 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Under the Hood : Tools for Diagnosing your Question Answering Engine
Jul 03, 2001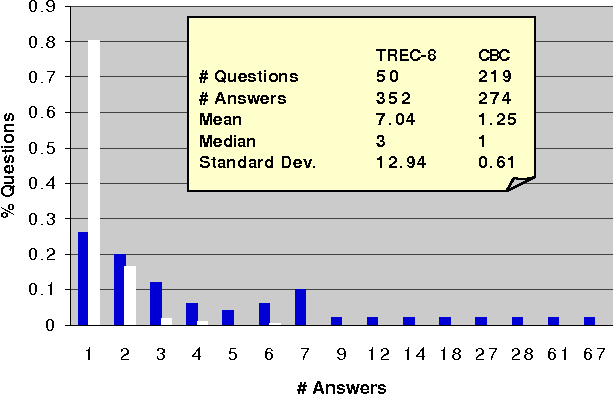
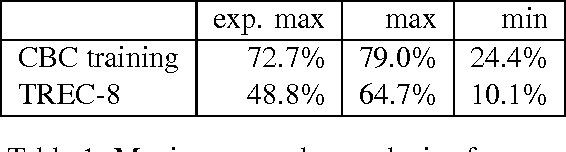
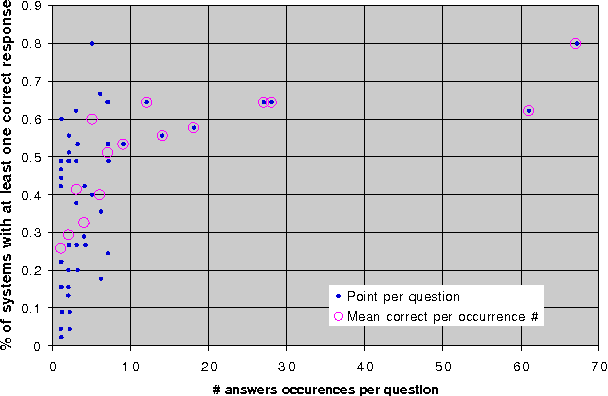

In this paper we analyze two question answering tasks : the TREC-8 question answering task and a set of reading comprehension exams. First, we show that Q/A systems perform better when there are multiple answer opportunities per question. Next, we analyze common approaches to two subproblems: term overlap for answer sentence identification, and answer typing for short answer extraction. We present general tools for analyzing the strengths and limitations of techniques for these subproblems. Our results quantify the limitations of both term overlap and answer typing to distinguish between competing answer candidates.
Using a Probabilistic Class-Based Lexicon for Lexical Ambiguity Resolution
Aug 30, 2000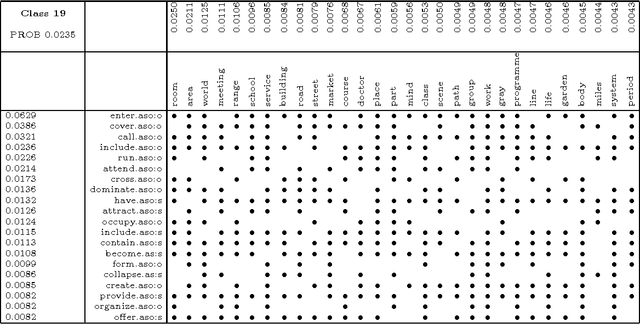
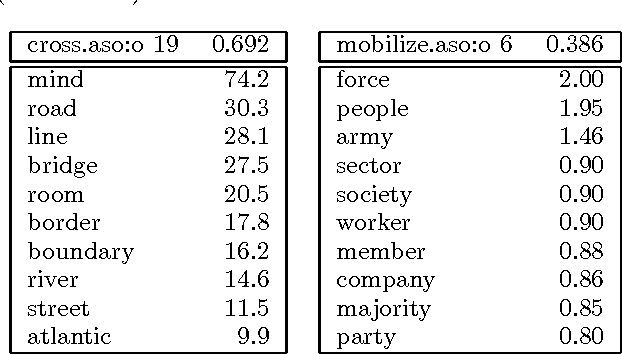


