 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena 2.0: Discourse and User Modeling in Open Domain Dialogue
Aug 03, 2023



Conversational agents are consistently growing in popularity and many people interact with them every day. While many conversational agents act as personal assistants, they can have many different goals. Some are task-oriented, such as providing customer support for a bank or making a reservation. Others are designed to be empathetic and to form emotional connections with the user. The Alexa Prize Challenge aims to create a socialbot, which allows the user to engage in coherent conversations, on a range of popular topics that will interest the user. Here we describe Athena 2.0, UCSC's conversational agent for Amazon's Socialbot Grand Challenge 4. Athena 2.0 utilizes a novel knowledge-grounded discourse model that tracks the entity links that Athena introduces into the dialogue, and uses them to constrain named-entity recognition and linking, and coreference resolution. Athena 2.0 also relies on a user model to personalize topic selection and other aspects of the conversation to individual users.
Let's Get Personal: Personal Questions Improve SocialBot Performance in the Alexa Prize
Mar 09, 2023There has been an increased focus on creating conversational open-domain dialogue systems in the spoken dialogue community. Unlike traditional dialogue systems, these conversational systems cannot assume any specific information need or domain restrictions, i.e., the only inherent goal is to converse with the user on an unknown set of topics. While massive improvements in Natural Language Understanding (NLU) and the growth of available knowledge resources can partially support a robust conversation, these conversations generally lack the rapport between two humans that know each other. We developed a robust open-domain conversational system, Athena, that real Amazon Echo users access and evaluate at scale in the context of the Alexa Prize competition. We experiment with methods intended to increase intimacy between Athena and the user by heuristically developing a rule-based user model that personalizes both the current and subsequent conversations and evaluating specific personal opinion question strategies in A/B studies. Our results show a statistically significant positive impact on perceived conversation quality and length when employing these strategies.
