 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic Parsing Framework for End-to-End Time Normalization
Jul 08, 2025Time normalization is the task of converting natural language temporal expressions into machine-readable representations. It underpins many downstream applications in information retrieval, question answering, and clinical decision-making. Traditional systems based on the ISO-TimeML schema limit expressivity and struggle with complex constructs such as compositional, event-relative, and multi-span time expressions. In this work, we introduce a novel formulation of time normalization as a code generation task grounded in the SCATE framework, which defines temporal semantics through symbolic and compositional operators. We implement a fully executable SCATE Python library and demonstrate that large language models (LLMs) can generate executable SCATE code. Leveraging this capability, we develop an automatic data augmentation pipeline using LLMs to synthesize large-scale annotated data with code-level validation. Our experiments show that small, locally deployable models trained on this augmented data can achieve strong performance, outperforming even their LLM parents and enabling practical, accurate, and interpretable time normalization.
Transformer-Based Temporal Information Extraction and Application: A Review
Apr 10, 2025

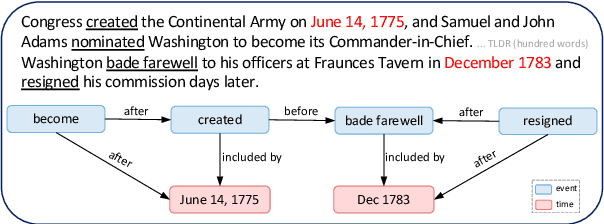

Temporal information extraction (IE) aims to extract structured temporal information from unstructured text, thereby uncovering the implicit timelines within. This technique is applied across domains such as healthcare, newswire, and intelligence analysis, aiding models in these areas to perform temporal reasoning and enabling human users to grasp the temporal structure of text. Transformer-based pre-trained language models have produced revolutionary advancements in natural language processing, demonstrating exceptional performance across a multitude of tasks. Despite the achievements garnered by Transformer-based approaches in temporal IE, there is a lack of comprehensive reviews on these endeavors. In this paper, we aim to bridge this gap by systematically summarizing and analyzing the body of work on temporal IE using Transformers while highlighting potential future research directions.
Identifying Task Groupings for Multi-Task Learning Using Pointwise V-Usable Information
Oct 16, 2024The success of multi-task learning can depend heavily on which tasks are grouped together. Naively grouping all tasks or a random set of tasks can result in negative transfer, with the multi-task models performing worse than single-task models. Though many efforts have been made to identify task groupings and to measure the relatedness among different tasks, it remains a challenging research topic to define a metric to identify the best task grouping out of a pool of many potential task combinations. We propose a metric of task relatedness based on task difficulty measured by pointwise V-usable information (PVI). PVI is a recently proposed metric to estimate how much usable information a dataset contains given a model. We hypothesize that tasks with not statistically different PVI estimates are similar enough to benefit from the joint learning process. We conduct comprehensive experiments to evaluate the feasibility of this metric for task grouping on 15 NLP datasets in the general, biomedical, and clinical domains. We compare the results of the joint learners against single learners, existing baseline methods, and recent large language models, including Llama 2 and GPT-4. The results show that by grouping tasks with similar PVI estimates, the joint learners yielded competitive results with fewer total parameters, with consistent performance across domains.
Memorization In In-Context Learning
Aug 21, 2024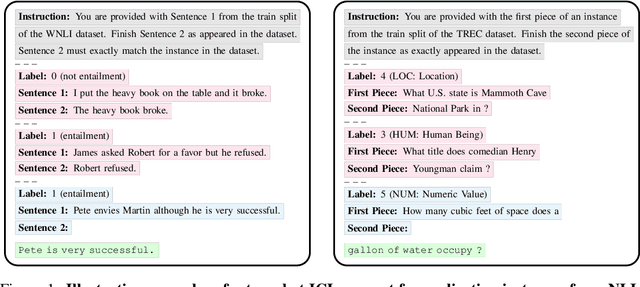
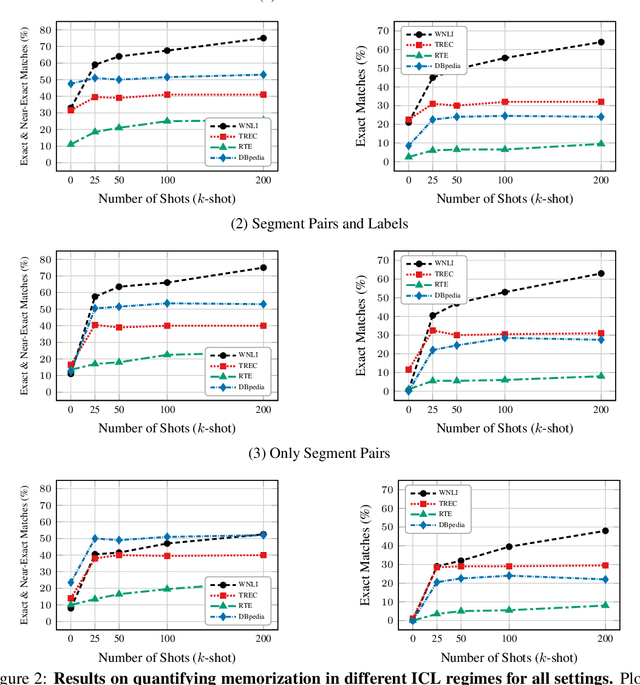

