 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
Nov 22, 2017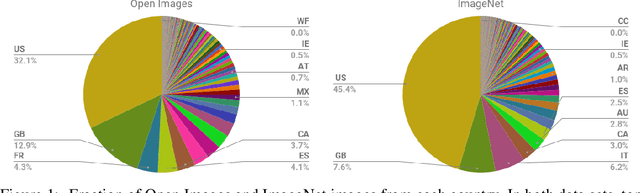
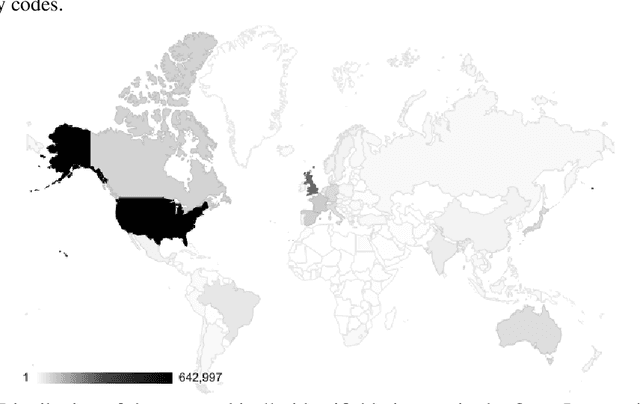
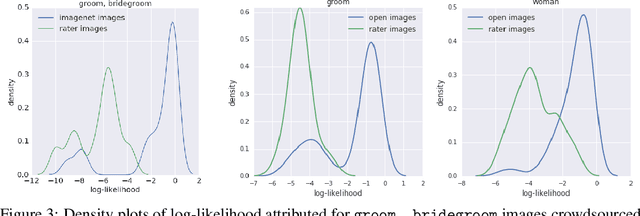
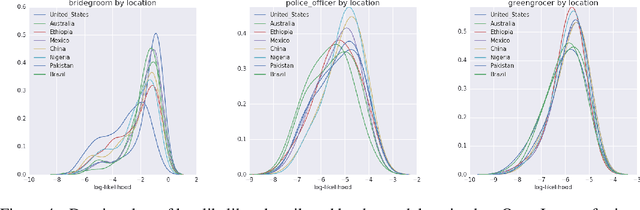
Modern machine learning systems such as image classifiers rely heavily on large scale data sets for training. Such data sets are costly to create, thus in practice a small number of freely available, open source data sets are widely used. We suggest that examining the geo-diversity of open data sets is critical before adopting a data set for use cases in the developing world. We analyze two large, publicly available image data sets to assess geo-diversity and find that these data sets appear to exhibit an observable amerocentric and eurocentric representation bias. Further, we analyze classifiers trained on these data sets to assess the impact of these training distributions and find strong differences in the relative performance on images from different locales. These results emphasize the need to ensure geo-representation when constructing data sets for use in the developing world.
