 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Acquiring Text Content to Enable the Classification of Lesser-known Entities for Real-world Tasks
Apr 24, 2026Existing Natural Language Processing (NLP) resources often lack the task-specific information required for real-world problems and provide limited coverage of lesser-known or newly introduced entities. For example, business organizations and health care providers may need to be classified into a variety of different taxonomic schemes for specific application tasks. Our goal is to enable domain experts to easily create a task-specific classifier for entities by providing only entity names and gold labels as training data. Our framework then dynamically acquires descriptive text about each entity, which is subsequently used as the basis for producing a text-based classifier. We propose a novel text acquisition method that leverages both web and large language models (LLMs). We evaluate our proposed framework on two classification problems in distinct domains: (i) classifying organizations into Standard Industrial Classification (SIC) Codes, which categorize organizations based on their business activities; and (ii) classifying healthcare providers into healthcare provider taxonomy codes, which represent a provider's medical specialty and area of practice. Our best-performing model achieved macro-averaged F1-scores of 82.3% and 72.9% on the SIC code and healthcare taxonomy code classification tasks, respectively.
Bridging the Long-Tail Gap: Robust Retrieval-Augmented Relation Completion via Multi-Stage Paraphrase Infusion
Apr 24, 2026Large language models (LLMs) struggle with relation completion (RC), both with and without retrieval-augmented generation (RAG), particularly when the required information is rare or sparsely represented. To address this, we propose a novel multi-stage paraphrase-guided relation-completion framework, RC-RAG, that systematically incorporates relation paraphrases across multiple stages. In particular, RC-RAG: (a) integrates paraphrases into retrieval to expand lexical coverage of the relation, (b) uses paraphrases to generate relation-aware summaries, and (c) leverages paraphrases during generation to guide reasoning for relation completion. Importantly, our method does not require any model fine-tuning. Experiments with five LLMs on two benchmark datasets show that RC-RAG consistently outperforms several RAG baselines. In long-tail settings, the best-performing LLM augmented with RC-RAG improves by 40.6 Exact Match (EM) points over its standalone performance and surpasses two strong RAG baselines by 16.0 and 13.8 EM points, respectively, while maintaining low computational overhead.
Say Less, Mean More: Leveraging Pragmatics in Retrieval-Augmented Generation
Feb 25, 2025We propose a simple, unsupervised method that injects pragmatic principles in retrieval-augmented generation (RAG) frameworks such as Dense Passage Retrieval~\cite{karpukhin2020densepassageretrievalopendomain} to enhance the utility of retrieved contexts. Our approach first identifies which sentences in a pool of documents retrieved by RAG are most relevant to the question at hand, cover all the topics addressed in the input question and no more, and then highlights these sentences within their context, before they are provided to the LLM, without truncating or altering the context in any other way. We show that this simple idea brings consistent improvements in experiments on three question answering tasks (ARC-Challenge, PubHealth and PopQA) using five different LLMs. It notably enhances relative accuracy by up to 19.7\% on PubHealth and 10\% on ARC-Challenge compared to a conventional RAG system.
