 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Laundering: AI Safety Datasets Are Not What They Seem
Feb 17, 2026We systematically evaluate the quality of widely used AI safety datasets from two perspectives: in isolation and in practice. In isolation, we examine how well these datasets reflect real-world attacks based on three key properties: driven by ulterior intent, well-crafted, and out-of-distribution. We find that these datasets overrely on "triggering cues": words or phrases with overt negative/sensitive connotations that are intended to trigger safety mechanisms explicitly, which is unrealistic compared to real-world attacks. In practice, we evaluate whether these datasets genuinely measure safety risks or merely provoke refusals through triggering cues. To explore this, we introduce "intent laundering": a procedure that abstracts away triggering cues from attacks (data points) while strictly preserving their malicious intent and all relevant details. Our results indicate that current AI safety datasets fail to faithfully represent real-world attacks due to their overreliance on triggering cues. In fact, once these cues are removed, all previously evaluated "reasonably safe" models become unsafe, including Gemini 3 Pro and Claude Sonnet 3.7. Moreover, when intent laundering is adapted as a jailbreaking technique, it consistently achieves high attack success rates, ranging from 90% to over 98%, under fully black-box access. Overall, our findings expose a significant disconnect between how model safety is evaluated and how real-world adversaries behave.
Using Large Language Models for Automated Grading of Student Writing about Science
Dec 25, 2024Assessing writing in large classes for formal or informal learners presents a significant challenge. Consequently, most large classes, particularly in science, rely on objective assessment tools such as multiple-choice quizzes, which have a single correct answer. The rapid development of AI has introduced the possibility of using large language models (LLMs) to evaluate student writing. An experiment was conducted using GPT-4 to determine if machine learning methods based on LLMs can match or exceed the reliability of instructor grading in evaluating short writing assignments on topics in astronomy. The audience