oriented dialogue typically take a meaning representation (MR) as input. They are trained end-to-end with a corpus of MR/utterance pairs, where the MRs cover a specific set of dialogue acts and domain attributes. Creation of such datasets is labor-intensive and time-consuming. Therefore, dialogue systems for new domain ontologies would benefit from using data for pre-existing ontologies. Here we explore, for the first time, whether it is possible to train an NLG for a new larger ontology using existing training sets for the restaurant domain, where each set is based on a different ontology. We create a new, larger combined ontology, and then train an NLG to produce utterances covering it. For example, if one dataset has attributes for family-friendly and rating information, and the other has attributes for decor and service, our aim is an NLG for the combined ontology that can produce utterances that realize values for family-friendly, rating, decor and service. Initial experiments with a baseline neural sequence-to-sequence model show that this task is surprisingly challenging. We then develop a novel self-training method that identifies (errorful) model outputs, automatically constructs a corrected MR input to form a new (MR, utterance) training pair, and then repeatedly adds these new instances back into the training data. We then test the resulting model on a new test set. The result is a self-trained model whose performance is an absolute 75.4% improvement over the baseline model. We also report a human qualitative evaluation of the final model showing that it achieves high naturalness, semantic coherence and grammaticality
Entertaining and Opinionated but Too Controlling: A Large-Scale User Study of an Open Domain Alexa Prize System
Aug 13, 2019

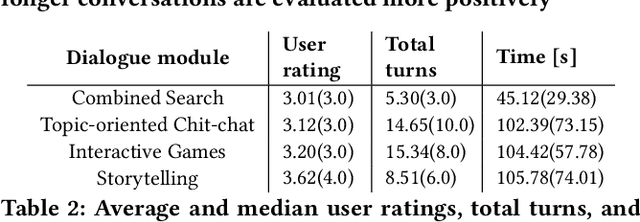
Conversational systems typically focus on functional tasks such as scheduling appointments or creating todo lists. Instead we design and evaluate SlugBot (SB), one of 8 semifinalists in the 2018 AlexaPrize, whose goal is to support casual open-domain social inter-action. This novel application requires both broad topic coverage and engaging interactive skills. We developed a new technical approach to meet this demanding situation by crowd-sourcing novel content and introducing playful conversational strategies based on storytelling and games. We collected over 10,000 conversations during August 2018 as part of the Alexa Prize competition. We also conducted an in-lab follow-up qualitative evaluation. Over-all users found SB moderately engaging; conversations averaged 3.6 minutes and involved 26 user turns. However, users reacted very differently to different conversation subtypes. Storytelling and games were evaluated positively; these were seen as entertaining with predictable interactive structure. They also led users to impute personality and intelligence to SB. In contrast, search and general Chit-Chat induced coverage problems; here users found it hard to infer what topics SB could understand, with these conversations seen as being too system-driven. Theoretical and design implications suggest a move away from conversational systems that simply provide factual information. Future systems should be designed to have their own opinions with personal stories to share, and SB provides an example of how we might achieve this.
SlugBot: Developing a Computational Model andFramework of a Novel Dialogue Genre
Jul 22, 2019
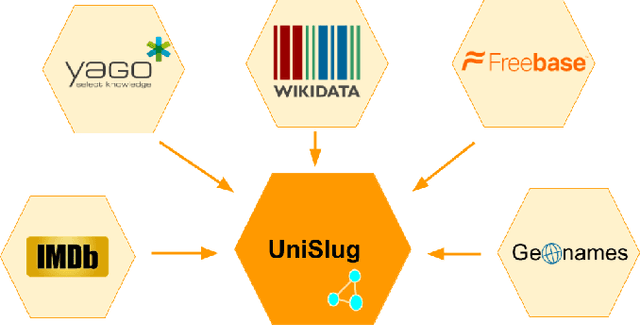
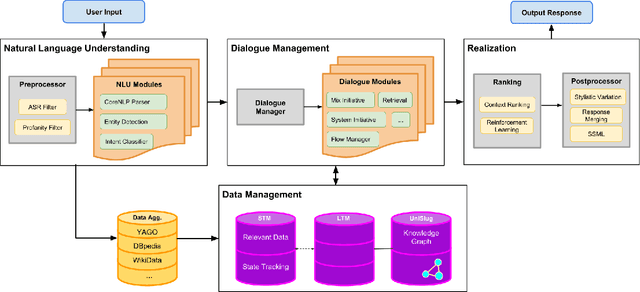

