 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Performance in Open-Domain Dialogue with PARADISE
Paper and Code
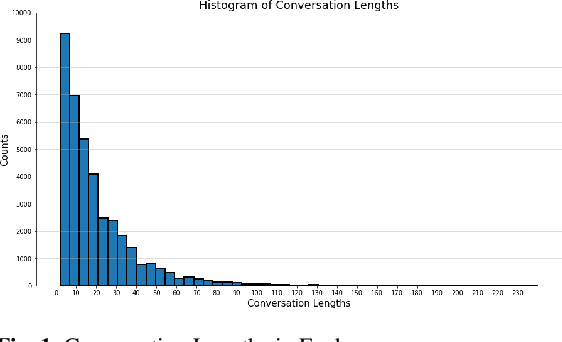
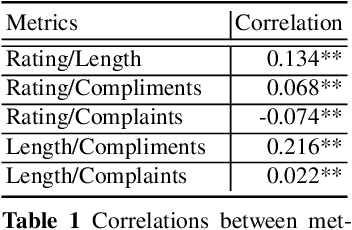
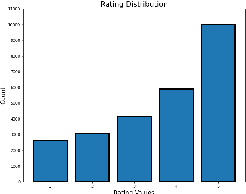

There has recently been an explosion of work on spoken dialogue systems, along with an increased interest in open-domain systems that engage in casual conversations on popular topics such as movies, books and music. These systems aim to socially engage, entertain, and even empathize with their users. Since the achievement of such social goals is hard to measure, recent research has used dialogue length or human ratings as evaluation metrics, and developed methods for automatically calculating novel metrics, such as coherence, consistency, relevance and engagement. Here we develop a PARADISE model for predicting the performance of Athena, a dialogue system that has participated in thousands of conversations with real users, while competing as a finalist in the Alexa Prize. We use both user ratings and dialogue length as metrics for dialogue quality, and experiment with predicting these metrics using automatic features that are both system dependent and independent. Our goal is to learn a general objective function that can be used to optimize the dialogue choices of any Alexa Prize system in real time and evaluate its performance. Our best model for predicting user ratings gets an R$^2$ of .136 with a DistilBert model, and the best model for predicting length with system independent features gets an R$^2$ of .865, suggesting that conversation length may be a more reliable measure for automatic training of dialogue systems.