Looking Under the Hood : Tools for Diagnosing your Question Answering Engine
Jul 03, 2001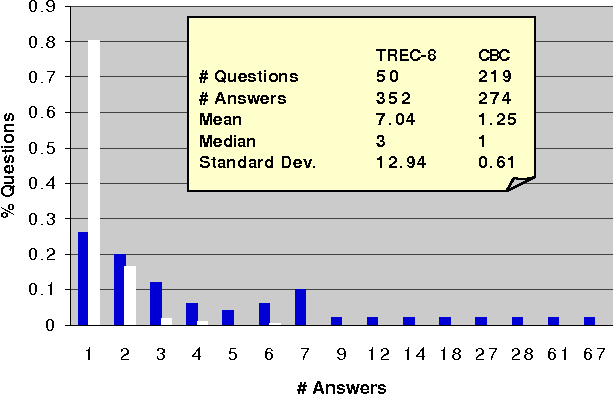
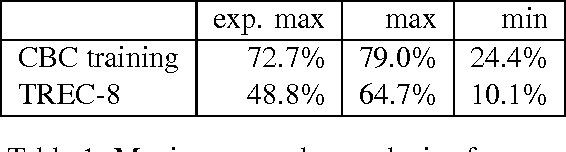
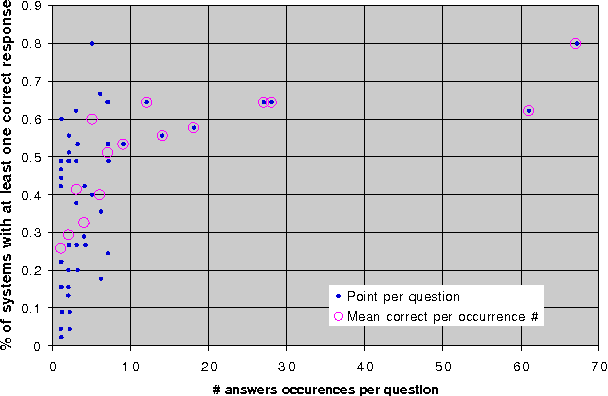

In this paper we analyze two question answering tasks : the TREC-8 question answering task and a set of reading comprehension exams. First, we show that Q/A systems perform better when there are multiple answer opportunities per question. Next, we analyze common approaches to two subproblems: term overlap for answer sentence identification, and answer typing for short answer extraction. We present general tools for analyzing the strengths and limitations of techniques for these subproblems. Our results quantify the limitations of both term overlap and answer typing to distinguish between competing answer candidates.
How to Evaluate your Question Answering System Every Day and Still Get Real Work Done
Apr 17, 2000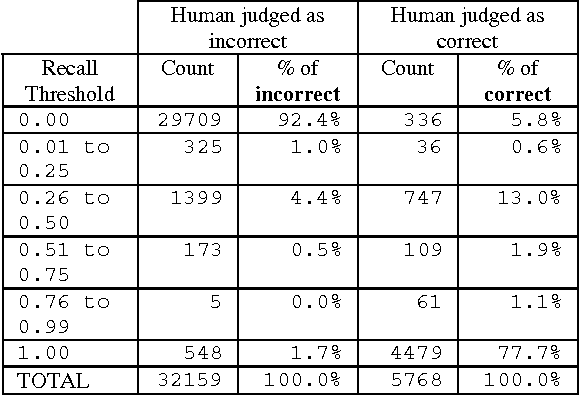
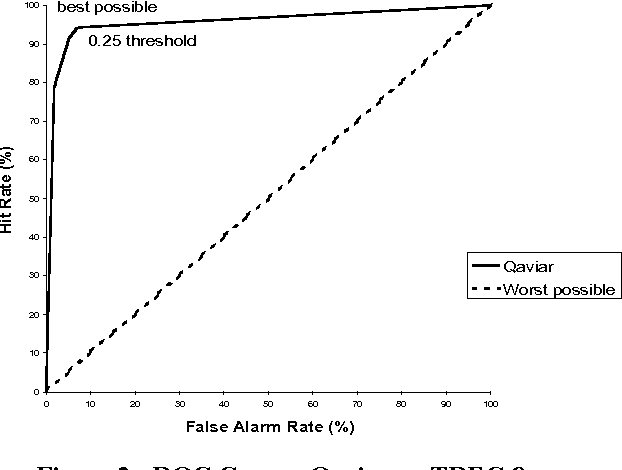

In this paper, we report on Qaviar, an experimental automated evaluation system for question answering applications. The goal of our research was to find an automatically calculated measure that correlates well with human judges' assessment of answer correctness in the context of question answering tasks. Qaviar judges the response by computing recall against the stemmed content words in the human-generated answer key. It counts the answer correct if it exceeds agiven recall threshold. We determined that the answer correctness predicted by Qaviar agreed with the human 93% to 95% of the time. 41 question-answering systems were ranked by both Qaviar and human assessors, and these rankings correlated with a Kendall's Tau measure of 0.920, compared to a correlation of 0.956 between human assessors on the same data.