One of the most interesting aspects of the Amazon Alexa Prize competition is that the framing of the competition requires the development of new computational models of dialogue and its structure. Traditional computational models of dialogue are of two types: (1) task-oriented dialogue, supported by AI planning models,or simplified planning models consisting of frames with slots to be filled; or (2)search-oriented dialogue where every user turn is treated as a search query that may elaborate and extend current search results. Alexa Prize dialogue systems such as SlugBot must support conversational capabilities that go beyond what these traditional models can do. Moreover, while traditional dialogue systems rely on theoretical computational models, there are no existing computational theories that circumscribe the expected system and user behaviors in the intended conversational genre of the Alexa Prize Bots. This paper describes how UCSC's SlugBot team has combined the development of a novel computational theoretical model, Discourse Relation Dialogue Model, with its implementation in a modular system in order to test and refine it. We highlight how our novel dialogue model has led us to create a novel ontological resource, UniSlug, and how the structure of UniSlug determine show we curate and structure content so that our dialogue manager implements and tests our novel computational dialogue model.
Maximizing Stylistic Control and Semantic Accuracy in NLG: Personality Variation and Discourse Contrast
Jul 22, 2019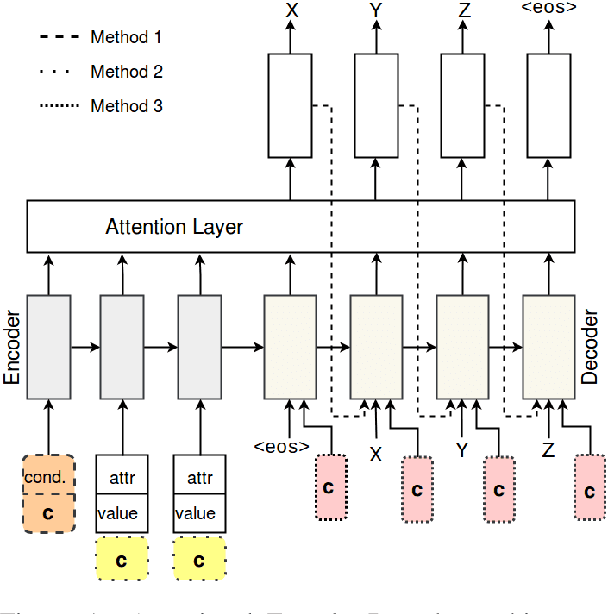

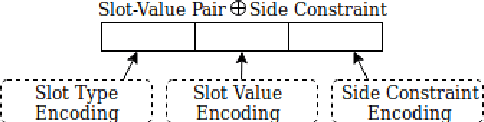

Neural generation methods for task-oriented dialogue typically generate from a meaning representation that is populated using a database of domain information, such as a table of data describing a restaurant. While earlier work focused solely on the semantic fidelity of outputs, recent work has started to explore methods for controlling the style of the generated text while simultaneously achieving semantic accuracy. Here we experiment with two stylistic benchmark tasks, generating language that exhibits variation in personality, and generating discourse contrast. We report a huge performance improvement in both stylistic control and semantic accuracy over the state of the art on both of these benchmarks. We test several different models and show that putting stylistic conditioning in the decoder and eliminating the semantic re-ranker used in earlier models results in more than 15 points higher BLEU for Personality, with a reduction of semantic error to near zero. We also report an improvement from .75 to .81 in controlling contrast and a reduction in semantic error from 16% to 2%.
Curate and Generate: A Corpus and Method for Joint Control of Semantics and Style in Neural NLG
Jun 14, 2019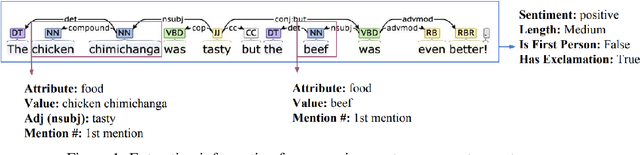


