 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinal Report on MITRE Evaluations for the DARPA Big Mechanism Program
Nov 08, 2022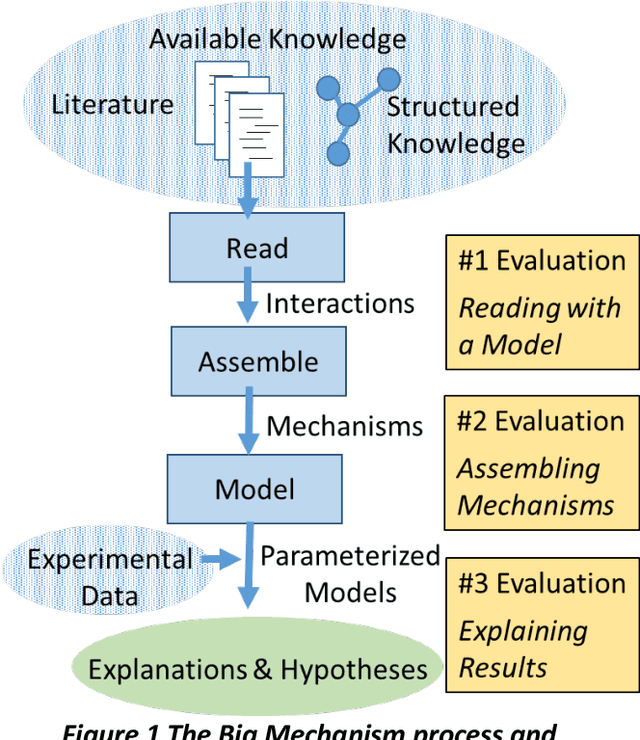
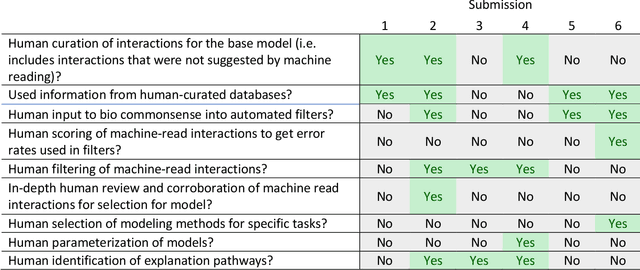
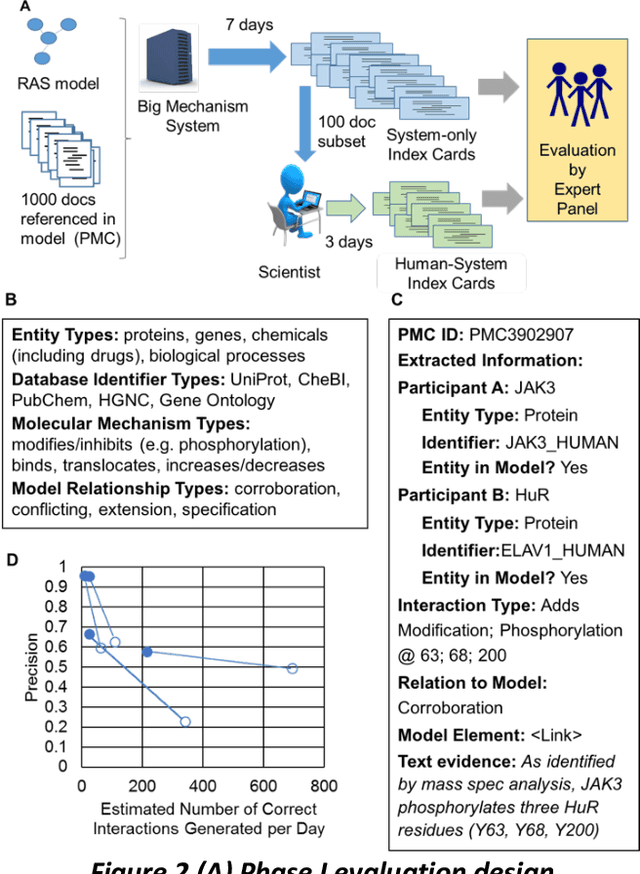
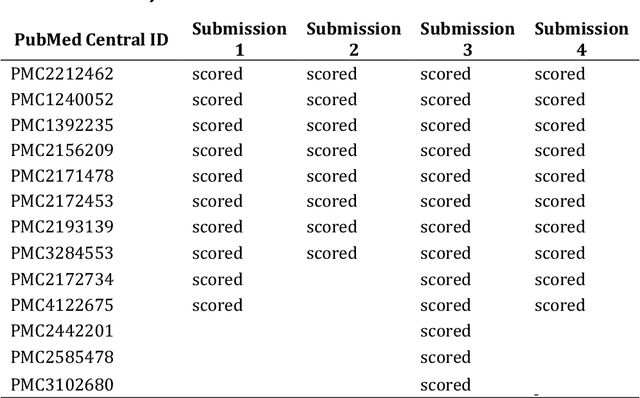
This report presents the evaluation approach developed for the DARPA Big Mechanism program, which aimed at developing computer systems that will read research papers, integrate the information into a computer model of cancer mechanisms, and frame new hypotheses. We employed an iterative, incremental approach to the evaluation of the three phases of the program. In Phase I, we evaluated the ability of system and human teams ability to read-with-a-model to capture mechanistic information from the biomedical literature, integrated with information from expert curated biological databases. In Phase II we evaluated the ability of systems to assemble fragments of information into a mechanistic model. The Phase III evaluation focused on the ability of systems to provide explanations of experimental observations based on models assembled (largely automatically) by the Big Mechanism process. The evaluation for each phase built on earlier evaluations and guided developers towards creating capabilities for the new phase. The report describes our approach, including innovations such as a reference set (a curated data set limited to major findings of each paper) to assess the accuracy of systems in extracting mechanistic findings in the absence of a gold standard, and a method to evaluate model-based explanations of experimental data. Results of the evaluation and supporting materials are included in the appendices.