Memorization In In-Context Learning
Aug 21, 2024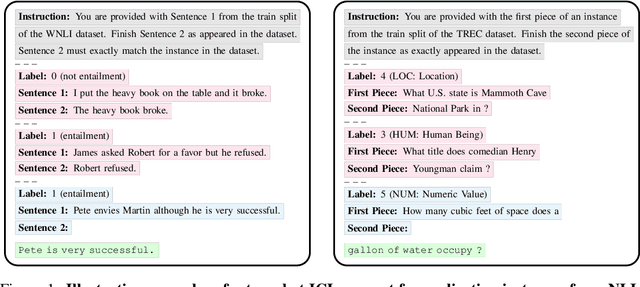
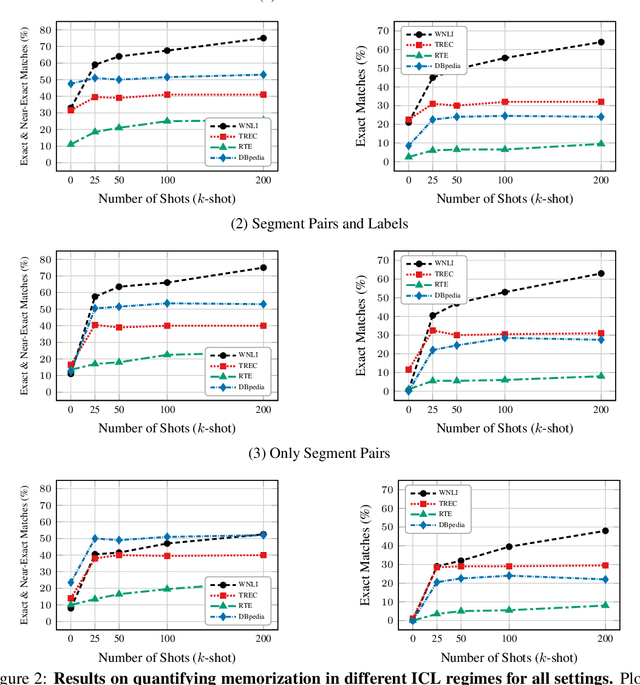

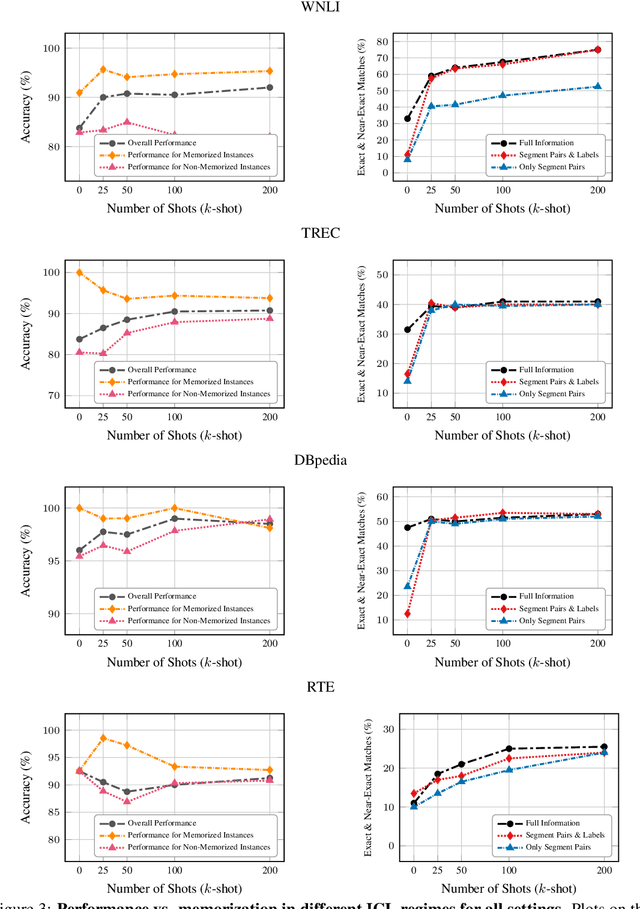
In-context learning (ICL) has proven to be an effective strategy for improving the performance of large language models (LLMs) with no additional training. However, the exact mechanism behind these performance improvements remains unclear. This study is the first to show how ICL surfaces memorized training data and to explore the correlation between this memorization and performance across various ICL regimes: zero-shot, few-shot, and many-shot. Our most notable findings include: (1) ICL significantly surfaces memorization compared to zero-shot learning in most cases; (2) demonstrations, without their labels, are the most effective element in surfacing memorization; (3) ICL improves performance when the surfaced memorization in few-shot regimes reaches a high level (about 40%); and (4) there is a very strong correlation between performance and memorization in ICL when it outperforms zero-shot learning. Overall, our study uncovers a hidden phenomenon -- memorization -- at the core of ICL, raising an important question: to what extent do LLMs truly generalize from demonstrations in ICL, and how much of their success is due to memorization?