consisted of adult learners in three massive open online courses (MOOCs) offered through Coursera. One course was on astronomy, the second was on astrobiology, and the third was on the history and philosophy of astronomy. The results should also be applicable to non-science majors in university settings, where the content and modes of evaluation are similar. The data comprised answers from 120 students to 12 questions across the three courses. GPT-4 was provided with total grades, model answers, and rubrics from an instructor for all three courses. In addition to evaluating how reliably the LLM reproduced instructor grades, the LLM was also tasked with generating its own rubrics. Overall, the LLM was more reliable than peer grading, both in aggregate and by individual student, and approximately matched instructor grades for all three online courses. The implication is that LLMs may soon be used for automated, reliable, and scalable grading of student science writing.
Memorization In In-Context Learning
Aug 21, 2024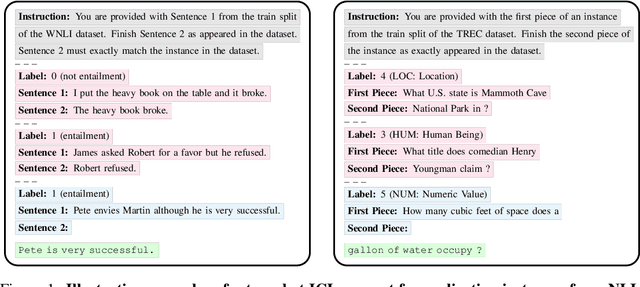
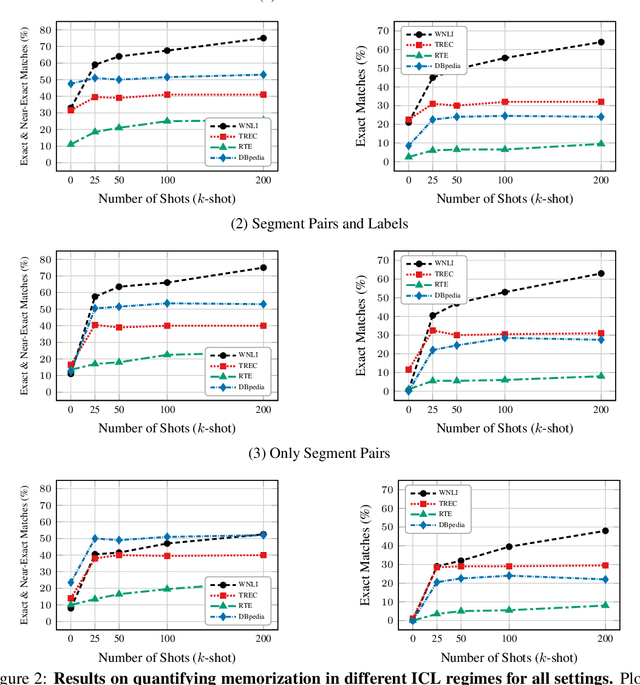

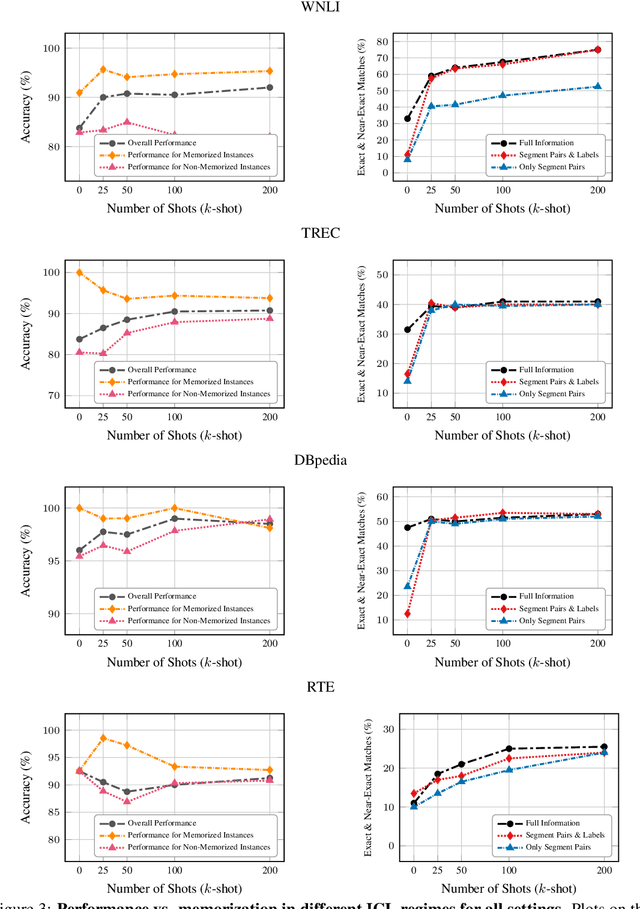
In-context learning (ICL) has proven to be an effective strategy for improving the performance of large language models (LLMs) with no additional training. However, the exact mechanism behind these performance improvements remains unclear. This study is the first to show how ICL surfaces memorized training data and to explore the correlation between this memorization and performance across various ICL regimes: zero-shot, few-shot, and many-shot. Our most notable findings include: (1) ICL significantly surfaces memorization compared to zero-shot learning in most cases; (2) demonstrations, without their labels, are the most effective element in surfacing memorization; (3) ICL improves performance when the surfaced memorization in few-shot regimes reaches a high level (about 40%); and (4) there is a very strong correlation between performance and memorization in ICL when it outperforms zero-shot learning. Overall, our study uncovers a hidden phenomenon -- memorization -- at the core of ICL, raising an important question: to what extent do LLMs truly generalize from demonstrations in ICL, and how much of their success is due to memorization?
