 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Likely Behaviors of Continuous Nonlinear Systems in Equilibrium
Mar 27, 2013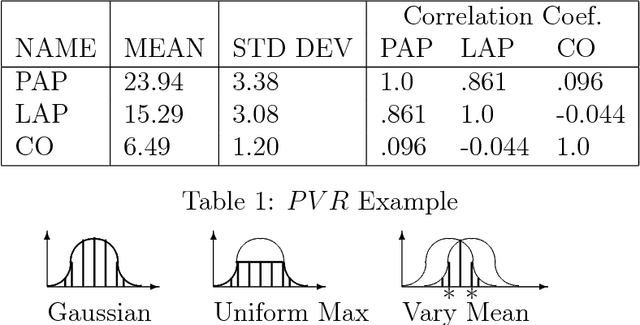
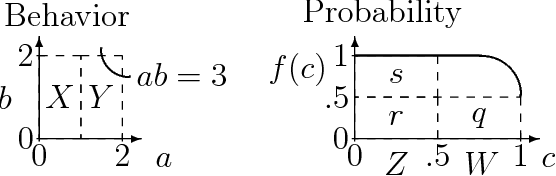

This paper introduces a method for predicting the likely behaviors of continuous nonlinear systems in equilibrium in which the input values can vary. The method uses a parameterized equation model and a lower bound on the input joint density to bound the likelihood that some behavior will occur, such as a state variable being inside a given numeric range. Using a bound on the density instead of the density itself is desirable because often the input density's parameters and shape are not exactly known. The new method is called SAB after its basic operations: split the input value space into smaller regions, and then bound those regions' possible behaviors and the probability of being in them. SAB finds rough bounds at first, and then refines them as more time is given. In contrast to other researchers' methods, SAB can (1) find all the possible system behaviors, and indicate how likely they are, (2) does not approximate the distribution of possible outcomes without some measure of the error magnitude, (3) does not use discretized variable values, which limit the events one can find probability bounds for, (4) can handle density bounds, and (5) can handle such criteria as two state variables both being inside a numeric range.
Using existing systems to supplement small amounts of annotated grammatical relations training data
Oct 11, 2000Grammatical relationships (GRs) form an important level of natural language processing, but different sets of GRs are useful for different purposes. Therefore, one may often only have time to obtain a small training corpus with the desired GR annotations. To boost the performance from using such a small training corpus on a transformation rule learner, we use existing systems that find related types of annotations.
* 7 pages, uses acl2000.sty
More accurate tests for the statistical significance of result differences
Aug 08, 2000Statistical significance testing of differences in values of metrics like recall, precision and balanced F-score is a necessary part of empirical natural language processing. Unfortunately, we find in a set of experiments that many commonly used tests often underestimate the significance and so are less likely to detect differences that exist between different techniques. This underestimation comes from an independence assumption that is often violated. We point out some useful tests that do not make this assumption, including computationally-intensive randomization tests.
* 7 pages, uses colacl.sty
Comparing two trainable grammatical relations finders
Aug 08, 2000Grammatical relationships (GRs) form an important level of natural language processing, but different sets of GRs are useful for different purposes. Therefore, one may often only have time to obtain a small training corpus with the desired GR annotations. On such a small training corpus, we compare two systems. They use different learning techniques, but we find that this difference by itself only has a minor effect. A larger factor is that in English, a different GR length measure appears better suited for finding simple argument GRs than for finding modifier GRs. We also find that partitioning the data may help memory-based learning.
* 5 pages, uses colacl.sty
Learning Transformation Rules to Find Grammatical Relations
Jun 14, 1999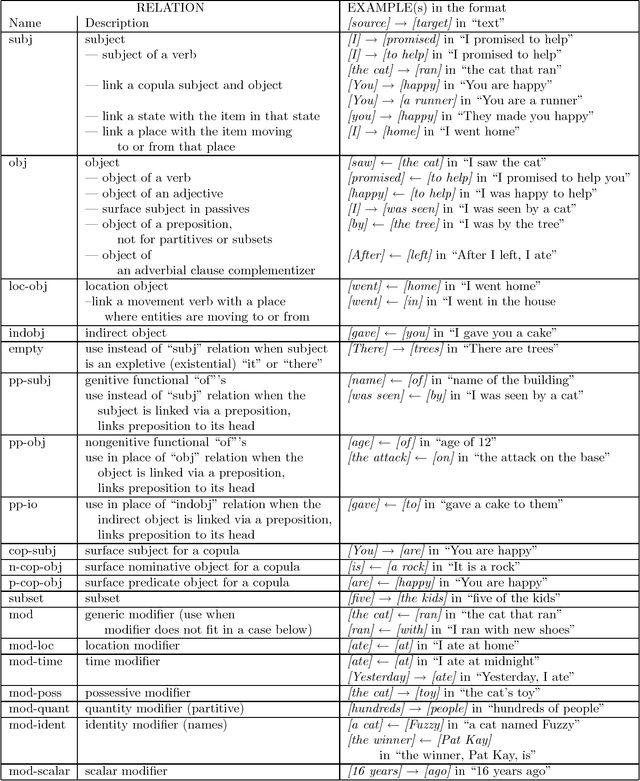
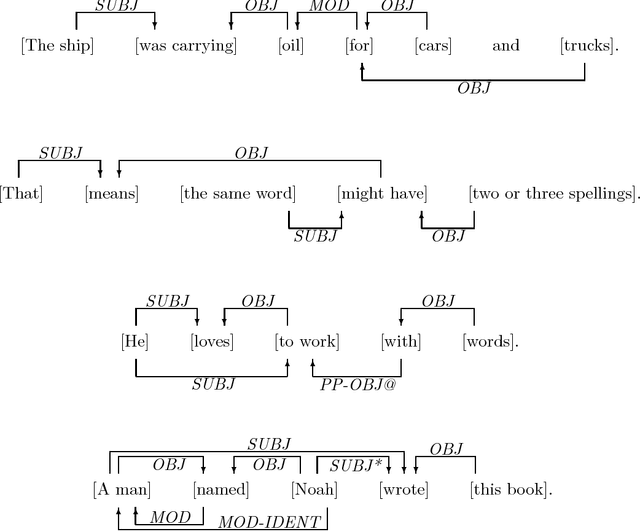
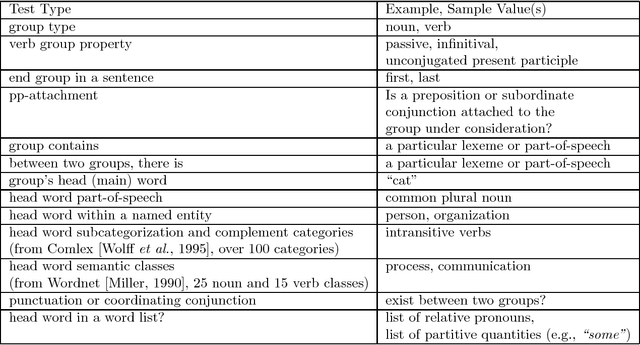
Grammatical relationships are an important level of natural language processing. We present a trainable approach to find these relationships through transformation sequences and error-driven learning. Our approach finds grammatical relationships between core syntax groups and bypasses much of the parsing phase. On our training and test set, our procedure achieves 63.6% recall and 77.3% precision (f-score = 69.8).
* 10 pages. Uses latex-acl.sty and named.sty