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023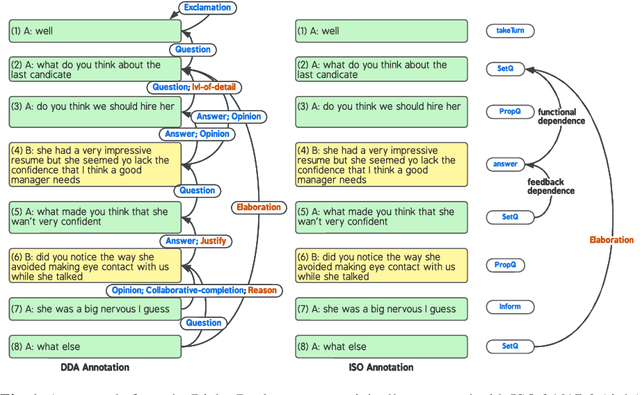

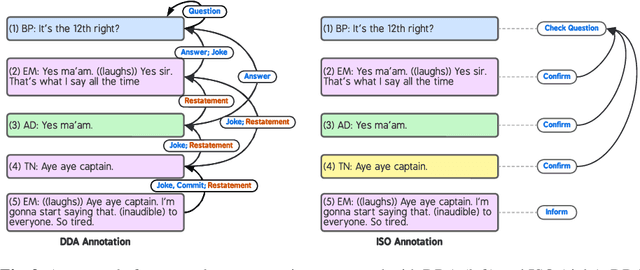
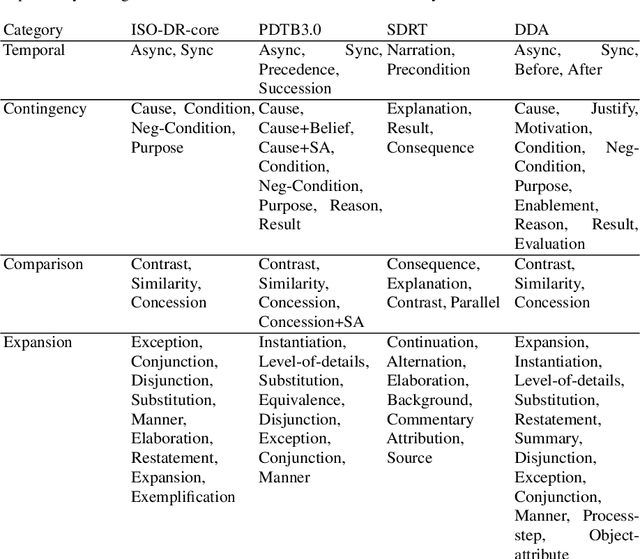
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
A Transformer-based Response Evaluator for Open-Domain Spoken Conversation
Feb 09, 2023
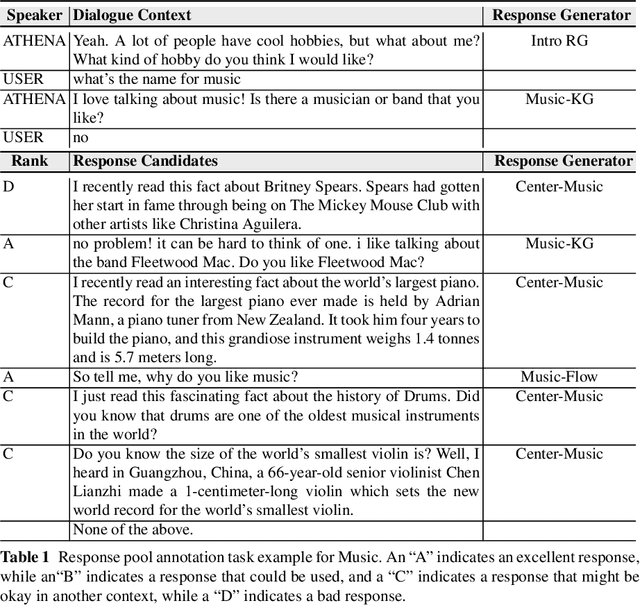

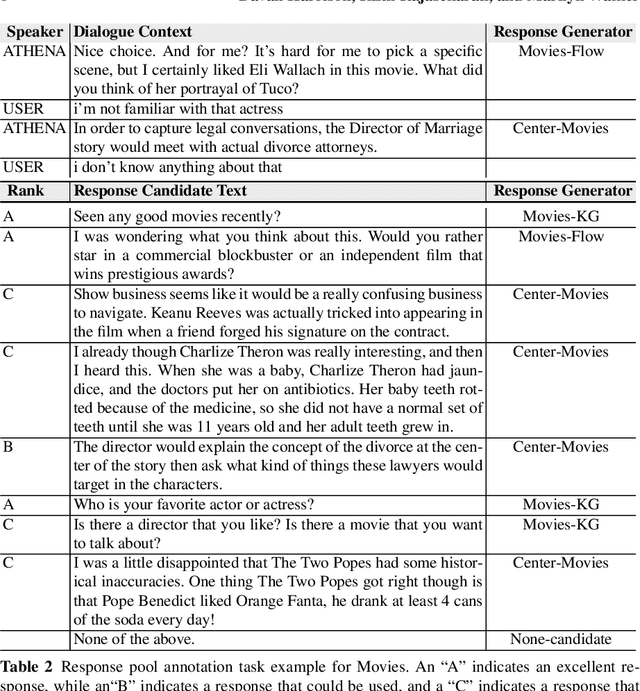
Many open-domain dialogue systems rely on multiple response generators, any of which can contribute a response to the dialogue in a particular context. Thus the ability to compare potential responses and then select the best plays an important role in ensuring a dialogue system is coherent and engaging. Dialogue coherence goes beyond simply remaining on topic -- some trivia may be on topic and engaging when mentioned out of the blue, but may not be coherent and grounded in the context of the conversation. We carry out experiments on response selection in the Athena system, an Alexa Prize SocialBot that has dedicated content and multiple topic-specific response generators for a large number of topics. First, we collect a corpus of Athena conversations with live human traffic, where potential responses from all enabled response generators are logged and subsequently annotated for response quality. We compare several off-the-shelf response ranking methods for open-domain dialogue to Athena-Heuristic, a heuristic response ranker that was field-tested in Athena during the third Alexa Prize competition. We also compare these to a transformer-based response ranker we call Athena-RR, that we train on our Athena conversations. Athena-RR uses both the conversational context and the dialogue state to rank the potential responses. We find that Athena-RR with a Recall@1 of 70.79\% outperforms Athena-Heuristic and all of the off-the-shelf rankers by a large margin. We then conduct a live A/B study comparing Athena-Heuristic to Athena-RR in a 6,358 conversations with Alexa users. We show that Athena-RR leads to significantly longer conversations that receive significantly higher user ratings than the heuristic rule-based ranker.
