 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of text data mining for database curation: lessons learned from the KDD Challenge Cup
Paper and Code
Aug 20, 2003


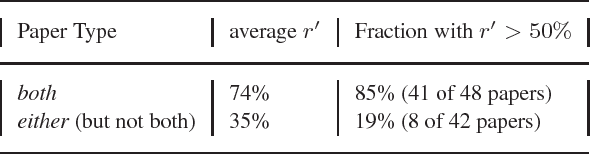
MOTIVATION: The biological literature is a major repository of knowledge. Many biological databases draw much of their content from a careful curation of this literature. However, as the volume of literature increases, the burden of curation increases. Text mining may provide useful tools to assist in the curation process. To date, the lack of standards has made it impossible to determine whether text mining techniques are sufficiently mature to be useful. RESULTS: We report on a Challenge Evaluation task that we created for the Knowledge Discovery and Data Mining (KDD) Challenge Cup. We provided a training corpus of 862 articles consisting of journal articles curated in FlyBase, along with the associated lists of genes and gene products, as well as the relevant data fields from FlyBase. For the test, we provided a corpus of 213 new (`blind') articles; the 18 participating groups provided systems that flagged articles for curation, based on whether the article contained experimental evidence for gene expression products. We report on the the evaluation results and describe the techniques used by the top performing groups. CONTACT: asy@mitre.org KEYWORDS: text mining, evaluation, curation, genomics, data management