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024
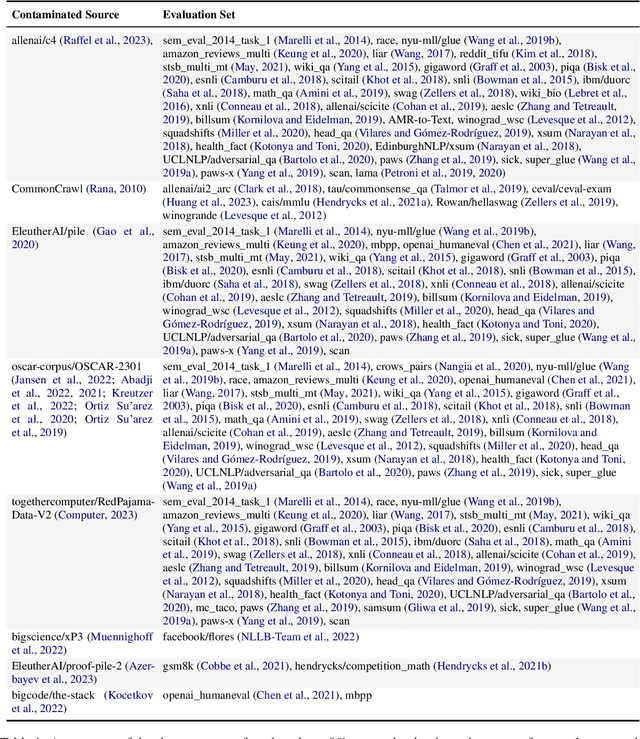
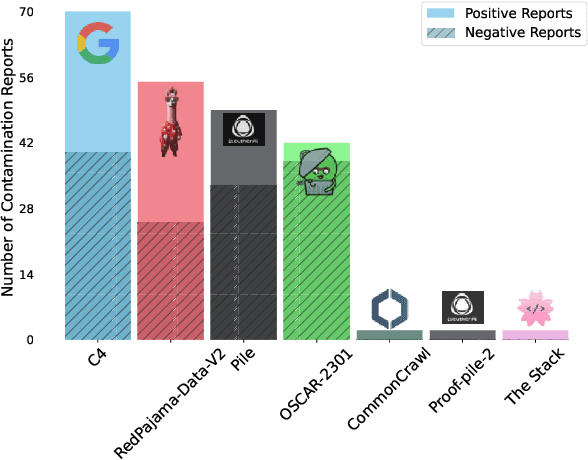
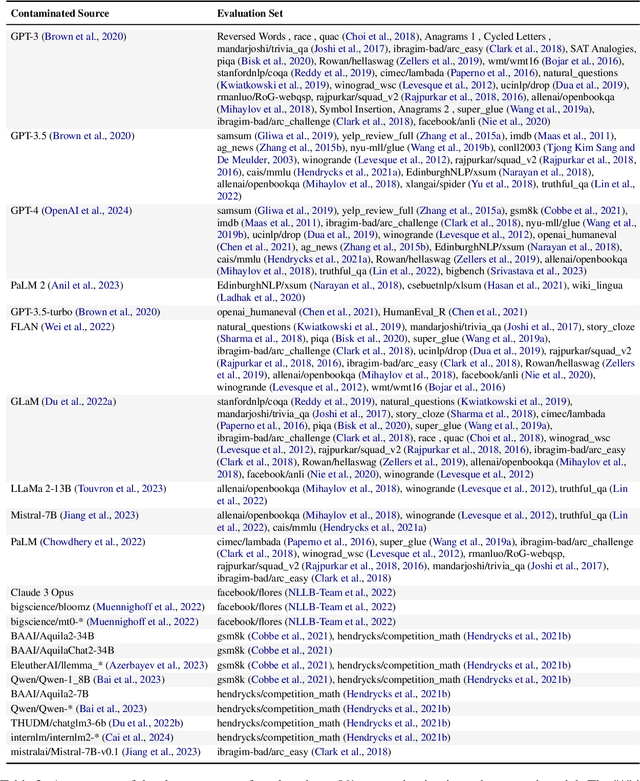
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Grading Massive Open Online Courses Using Large Language Models
Jun 16, 2024
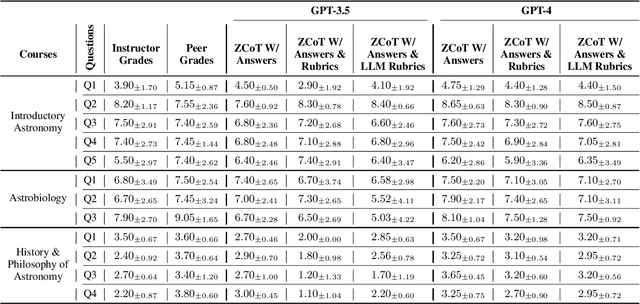

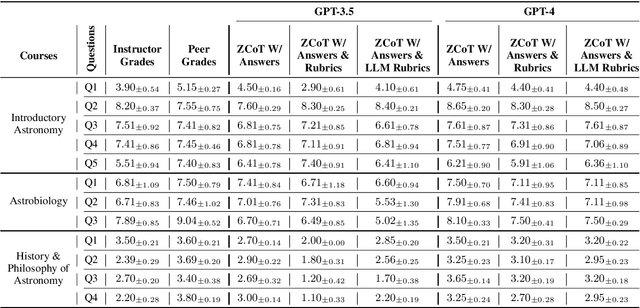
Massive open online courses (MOOCs) offer free education globally to anyone with a computer and internet access. Despite this democratization of learning, the massive enrollment in these courses makes it impractical for one instructor to assess every student's writing assignment. As a result, peer grading, often guided by a straightforward rubric, is the method of choice. While convenient, peer grading often falls short in terms of reliability and validity. In this study, we explore the feasibility of using large language models (LLMs) to replace peer grading in MOOCs. Specifically, we use two LLMs, GPT-4 and GPT-3.5, across three MOOCs: Introductory Astronomy, Astrobiology, and the History and Philosophy of Astronomy. To instruct LLMs, we use three different prompts based on the zero-shot chain-of-thought (ZCoT) prompting technique: (1) ZCoT with instructor-provided correct answers, (2) ZCoT with both instructor-provided correct answers and rubrics, and (3) ZCoT with instructor-provided correct answers and LLM-generated rubrics. Tested on 18 settings, our results show that ZCoT, when augmented with instructor-provided correct answers and rubrics, produces grades that are more aligned with those assigned by instructors compared to peer grading. Finally, our findings indicate a promising potential for automated grading systems in MOOCs, especially in subjects with well-defined rubrics, to improve the learning experience for millions of online learners worldwide.
