 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Performance in Open-Domain Dialogue with PARADISE
Oct 21, 2021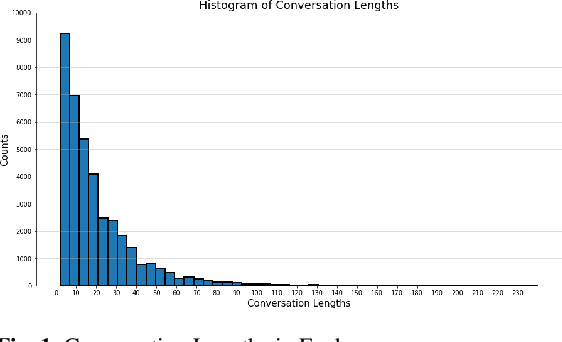
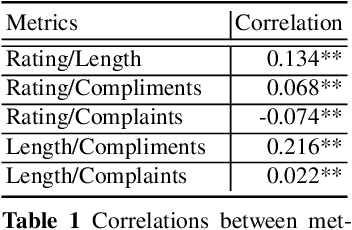
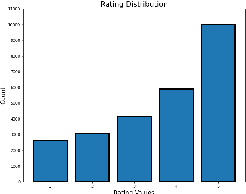

There has recently been an explosion of work on spoken dialogue systems, along with an increased interest in open-domain systems that engage in casual conversations on popular topics such as movies, books and music. These systems aim to socially engage, entertain, and even empathize with their users. Since the achievement of such social goals is hard to measure, recent research has used dialogue length or human ratings as evaluation metrics, and developed methods for automatically calculating novel metrics, such as coherence, consistency, relevance and engagement. Here we develop a PARADISE model for predicting the performance of Athena, a dialogue system that has participated in thousands of conversations with real users, while competing as a finalist in the Alexa Prize. We use both user ratings and dialogue length as metrics for dialogue quality, and experiment with predicting these metrics using automatic features that are both system dependent and independent. Our goal is to learn a general objective function that can be used to optimize the dialogue choices of any Alexa Prize system in real time and evaluate its performance. Our best model for predicting user ratings gets an R$^2$ of .136 with a DistilBert model, and the best model for predicting length with system independent features gets an R$^2$ of .865, suggesting that conversation length may be a more reliable measure for automatic training of dialogue systems.
Athena: Constructing Dialogues Dynamically with Discourse Constraints
Nov 21, 2020
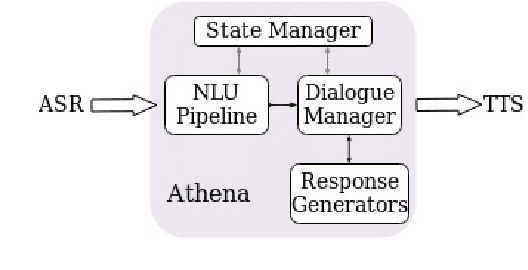
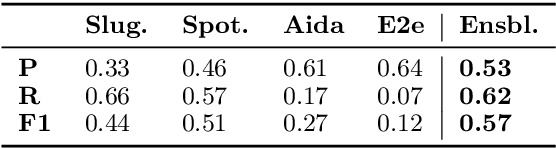

This report describes Athena, a dialogue system for spoken conversation on popular topics and current events. We develop a flexible topic-agnostic approach to dialogue management that dynamically configures dialogue based on general principles of entity and topic coherence. Athena's dialogue manager uses a contract-based method where discourse constraints are dispatched to clusters of response generators. This allows Athena to procure responses from dynamic sources, such as knowledge graph traversals and feature-based on-the-fly response retrieval methods. After describing the dialogue system architecture, we perform an analysis of conversations that Athena participated in during the 2019 Alexa Prize Competition. We conclude with a report on several user studies we carried out to better understand how individual user characteristics affect system ratings.
Entertaining and Opinionated but Too Controlling: A Large-Scale User Study of an Open Domain Alexa Prize System
Aug 13, 2019