This paper presents the use of probabilistic class-based lexica for disambiguation in target-word selection. Our method employs minimal but precise contextual information for disambiguation. That is, only information provided by the target-verb, enriched by the condensed information of a probabilistic class-based lexicon, is used. Induction of classes and fine-tuning to verbal arguments is done in an unsupervised manner by EM-based clustering techniques. The method shows promising results in an evaluation on real-world translations.
* 7 pages, uses colacl.sty
Inducing a Semantically Annotated Lexicon via EM-Based Clustering
May 19, 1999We present a technique for automatic induction of slot annotations for subcategorization frames, based on induction of hidden classes in the EM framework of statistical estimation. The models are empirically evalutated by a general decision test. Induction of slot labeling for subcategorization frames is accomplished by a further application of EM, and applied experimentally on frame observations derived from parsing large corpora. We outline an interpretation of the learned representations as theoretical-linguistic decompositional lexical entries.
Inside-Outside Estimation of a Lexicalized PCFG for German
May 19, 1999
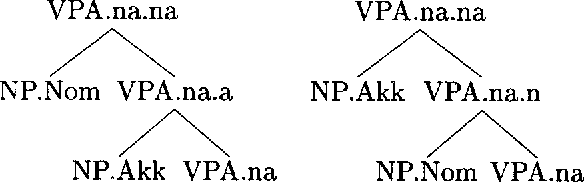
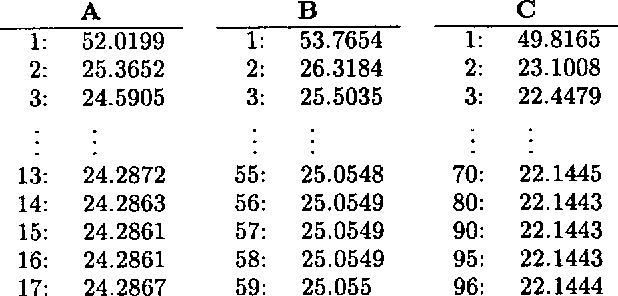

The paper describes an extensive experiment in inside-outside estimation of a lexicalized probabilistic context free grammar for German verb-final clauses. Grammar and formalism features which make the experiment feasible are described. Successive models are evaluated on precision and recall of phrase markup.
Valence Induction with a Head-Lexicalized PCFG
May 05, 1998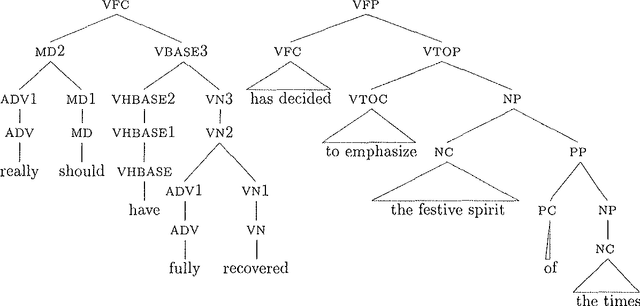
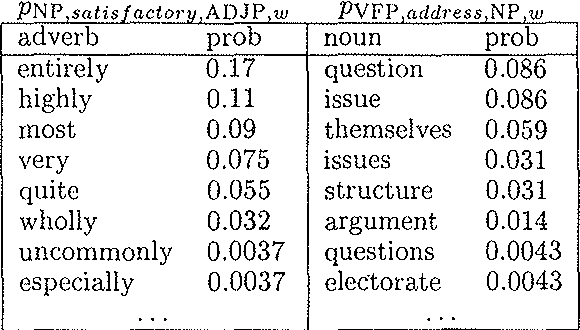


This paper presents an experiment in learning valences (subcategorization frames) from a 50 million word text corpus, based on a lexicalized probabilistic context free grammar. Distributions are estimated using a modified EM algorithm. We evaluate the acquired lexicon both by comparison with a dictionary and by entropy measures. Results show that our model produces highly accurate frame distributions.
Epistemic NP Modifiers
Aug 06, 1997The paper considers participles such as "unknown", "identified" and "unspecified", which in sentences such as "Solange is staying in an unknown hotel" have readings equivalent to an indirect question "Solange is staying in a hotel, and it is not known which hotel it is." We discuss phenomena including disambiguation of quantifier scope and a restriction on the set of determiners which allow the reading in question. Epistemic modifiers are analyzed in a DRT framework with file (information state) discourse referents. The proposed semantics uses a predication on files and discourse referents which is related to recent developments in dynamic modal predicate calculus. It is argued that a compositional DRT semantics must employ a semantic type of discourse referents, as opposed to just a type of individuals. A connection is developed between the scope effects of epistemic modifiers and the scope-disambiguating effect of "a certain".