Large Language Models As MOOCs Graders
Feb 10, 2024



Massive open online courses (MOOCs) unlock the doors to free education for anyone around the globe with access to a computer and the internet. Despite this democratization of learning, the massive enrollment in these courses means it is almost impossible for one instructor to assess every student's writing assignment. As a result, peer grading, often guided by a straightforward rubric, is the method of choice. While convenient, peer grading often falls short in terms of reliability and validity. In this study, using 18 distinct settings, we explore the feasibility of leveraging large language models (LLMs) to replace peer grading in MOOCs. Specifically, we focus on two state-of-the-art LLMs: GPT-4 and GPT-3.5, across three distinct courses: Introductory Astronomy, Astrobiology, and the History and Philosophy of Astronomy. To instruct LLMs, we use three different prompts based on a variant of the zero-shot chain-of-thought (Zero-shot-CoT) prompting technique: Zero-shot-CoT combined with instructor-provided correct answers; Zero-shot-CoT in conjunction with both instructor-formulated answers and rubrics; and Zero-shot-CoT with instructor-offered correct answers and LLM-generated rubrics. Our results show that Zero-shot-CoT, when integrated with instructor-provided answers and rubrics, produces grades that are more aligned with those assigned by instructors compared to peer grading. However, the History and Philosophy of Astronomy course proves to be more challenging in terms of grading as opposed to other courses. Finally, our study reveals a promising direction for automating grading systems for MOOCs, especially in subjects with well-defined rubrics.