Hallmarks of Human-Machine Collaboration: A framework for assessment in the DARPA Communicating with Computers Program
Feb 09, 2021



There is a growing desire to create computer systems that can communicate effectively to collaborate with humans on complex, open-ended activities. Assessing these systems presents significant challenges. We describe a framework for evaluating systems engaged in open-ended complex scenarios where evaluators do not have the luxury of comparing performance to a single right answer. This framework has been used to evaluate human-machine creative collaborations across story and music generation, interactive block building, and exploration of molecular mechanisms in cancer. These activities are fundamentally different from the more constrained tasks performed by most contemporary personal assistants as they are generally open-ended, with no single correct solution, and often no obvious completion criteria. We identified the Key Properties that must be exhibited by successful systems. From there we identified "Hallmarks" of success -- capabilities and features that evaluators can observe that would be indicative of progress toward achieving a Key Property. In addition to being a framework for assessment, the Key Properties and Hallmarks are intended to serve as goals in guiding research direction.
Evaluation of text data mining for database curation: lessons learned from the KDD Challenge Cup
Aug 20, 2003


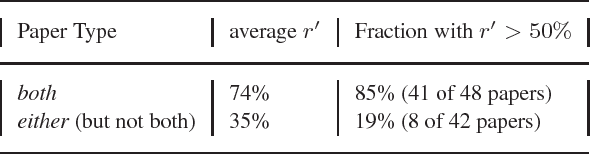
MOTIVATION: The biological literature is a major repository of knowledge. Many biological databases draw much of their content from a careful curation of this literature. However, as the volume of literature increases, the burden of curation increases. Text mining may provide useful tools to assist in the curation process. To date, the lack of standards has made it impossible to determine whether text mining techniques are sufficiently mature to be useful. RESULTS: We report on a Challenge Evaluation task that we created for the Knowledge Discovery and Data Mining (KDD) Challenge Cup. We provided a training corpus of 862 articles consisting of journal articles curated in FlyBase, along with the associated lists of genes and gene products, as well as the relevant data fields from FlyBase. For the test, we provided a corpus of 213 new (`blind') articles; the 18 participating groups provided systems that flagged articles for curation, based on whether the article contained experimental evidence for gene expression products. We report on the the evaluation results and describe the techniques used by the top performing groups. CONTACT: asy@mitre.org KEYWORDS: text mining, evaluation, curation, genomics, data management
* 9 pages. This is close to how it appears on the publisher's website (http://bioinformatics.oupjournals.org/cgi/reprint/19/suppl_1/i331) The article wording is the same. Uses bioinformatics-altered.cls, bioinformaticsbib.sty, bioinformaticstitle.sty
How to Evaluate your Question Answering System Every Day and Still Get Real Work Done
Apr 17, 2000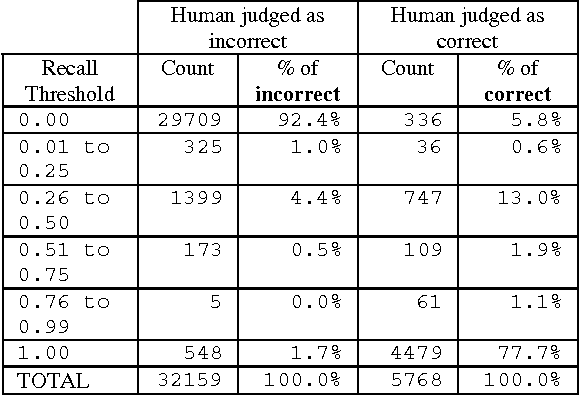
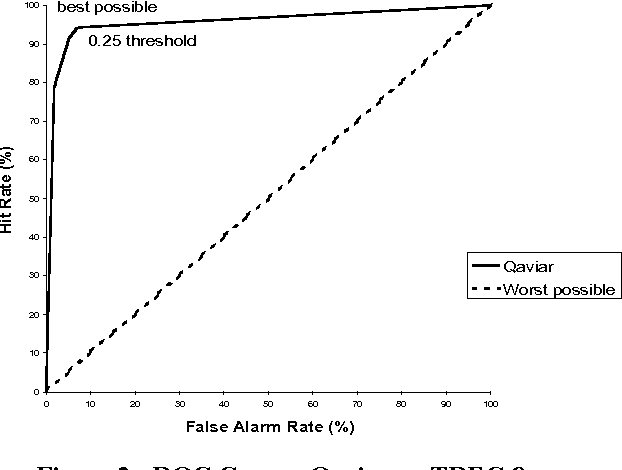

In this paper, we report on Qaviar, an experimental automated evaluation system for question answering applications. The goal of our research was to find an automatically calculated measure that correlates well with human judges' assessment of answer correctness in the context of question answering tasks. Qaviar judges the response by computing recall against the stemmed content words in the human-generated answer key. It counts the answer correct if it exceeds agiven recall threshold. We determined that the answer correctness predicted by Qaviar agreed with the human 93% to 95% of the time. 41 question-answering systems were ranked by both Qaviar and human assessors, and these rankings correlated with a Kendall's Tau measure of 0.920, compared to a correlation of 0.956 between human assessors on the same data.