Classifying Organizations for Food System Ontologies using Natural Language Processing
Sep 19, 2023Our research explores the use of natural language processing (NLP) methods to automatically classify entities for the purpose of knowledge graph population and integration with food system ontologies. We have created NLP models that can automatically classify organizations with respect to categories associated with environmental issues as well as Standard Industrial Classification (SIC) codes, which are used by the U.S. government to characterize business activities. As input, the NLP models are provided with text snippets retrieved by the Google search engine for each organization, which serves as a textual description of the organization that is used for learning. Our experimental results show that NLP models can achieve reasonably good performance for these two classification tasks, and they rely on a general framework that could be applied to many other classification problems as well. We believe that NLP models represent a promising approach for automatically harvesting information to populate knowledge graphs and aligning the information with existing ontologies through shared categories and concepts.
Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue
Sep 15, 2017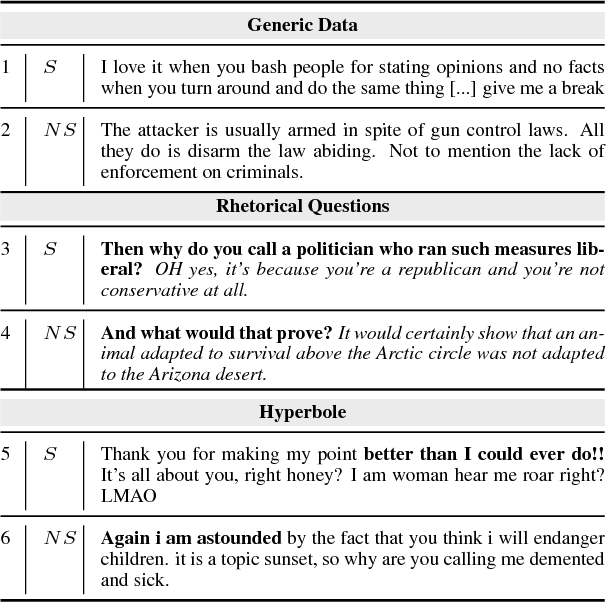

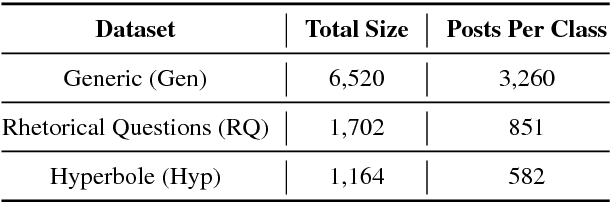
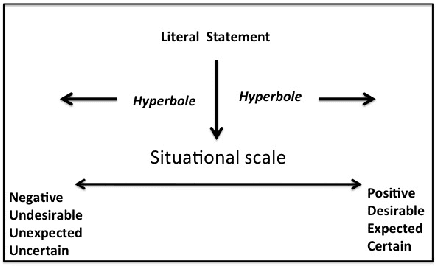
The use of irony and sarcasm in social media allows us to study them at scale for the first time. However, their diversity has made it difficult to construct a high-quality corpus of sarcasm in dialogue. Here, we describe the process of creating a large- scale, highly-diverse corpus of online debate forums dialogue, and our novel methods for operationalizing classes of sarcasm in the form of rhetorical questions and hyperbole. We show that we can use lexico-syntactic cues to reliably retrieve sarcastic utterances with high accuracy. To demonstrate the properties and quality of our corpus, we conduct supervised learning experiments with simple features, and show that we achieve both higher precision and F than previous work on sarcasm in debate forums dialogue. We apply a weakly-supervised linguistic pattern learner and qualitatively analyze the linguistic differences in each class.