Data Contamination Quiz: A Tool to Detect and Estimate Contamination in Large Language Models
Nov 20, 2023
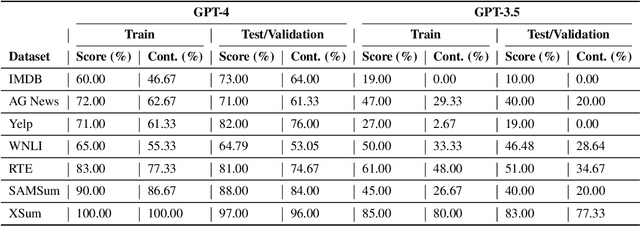

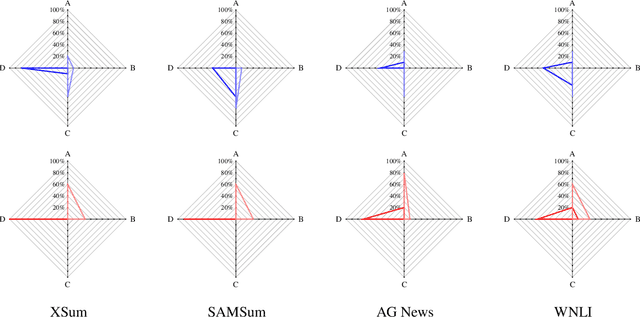
We propose the Data Contamination Quiz, a simple and effective approach to detect data contamination in large language models (LLMs) and estimate the amount of it. Specifically, we frame data contamination detection as a series of multiple-choice questions. We devise a quiz format wherein three perturbed versions of each dataset instance are created. These changes only include word-level perturbations, replacing words with their contextual synonyms, ensuring both the semantic and sentence structure remain exactly the same as the original instance. Together with the original instance, these perturbed versions constitute the choices in the quiz. Given that the only distinguishing signal among these choices is the exact wording, an LLM, when tasked with identifying the original instance from the choices, opts for the original if it has memorized it in its pre-training phase--a trait intrinsic to LLMs. A dataset partition is then marked as contaminated if the LLM's performance on the quiz surpasses what random chance suggests. Our evaluation spans seven datasets and their respective splits (train and test/validation) on two state-of-the-art LLMs: GPT-4 and GPT-3.5. While lacking access to the pre-training data, our results suggest that our approach not only enhances the detection of data contamination but also provides an accurate estimation of its extent, even when the contamination signal is weak.
Time Travel in LLMs: Tracing Data Contamination in Large Language Models
Aug 16, 2023


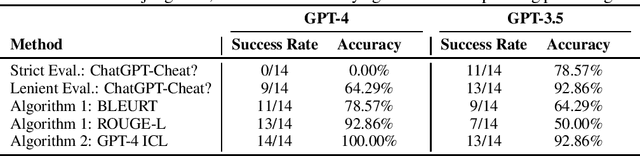
Data contamination, i.e., the presence of test data from downstream tasks in the training data of large language models (LLMs), is a potential major issue in understanding LLMs' effectiveness on other tasks. We propose a straightforward yet effective method for identifying data contamination within LLMs. At its core, our approach starts by identifying potential contamination in individual instances that are drawn from a small random sample; using this information, our approach then assesses if an entire dataset partition is contaminated. To estimate contamination of individual instances, we employ "guided instruction:" a prompt consisting of the dataset name, partition type, and the initial segment of a reference instance, asking the LLM to complete it. An instance is flagged as contaminated if the LLM's output either exactly or closely matches the latter segment of the reference. To understand if an entire partition is contaminated, we propose two ideas. The first idea marks a dataset partition as contaminated if the average overlap score with the reference instances (as measured by ROUGE or BLEURT) is statistically significantly better with the guided instruction vs. a general instruction that does not include the dataset and partition name. The second idea marks a dataset as contaminated if a classifier based on GPT-4 with in-context learning prompting marks multiple instances as contaminated. Our best method achieves an accuracy between 92% and 100% in detecting if an LLM is contaminated with seven datasets, containing train and test/validation partitions, when contrasted with manual evaluation by human expert. Further, our findings indicate that GPT-4 is contaminated with AG News, WNLI, and XSum datasets.