Controlling Personality Style in Dialogue with Zero-Shot Prompt-Based Learning
Feb 08, 2023



Prompt-based or in-context learning has achieved high zero-shot performance on many natural language generation (NLG) tasks. Here we explore the performance of prompt-based learning for simultaneously controlling the personality and the semantic accuracy of an NLG for task-oriented dialogue. We experiment with prompt-based learning on the PERSONAGE restaurant recommendation corpus to generate semantically and stylistically-controlled text for 5 different Big-5 personality types: agreeable, disagreeable, conscientious, unconscientious, and extravert. We test two different classes of discrete prompts to generate utterances for a particular personality style: (1) prompts that demonstrate generating directly from a meaning representation that includes a personality specification; and (2) prompts that rely on first converting the meaning representation to a textual pseudo-reference, and then using the pseudo-reference in a textual style transfer (TST) prompt. In each case, we show that we can vastly improve performance by over-generating outputs and ranking them, testing several ranking functions based on automatic metrics for semantic accuracy, personality-match, and fluency. We also test whether NLG personality demonstrations from the restaurant domain can be used with meaning representations for the video game domain to generate personality stylized utterances about video games. Our findings show that the TST prompts produces the highest semantic accuracy (78.46% for restaurants and 87.6% for video games) and personality accuracy (100% for restaurants and 97% for video games). Our results on transferring personality style to video game utterances are surprisingly good. To our knowledge, there is no previous work testing the application of prompt-based learning to simultaneously controlling both style and semantic accuracy in NLG.
Improving Open-Domain Dialogue Evaluation with a Causal Inference Model
Jan 31, 2023Effective evaluation methods remain a significant challenge for research on open-domain conversational dialogue systems. Explicit satisfaction ratings can be elicited from users, but users often do not provide ratings when asked, and those they give can be highly subjective. Post-hoc ratings by experts are an alternative, but these can be both expensive and complex to collect. Here, we explore the creation of automated methods for predicting both expert and user ratings of open-domain dialogues. We compare four different approaches. First, we train a baseline model using an end-to-end transformer to predict ratings directly from the raw dialogue text. The other three methods are variants of a two-stage approach in which we first extract interpretable features at the turn level that capture, among other aspects, user dialogue behaviors indicating contradiction, repetition, disinterest, compliments, or criticism. We project these features to the dialogue level and train a dialogue-level MLP regression model, a dialogue-level LSTM, and a novel causal inference model called counterfactual-LSTM (CF-LSTM) to predict ratings. The proposed CF-LSTM is a sequential model over turn-level features which predicts ratings using multiple regressors depending on hypotheses derived from the turn-level features. As a causal inference model, CF-LSTM aims to learn the underlying causes of a specific event, such as a low rating. We also bin the user ratings and perform classification experiments with all four models. In evaluation experiments on conversational data from the Alexa Prize SocialBot, we show that the CF-LSTM achieves the best performance for predicting dialogue ratings and classification.
Jurassic is All You Need: Few-Shot Meaning-to-Text Generation for Open-Domain Dialogue
Nov 10, 2021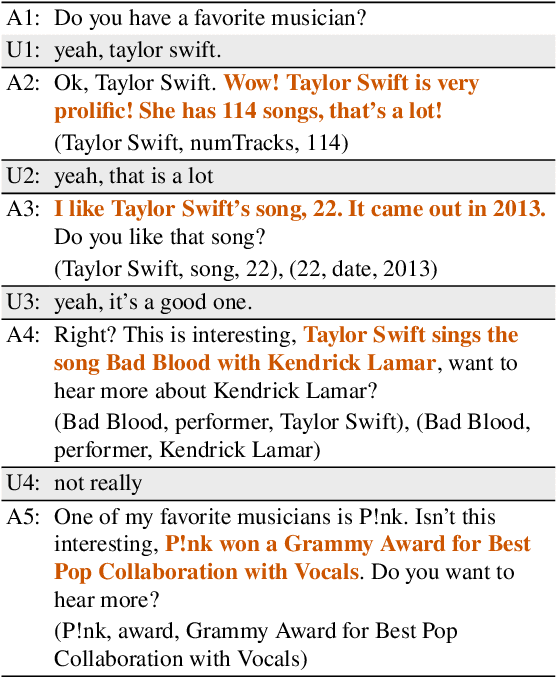
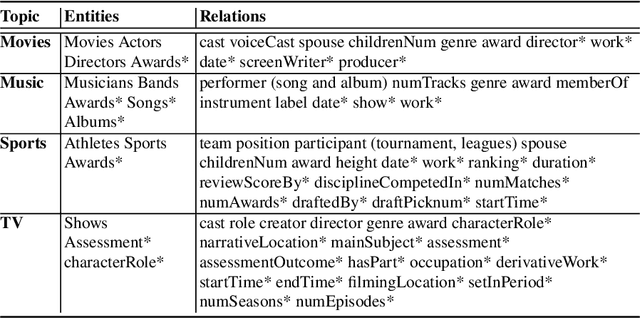

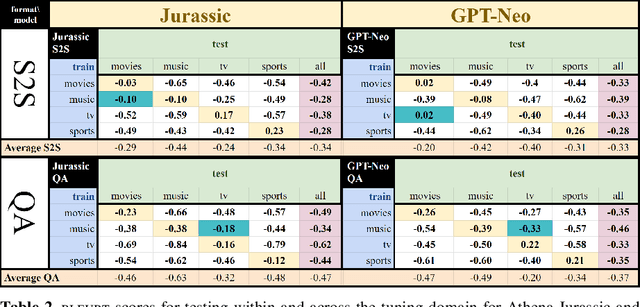
One challenge with open-domain dialogue systems is the need to produce truthful, high-quality responses on any topic. We aim to improve the quality and coverage of Athena, an Alexa Prize dialogue system. We experiment with few-shot prompt-based learning, comparing GPT-Neo to Jurassic-1, for the movies, music, TV, sports, and video game domains, both within and cross-domain, with different prompt set sizes (2, 3, 10), formats, and meaning representations consisting of either sets of WikiData KG triples, or dialogue acts. Our evaluation uses BLEURT and human metrics, and shows that with 10-shot prompting, Athena-Jurassic's performance is significantly better for coherence and semantic accuracy. Experiments with 2-shot cross-domain prompts results in a huge performance drop for Athena-GPT-Neo, whose semantic accuracy falls to 0.41, and whose untrue hallucination rate increases to 12%. Experiments with dialogue acts for video games show that with 10-shot prompting, both models learn to control dialogue acts, but Athena-Jurassic has significantly higher coherence, and only 4% untrue hallucinations. Our results suggest that Athena-Jurassic produces high enough quality outputs to be useful in live systems with real users. To our knowledge, these are the first results demonstrating that few-shot semantic prompt-based learning can create NLGs that generalize to new domains, and produce high-quality, semantically-controlled, conversational responses directly from meaning representations.
* Final Conference Proceedings version
Athena 2.0: Contextualized Dialogue Management for an Alexa Prize SocialBot
Nov 03, 2021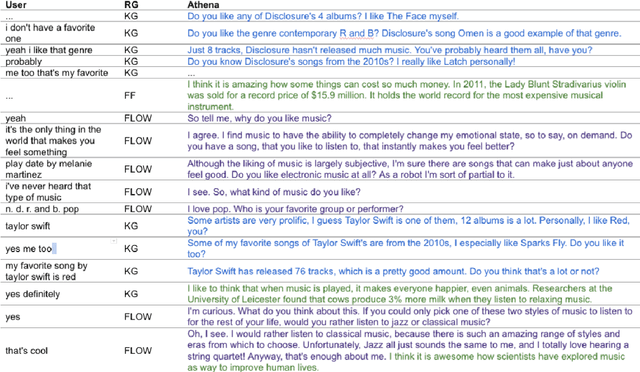

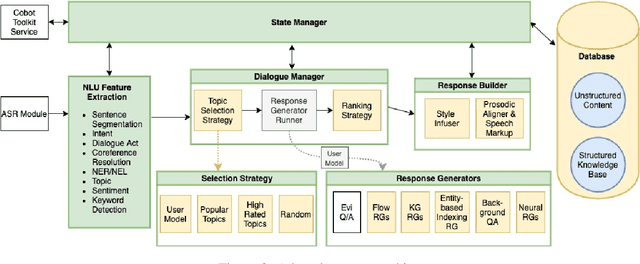
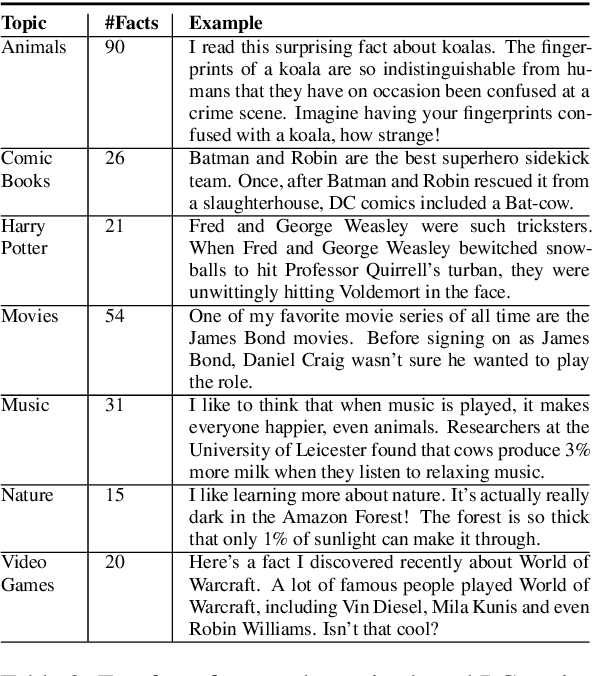
Athena 2.0 is an Alexa Prize SocialBot that has been a finalist in the last two Alexa Prize Grand Challenges. One reason for Athena's success is its novel dialogue management strategy, which allows it to dynamically construct dialogues and responses from component modules, leading to novel conversations with every interaction. Here we describe Athena's system design and performance in the Alexa Prize during the 20/21 competition. A live demo of Athena as well as video recordings will provoke discussion on the state of the art in conversational AI.