Automating Coreference: The Role of Annotated Training Data
Mar 02, 1998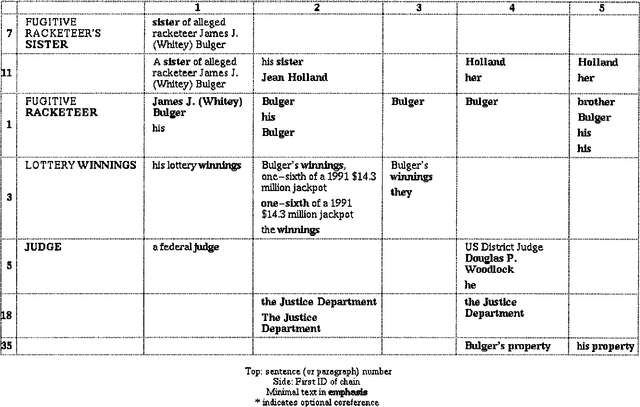
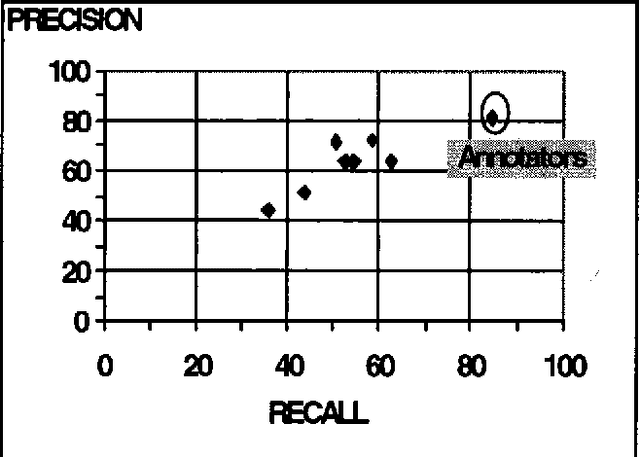
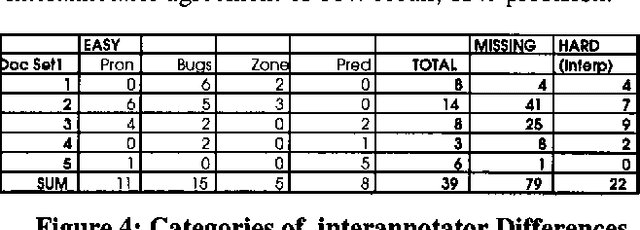
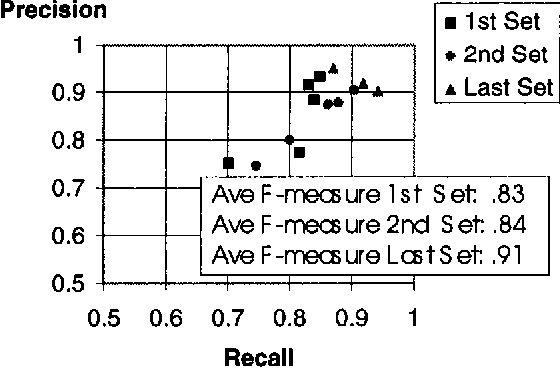
We report here on a study of interannotator agreement in the coreference task as defined by the Message Understanding Conference (MUC-6 and MUC-7). Based on feedback from annotators, we clarified and simplified the annotation specification. We then performed an analysis of disagreement among several annotators, concluding that only 16% of the disagreements represented genuine disagreement about coreference; the remainder of the cases were mostly typographical errors or omissions, easily reconciled. Initially, we measured interannotator agreement in the low 80s for precision and recall. To try to improve upon this, we ran several experiments. In our final experiment, we separated the tagging of candidate noun phrases from the linking of actual coreferring expressions. This method shows promise - interannotator agreement climbed to the low 90s - but it needs more extensive validation. These results position the research community to broaden the coreference task to multiple languages, and possibly to different kinds of coreference.