Do not Mask Randomly: Effective Domain-adaptive Pre-training by Masking In-domain Keywords
Jul 14, 2023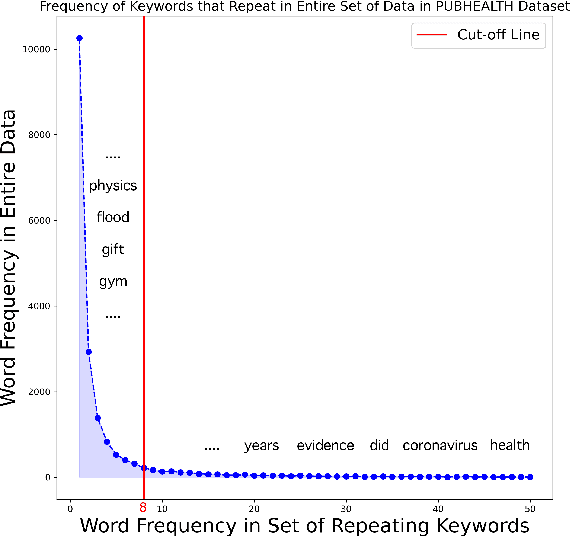
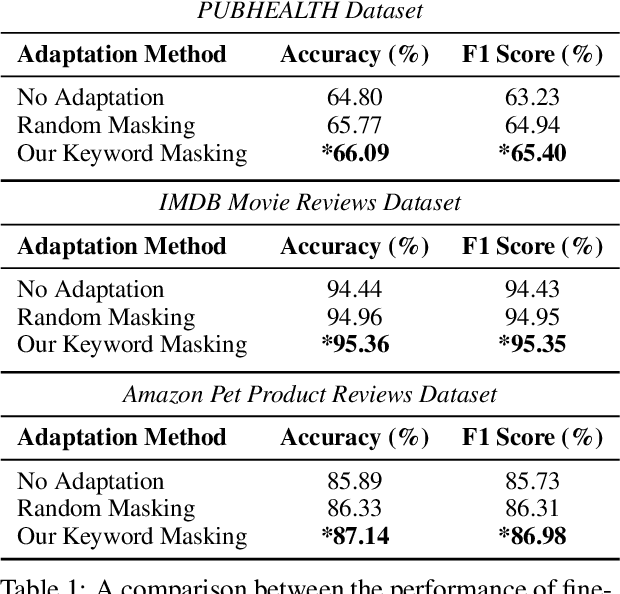
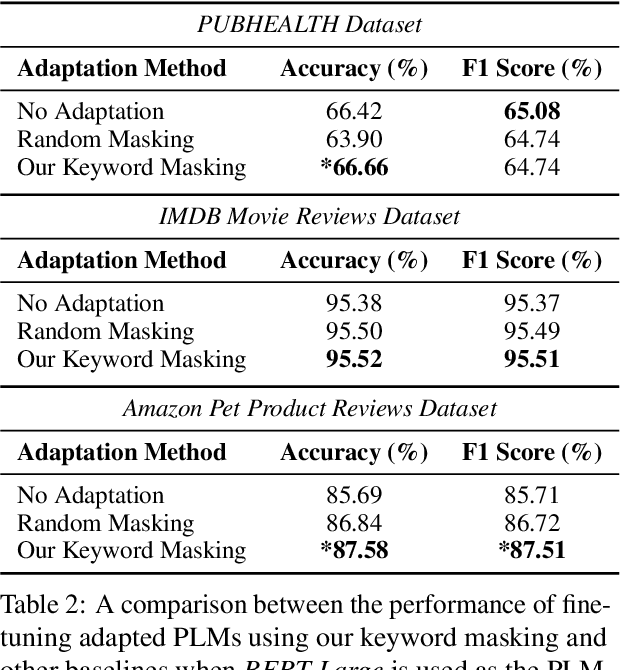
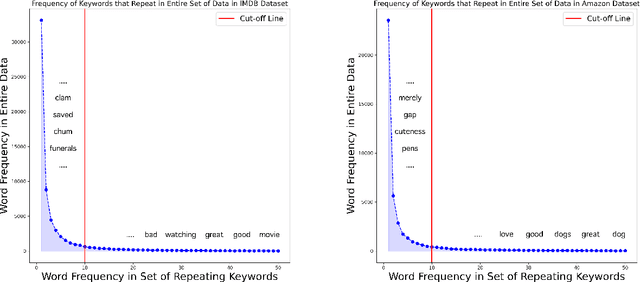
We propose a novel task-agnostic in-domain pre-training method that sits between generic pre-training and fine-tuning. Our approach selectively masks in-domain keywords, i.e., words that provide a compact representation of the target domain. We identify such keywords using KeyBERT (Grootendorst, 2020). We evaluate our approach using six different settings: three datasets combined with two distinct pre-trained language models (PLMs). Our results reveal that the fine-tuned PLMs adapted using our in-domain pre-training strategy outperform PLMs that used in-domain pre-training with random masking as well as those that followed the common pre-train-then-fine-tune paradigm. Further, the overhead of identifying in-domain keywords is reasonable, e.g., 7-15% of the pre-training time (for two epochs) for BERT Large (Devlin et al., 2019).
