 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transformation Rules to Find Grammatical Relations
Jun 14, 1999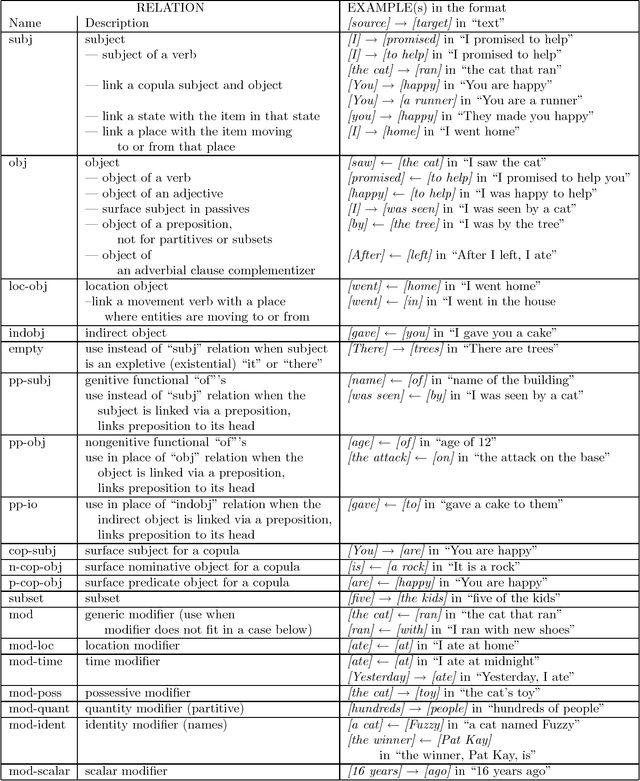
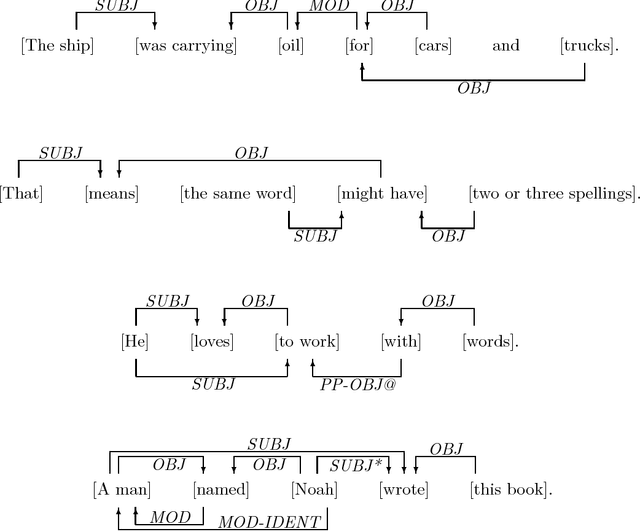
Grammatical relationships are an important level of natural language processing. We present a trainable approach to find these relationships through transformation sequences and error-driven learning. Our approach finds grammatical relationships between core syntax groups and bypasses much of the parsing phase. On our training and test set, our procedure achieves 63.6% recall and 77.3% precision (f-score = 69.8).
* 10 pages. Uses latex-acl.sty and named.sty
Automating Coreference: The Role of Annotated Training Data
Mar 02, 1998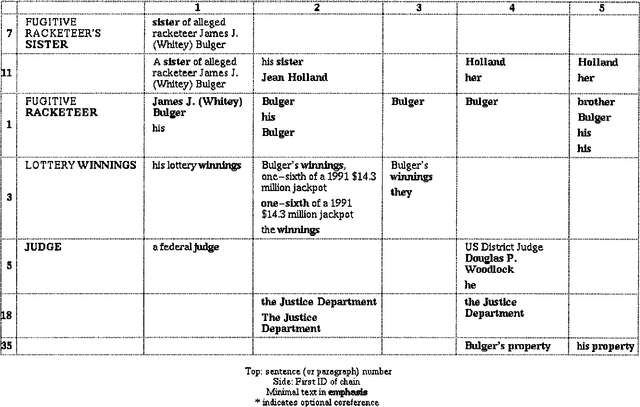
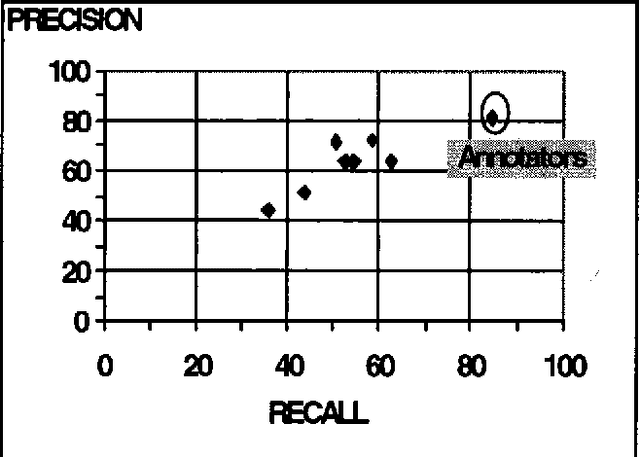
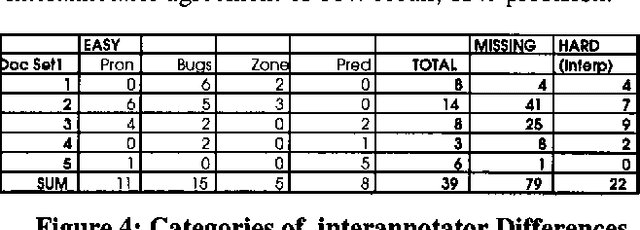
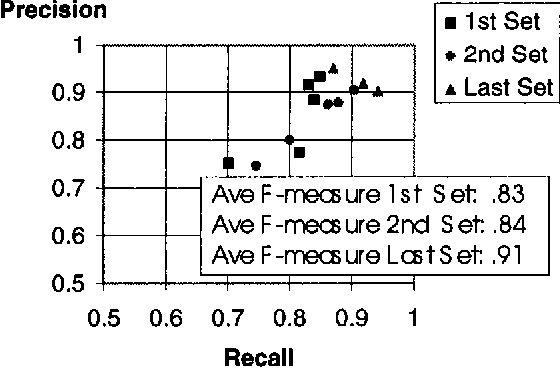
We report here on a study of interannotator agreement in the coreference task as defined by the Message Understanding Conference (MUC-6 and MUC-7). Based on feedback from annotators, we clarified and simplified the annotation specification. We then performed an analysis of disagreement among several annotators, concluding that only 16% of the disagreements represented genuine disagreement about coreference; the remainder of the cases were mostly typographical errors or omissions, easily reconciled. Initially, we measured interannotator agreement in the low 80s for precision and recall. To try to improve upon this, we ran several experiments. In our final experiment, we separated the tagging of candidate noun phrases from the linking of actual coreferring expressions. This method shows promise - interannotator agreement climbed to the low 90s - but it needs more extensive validation. These results position the research community to broaden the coreference task to multiple languages, and possibly to different kinds of coreference.