Neural natural language generation (NNLG) from structured meaning representations has become increasingly popular in recent years. While we have seen progress with generating syntactically correct utterances that preserve semantics, various shortcomings of NNLG systems are clear: new tasks require new training data which is not available or straightforward to acquire, and model outputs are simple and may be dull and repetitive. This paper addresses these two critical challenges in NNLG by: (1) scalably (and at no cost) creating training datasets of parallel meaning representations and reference texts with rich style markup by using data from freely available and naturally descriptive user reviews, and (2) systematically exploring how the style markup enables joint control of semantic and stylistic aspects of neural model output. We present YelpNLG, a corpus of 300,000 rich, parallel meaning representations and highly stylistically varied reference texts spanning different restaurant attributes, and describe a novel methodology that can be scalably reused to generate NLG datasets for other domains. The experiments show that the models control important aspects, including lexical choice of adjectives, output length, and sentiment, allowing the models to successfully hit multiple style targets without sacrificing semantics.
Neural Generation of Diverse Questions using Answer Focus, Contextual and Linguistic Features
Oct 05, 2018
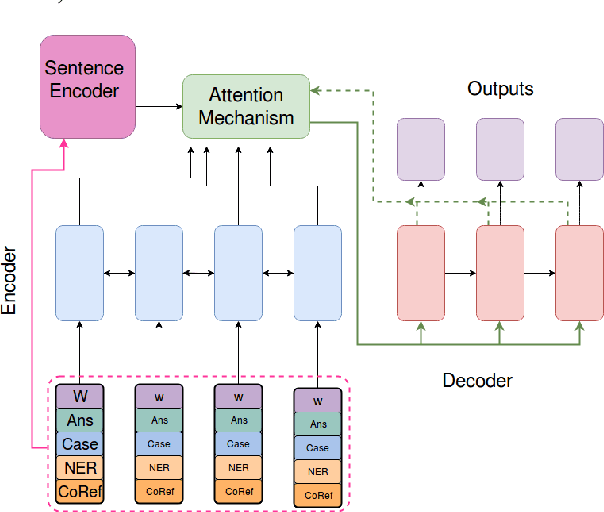

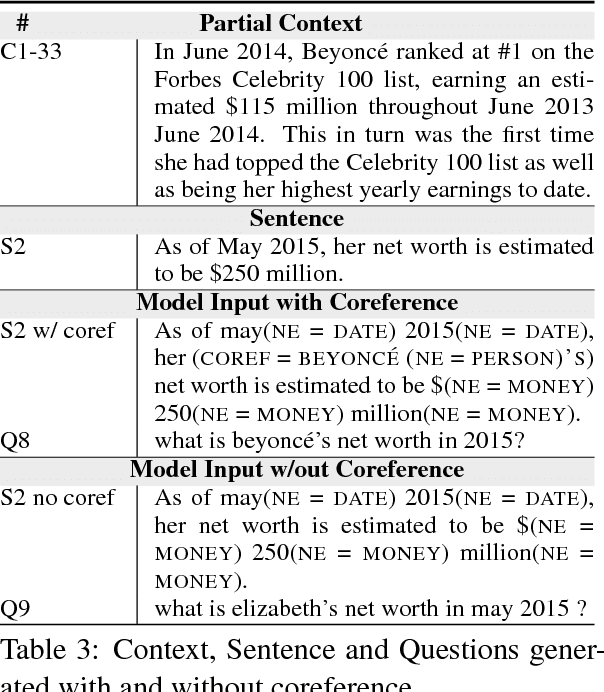
Question Generation is the task of automatically creating questions from textual input. In this work we present a new Attentional Encoder--Decoder Recurrent Neural Network model for automatic question generation. Our model incorporates linguistic features and an additional sentence embedding to capture meaning at both sentence and word levels. The linguistic features are designed to capture information related to named entity recognition, word case, and entity coreference resolution. In addition our model uses a copying mechanism and a special answer signal that enables generation of numerous diverse questions on a given sentence. Our model achieves state of the art results of 19.98 Bleu_4 on a benchmark Question Generation dataset, outperforming all previously published results by a significant margin. A human evaluation also shows that these added features improve the quality of the generated questions.