Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValence Induction with a Head-Lexicalized PCFG
Paper and Code
May 05, 1998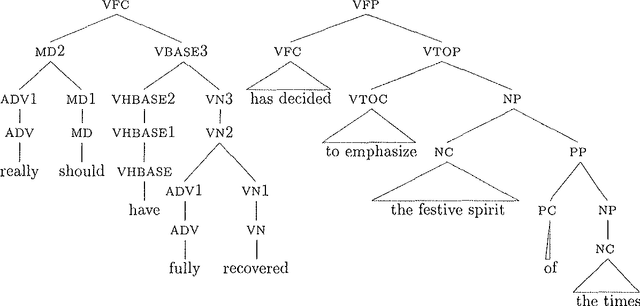
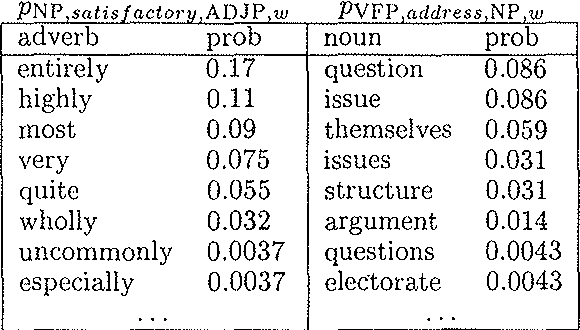


This paper presents an experiment in learning valences (subcategorization frames) from a 50 million word text corpus, based on a lexicalized probabilistic context free grammar. Distributions are estimated using a modified EM algorithm. We evaluate the acquired lexicon both by comparison with a dictionary and by entropy measures. Results show that our model produces highly accurate frame distributions.
* 10 pages, 5 postscript figures
View paper on