Are you serious?: Rhetorical Questions and Sarcasm in Social Media Dialog
Sep 15, 2017
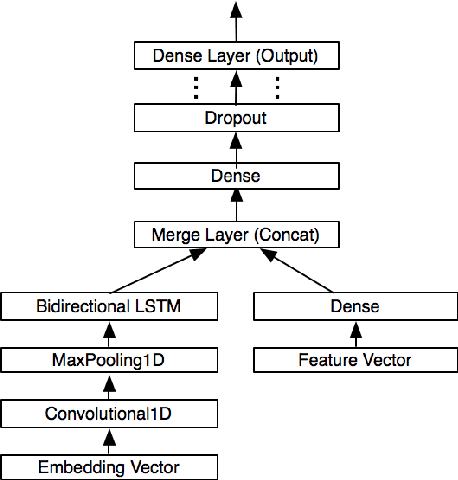


Effective models of social dialog must understand a broad range of rhetorical and figurative devices. Rhetorical questions (RQs) are a type of figurative language whose aim is to achieve a pragmatic goal, such as structuring an argument, being persuasive, emphasizing a point, or being ironic. While there are computational models for other forms of figurative language, rhetorical questions have received little attention to date. We expand a small dataset from previous work, presenting a corpus of 10,270 RQs from debate forums and Twitter that represent different discourse functions. We show that we can clearly distinguish between RQs and sincere questions (0.76 F1). We then show that RQs can be used both sarcastically and non-sarcastically, observing that non-sarcastic (other) uses of RQs are frequently argumentative in forums, and persuasive in tweets. We present experiments to distinguish between these uses of RQs using SVM and LSTM models that represent linguistic features and post-level context, achieving results as high as 0.76 F1 for "sarcastic" and 0.77 F1 for "other" in forums, and 0.83 F1 for both "sarcastic" and "other" in tweets. We supplement our quantitative experiments with an in-depth characterization of the linguistic variation in RQs.
And That's A Fact: Distinguishing Factual and Emotional Argumentation in Online Dialogue
Sep 15, 2017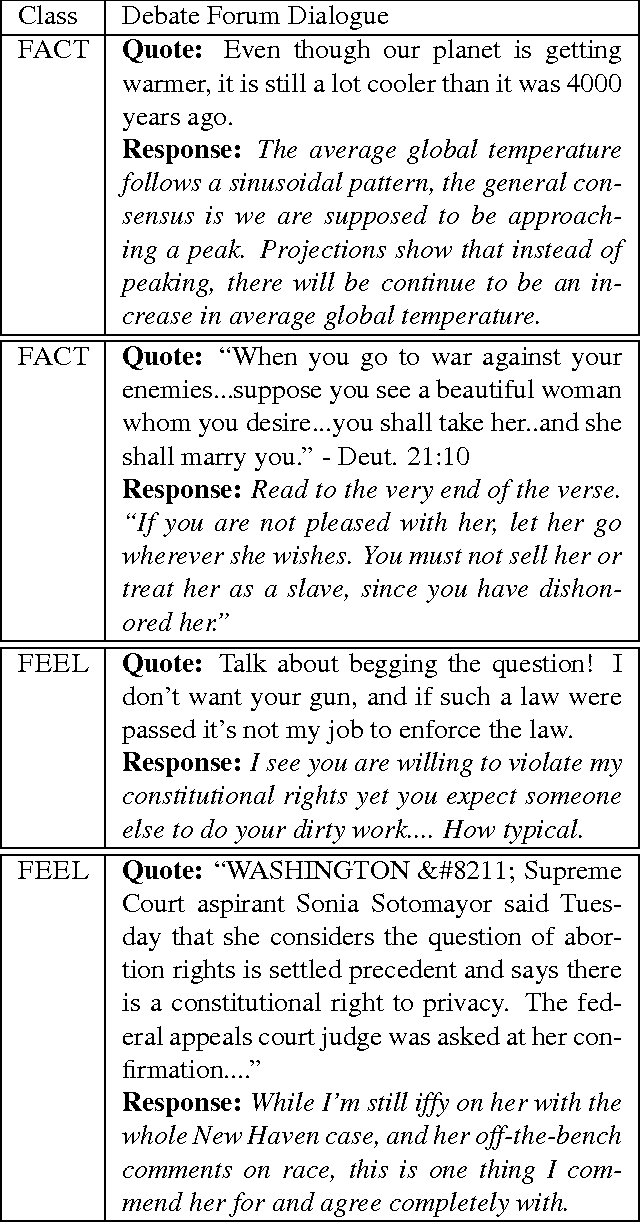
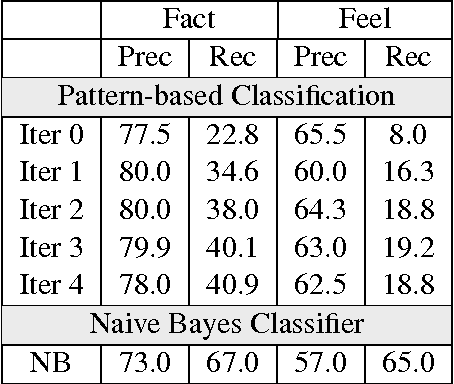