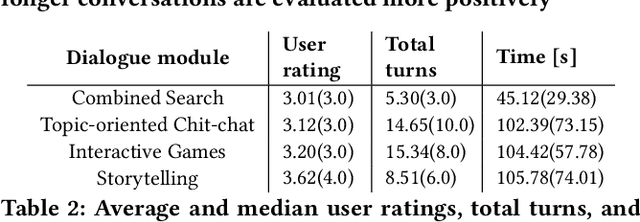
Conversational systems typically focus on functional tasks such as scheduling appointments or creating todo lists. Instead we design and evaluate SlugBot (SB), one of 8 semifinalists in the 2018 AlexaPrize, whose goal is to support casual open-domain social inter-action. This novel application requires both broad topic coverage and engaging interactive skills. We developed a new technical approach to meet this demanding situation by crowd-sourcing novel content and introducing playful conversational strategies based on storytelling and games. We collected over 10,000 conversations during August 2018 as part of the Alexa Prize competition. We also conducted an in-lab follow-up qualitative evaluation. Over-all users found SB moderately engaging; conversations averaged 3.6 minutes and involved 26 user turns. However, users reacted very differently to different conversation subtypes. Storytelling and games were evaluated positively; these were seen as entertaining with predictable interactive structure. They also led users to impute personality and intelligence to SB. In contrast, search and general Chit-Chat induced coverage problems; here users found it hard to infer what topics SB could understand, with these conversations seen as being too system-driven. Theoretical and design implications suggest a move away from conversational systems that simply provide factual information. Future systems should be designed to have their own opinions with personal stories to share, and SB provides an example of how we might achieve this.
CruzAffect at AffCon 2019 Shared Task: A feature-rich approach to characterize happiness
Feb 16, 2019
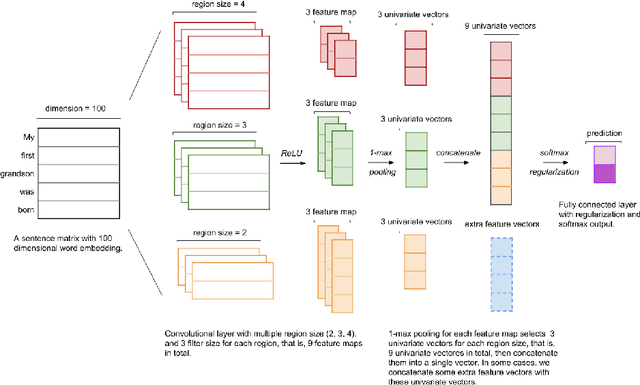
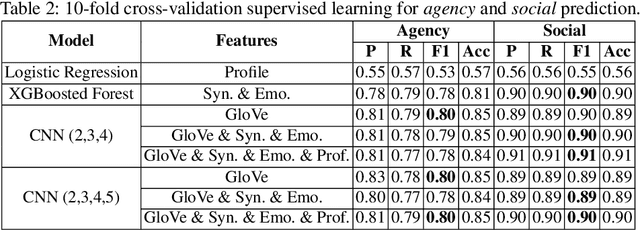
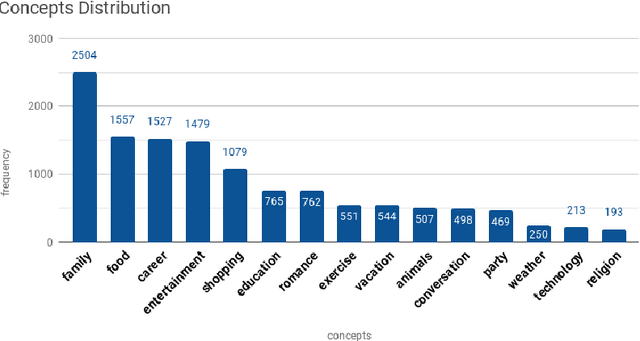
We present our system, CruzAffect, for the CL-Aff Shared Task 2019. CruzAffect consists of several types of robust and efficient models for affective classification tasks. We utilize both traditional classifiers, such as XGBoosted Forest, as well as a deep learning Convolutional Neural Networks (CNN) classifier. We explore rich feature sets such as syntactic features, emotional features, and profile features, and utilize several sentiment lexicons, to discover essential indicators of social involvement and control that a subject might exercise in their happy moments, as described in textual snippets from the HappyDB database. The data comes with a labeled set (10K), and a larger unlabeled set (70K). We therefore use supervised methods on the 10K dataset, and a bootstrapped semi-supervised approach for the 70K. We evaluate these models for binary classification of agency and social labels (Task 1), as well as multi-class prediction for concepts labels (Task 2). We obtain promising results on the held-out data, suggesting that the proposed feature sets effectively represent the data for affective classification tasks. We also build concepts models that discover general themes recurring in happy moments. Our results indicate that generic characteristics are shared between the classes of agency, social and concepts, suggesting it should be possible to build general models for affective classification tasks.
And That's A Fact: Distinguishing Factual and Emotional Argumentation in Online Dialogue
Sep 15, 2017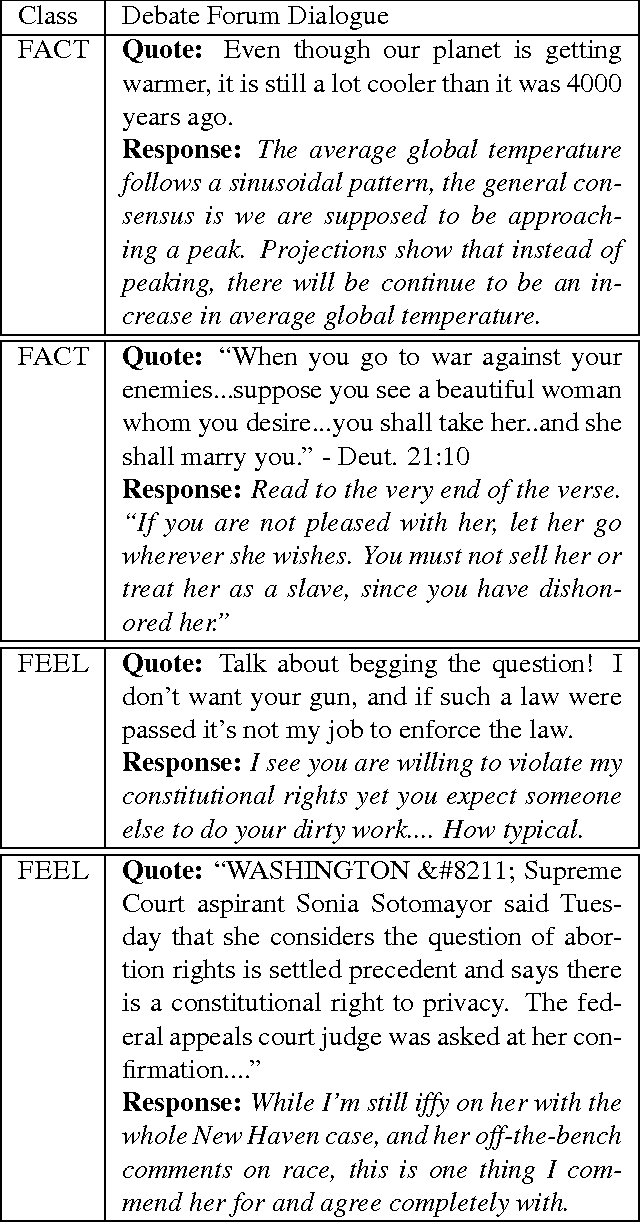
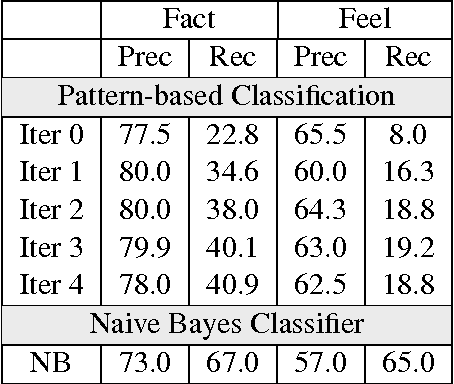
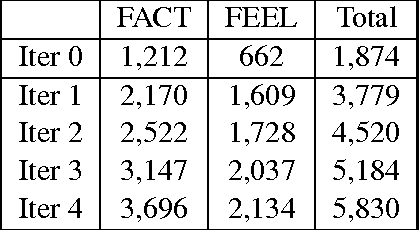