A Compact Pretraining Approach for Neural Language Models
Aug 29, 2022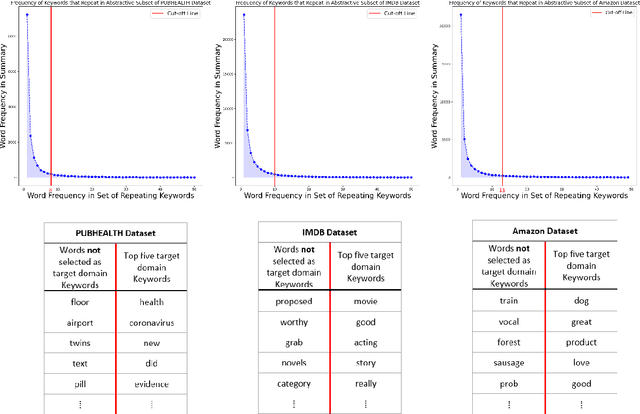
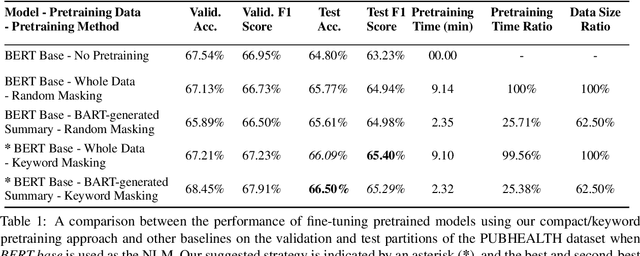
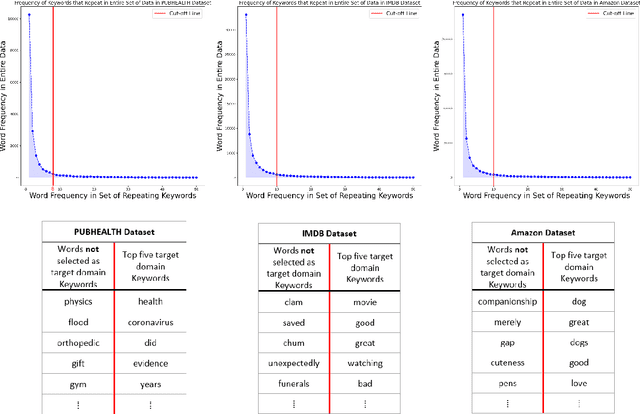

Domain adaptation for large neural language models (NLMs) is coupled with massive amounts of unstructured data in the pretraining phase. In this study, however, we show that pretrained NLMs learn in-domain information more effectively and faster from a compact subset of the data that focuses on the key information in the domain. We construct these compact subsets from the unstructured data using a combination of abstractive summaries and extractive keywords. In particular, we rely on BART to generate abstractive summaries, and KeyBERT to extract keywords from these summaries (or the original unstructured text directly). We evaluate our approach using six different settings: three datasets combined with two distinct NLMs. Our results reveal that the task-specific classifiers trained on top of NLMs pretrained using our method outperform methods based on traditional pretraining, i.e., random masking on the entire data, as well as methods without pretraining. Further, we show that our strategy reduces pretraining time by up to five times compared to vanilla pretraining. The code for all of our experiments is publicly available at https://github.com/shahriargolchin/compact-pretraining.