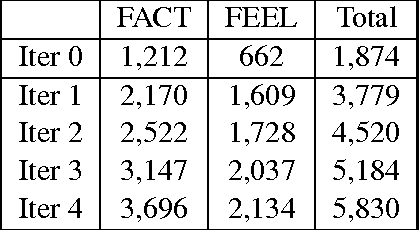

We investigate the characteristics of factual and emotional argumentation styles observed in online debates. Using an annotated set of "factual" and "feeling" debate forum posts, we extract patterns that are highly correlated with factual and emotional arguments, and then apply a bootstrapping methodology to find new patterns in a larger pool of unannotated forum posts. This process automatically produces a large set of patterns representing linguistic expressions that are highly correlated with factual and emotional language. Finally, we analyze the most discriminating patterns to better understand the defining characteristics of factual and emotional arguments.
Looking Under the Hood : Tools for Diagnosing your Question Answering Engine
Jul 03, 2001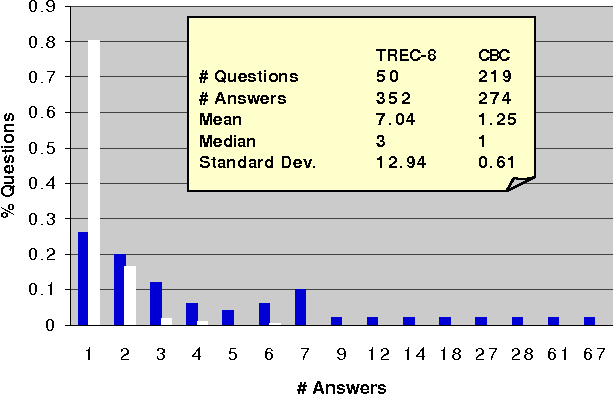
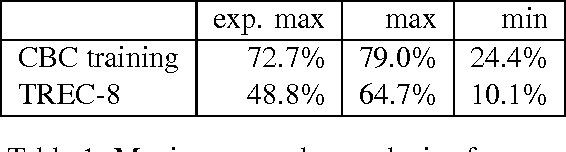
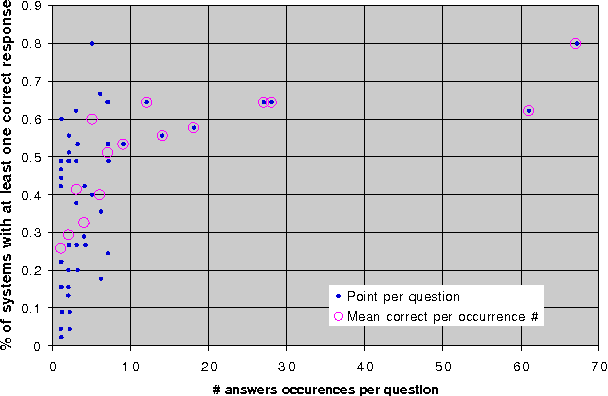

In this paper we analyze two question answering tasks : the TREC-8 question answering task and a set of reading comprehension exams. First, we show that Q/A systems perform better when there are multiple answer opportunities per question. Next, we analyze common approaches to two subproblems: term overlap for answer sentence identification, and answer typing for short answer extraction. We present general tools for analyzing the strengths and limitations of techniques for these subproblems. Our results quantify the limitations of both term overlap and answer typing to distinguish between competing answer candidates.
