 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer-based Response Evaluator for Open-Domain Spoken Conversation
Paper and Code

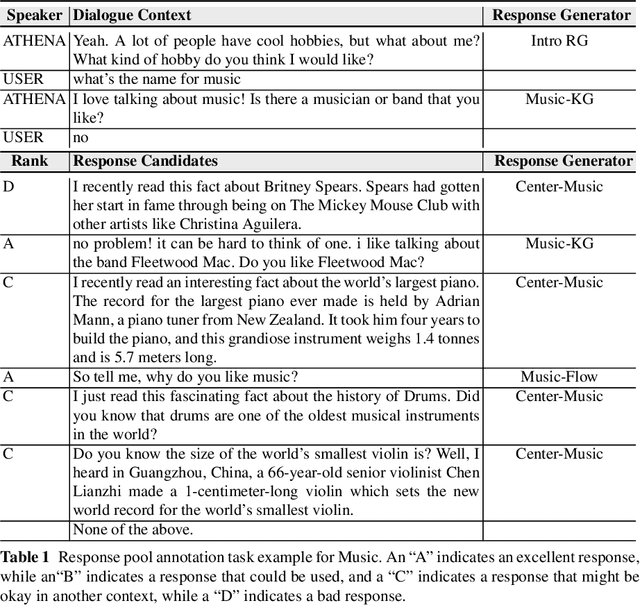

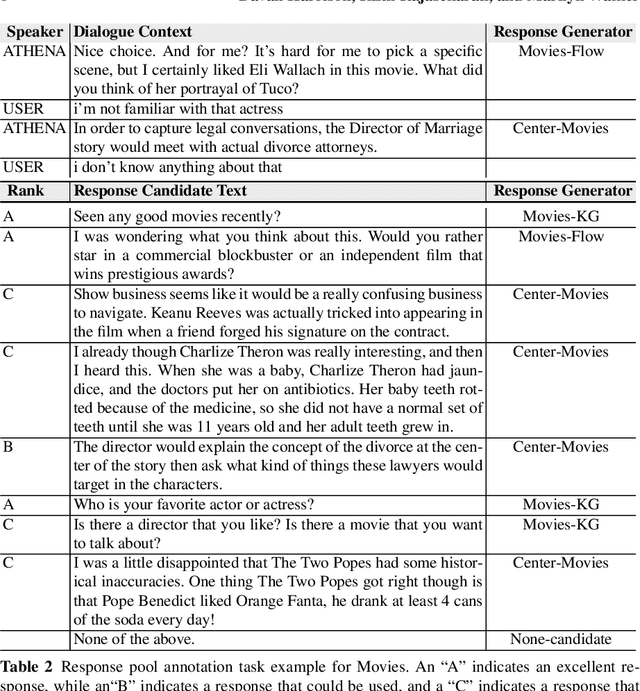
Many open-domain dialogue systems rely on multiple response generators, any of which can contribute a response to the dialogue in a particular context. Thus the ability to compare potential responses and then select the best plays an important role in ensuring a dialogue system is coherent and engaging. Dialogue coherence goes beyond simply remaining on topic -- some trivia may be on topic and engaging when mentioned out of the blue, but may not be coherent and grounded in the context of the conversation. We carry out experiments on response selection in the Athena system, an Alexa Prize SocialBot that has dedicated content and multiple topic-specific response generators for a large number of topics. First, we collect a corpus of Athena conversations with live human traffic, where potential responses from all enabled response generators are logged and subsequently annotated for response quality. We compare several off-the-shelf response ranking methods for open-domain dialogue to Athena-Heuristic, a heuristic response ranker that was field-tested in Athena during the third Alexa Prize competition. We also compare these to a transformer-based response ranker we call Athena-RR, that we train on our Athena conversations. Athena-RR uses both the conversational context and the dialogue state to rank the potential responses. We find that Athena-RR with a Recall@1 of 70.79\% outperforms Athena-Heuristic and all of the off-the-shelf rankers by a large margin. We then conduct a live A/B study comparing Athena-Heuristic to Athena-RR in a 6,358 conversations with Alexa users. We show that Athena-RR leads to significantly longer conversations that receive significantly higher user ratings than the heuristic rule-based ranker.