We investigate the characteristics of factual and emotional argumentation styles observed in online debates. Using an annotated set of "factual" and "feeling" debate forum posts, we extract patterns that are highly correlated with factual and emotional arguments, and then apply a bootstrapping methodology to find new patterns in a larger pool of unannotated forum posts. This process automatically produces a large set of patterns representing linguistic expressions that are highly correlated with factual and emotional language. Finally, we analyze the most discriminating patterns to better understand the defining characteristics of factual and emotional arguments.
Argument Strength is in the Eye of the Beholder: Audience Effects in Persuasion
Aug 30, 2017

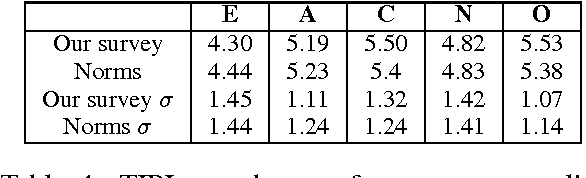

Americans spend about a third of their time online, with many participating in online conversations on social and political issues. We hypothesize that social media arguments on such issues may be more engaging and persuasive than traditional media summaries, and that particular types of people may be more or less convinced by particular styles of argument, e.g. emotional arguments may resonate with some personalities while factual arguments resonate with others. We report a set of experiments testing at large scale how audience variables interact with argument style to affect the persuasiveness of an argument, an under-researched topic within natural language processing. We show that belief change is affected by personality factors, with conscientious, open and agreeable people being more convinced by emotional arguments.
Mixed Initiative in Dialogue: An Investigation into Discourse Segmentation
Apr 05, 1995


Conversation between two people is usually of mixed-initiative, with control over the conversation being transferred from one person to another. We apply a set of rules for the transfer of control to 4 sets of dialogues consisting of a total of 1862 turns. The application of the control rules lets us derive domain-independent discourse structures. The derived structures indicate that initiative plays a role in the structuring of discourse. In order to explore the relationship of control and initiative to discourse processes like centering, we analyze the distribution of four different classes of anaphora for two data sets. This distribution indicates that some control segments are hierarchically related to others. The analysis suggests that discourse participants often mutually agree to a change of topic. We also compared initiative in Task Oriented and Advice Giving dialogues and found that both allocation of control and the manner in which control is transferred is radically different for the two dialogue types. These differences can be explained in terms of collaborative planning principles.
* 8 pages, latex
Cues and control in Expert-Client Dialogues
Apr 05, 1995We conducted an empirical analysis into the relation between control and discourse structure. We applied control criteria to four dialogues and identified 3 levels of discourse structure. We investigated the mechanism for changing control between these structures and found that utterance type and not cue words predicted shifts of control. Participants used certain types of signals when discourse goals were proceeding successfully but resorted to interruptions when they were not.
* 8 pages, latex