A Corpus-Based Approach for Building Semantic Lexicons
Jun 10, 1997
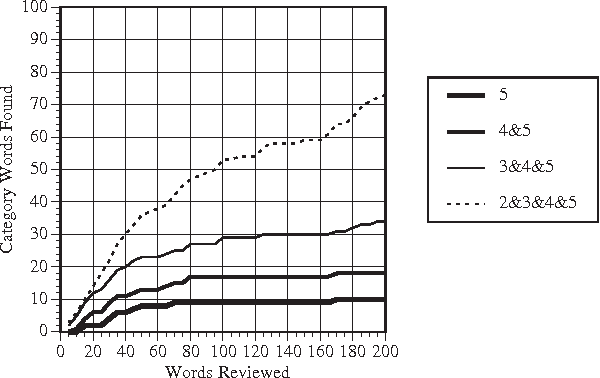
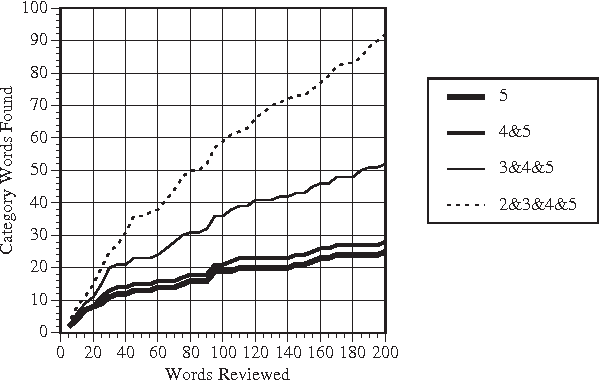
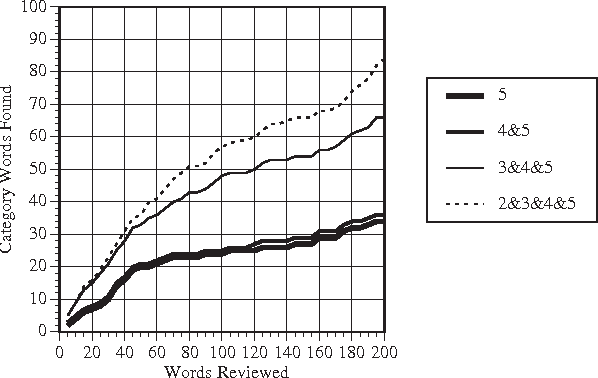
Semantic knowledge can be a great asset to natural language processing systems, but it is usually hand-coded for each application. Although some semantic information is available in general-purpose knowledge bases such as WordNet and Cyc, many applications require domain-specific lexicons that represent words and categories for a particular topic. In this paper, we present a corpus-based method that can be used to build semantic lexicons for specific categories. The input to the system is a small set of seed words for a category and a representative text corpus. The output is a ranked list of words that are associated with the category. A user then reviews the top-ranked words and decides which ones should be entered in the semantic lexicon. In experiments with five categories, users typically found about 60 words per category in 10-15 minutes to build a core semantic lexicon.