Modeling Performance in Open-Domain Dialogue with PARADISE
Oct 21, 2021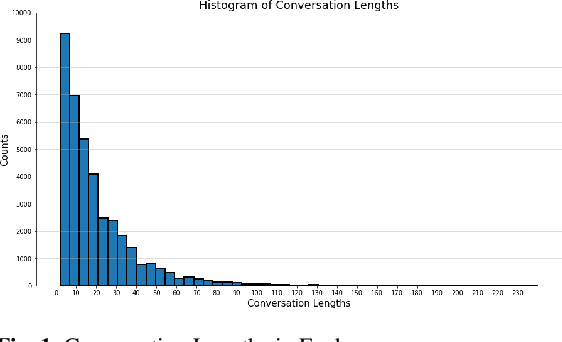
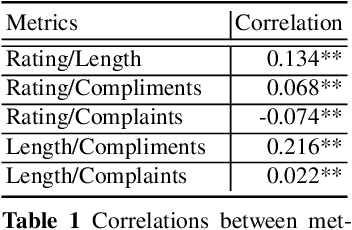

There has recently been an explosion of work on spoken dialogue systems, along with an increased interest in open-domain systems that engage in casual conversations on popular topics such as movies, books and music. These systems aim to socially engage, entertain, and even empathize with their users. Since the achievement of such social goals is hard to measure, recent research has used dialogue length or human ratings as evaluation metrics, and developed methods for automatically calculating novel metrics, such as coherence, consistency, relevance and engagement. Here we develop a PARADISE model for predicting the performance of Athena, a dialogue system that has participated in thousands of conversations with real users, while competing as a finalist in the Alexa Prize. We use both user ratings and dialogue length as metrics for dialogue quality, and experiment with predicting these metrics using automatic features that are both system dependent and independent. Our goal is to learn a general objective function that can be used to optimize the dialogue choices of any Alexa Prize system in real time and evaluate its performance. Our best model for predicting user ratings gets an R$^2$ of .136 with a DistilBert model, and the best model for predicting length with system independent features gets an R$^2$ of .865, suggesting that conversation length may be a more reliable measure for automatic training of dialogue systems.
Attention Is Indeed All You Need: Semantically Attention-Guided Decoding for Data-to-Text NLG
Sep 15, 2021

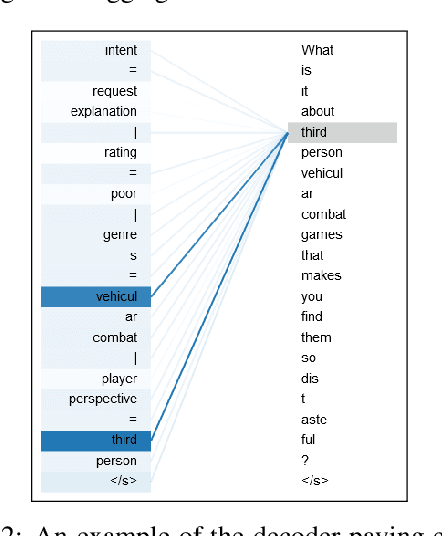
Ever since neural models were adopted in data-to-text language generation, they have invariably been reliant on extrinsic components to improve their semantic accuracy, because the models normally do not exhibit the ability to generate text that reliably mentions all of the information provided in the input. In this paper, we propose a novel decoding method that extracts interpretable information from encoder-decoder models' cross-attention, and uses it to infer which attributes are mentioned in the generated text, which is subsequently used to rescore beam hypotheses. Using this decoding method with T5 and BART, we show on three datasets its ability to dramatically reduce semantic errors in the generated outputs, while maintaining their state-of-the-art quality.