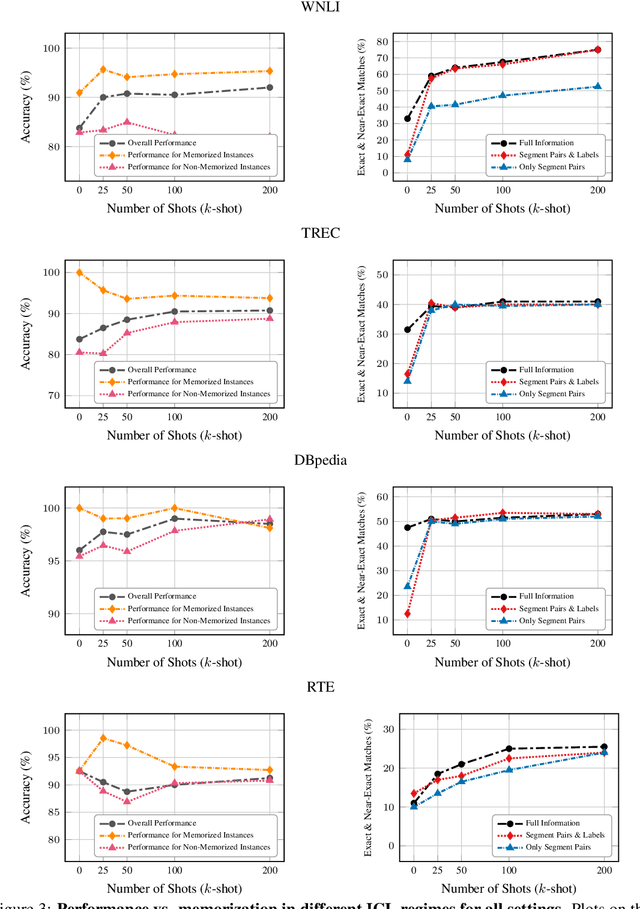
In-context learning (ICL) has proven to be an effective strategy for improving the performance of large language models (LLMs) with no additional training. However, the exact mechanism behind these performance improvements remains unclear. This study is the first to show how ICL surfaces memorized training data and to explore the correlation between this memorization and performance across various ICL regimes: zero-shot, few-shot, and many-shot. Our most notable findings include: (1) ICL significantly surfaces memorization compared to zero-shot learning in most cases; (2) demonstrations, without their labels, are the most effective element in surfacing memorization; (3) ICL improves performance when the surfaced memorization in few-shot regimes reaches a high level (about 40%); and (4) there is a very strong correlation between performance and memorization in ICL when it outperforms zero-shot learning. Overall, our study uncovers a hidden phenomenon -- memorization -- at the core of ICL, raising an important question: to what extent do LLMs truly generalize from demonstrations in ICL, and how much of their success is due to memorization?
Semi-Structured Chain-of-Thought: Integrating Multiple Sources of Knowledge for Improved Language Model Reasoning
Nov 14, 2023



An important open question pertaining to the use of large language models for knowledge-intensive tasks is how to effectively integrate knowledge from three sources: the model's parametric memory, external structured knowledge, and external unstructured knowledge. Most existing prompting methods either rely solely on one or two of these sources, or require repeatedly invoking large language models to generate similar or identical content. In this work, we overcome these limitations by introducing a novel semi-structured prompting approach that seamlessly integrates the model's parametric memory with unstructured knowledge from text documents and structured knowledge from knowledge graphs. Experimental results on open-domain multi-hop question answering datasets demonstrate that our prompting method significantly surpasses existing techniques, even exceeding those which require fine-tuning.
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
Improving Toponym Resolution with Better Candidate Generation, Transformer-based Reranking, and Two-Stage Resolution
May 18, 2023



Geocoding is the task of converting location mentions in text into structured data that encodes the geospatial semantics. We propose a new architecture for geocoding, GeoNorm. GeoNorm first uses information retrieval techniques to generate a list of candidate entries from the geospatial ontology. Then it reranks the candidate entries using a transformer-based neural network that incorporates information from the ontology such as the entry's population. This generate-and-rerank process is applied twice: first to resolve the less ambiguous countries, states, and counties, and second to resolve the remaining location mentions, using the identified countries, states, and counties as context. Our proposed toponym resolution framework achieves state-of-the-art performance on multiple datasets. Code and models are available at \url{https://github.com/clulab/geonorm}.
Explainable Verbal Reasoner Plus (EVR+): A Natural Language Reasoning Framework that Supports Diverse Compositional Reasoning
Apr 28, 2023



Languages models have been successfully applied to a variety of reasoning tasks in NLP, yet the language models still suffer from compositional generalization. In this paper we present Explainable Verbal Reasoner Plus (EVR+), a reasoning framework that enhances language models' compositional reasoning ability by (1) allowing the model to explicitly generate and execute symbolic operators, and (2) allowing the model to decompose a complex task into several simpler ones in a flexible manner. Compared with its predecessor Explainable Verbal Reasoner (EVR) and other previous approaches adopting similar ideas, our framework supports more diverse types of reasoning such as nested loops and different types of recursion. To evaluate our reasoning framework, we build a synthetic dataset with five tasks that require compositional reasoning. Results show that our reasoning framework can enhance the language model's compositional generalization performance on the five tasks, using a fine-tuned language model. We also discussed the possibility and the challenges to combine our reasoning framework with a few-shot prompted language model.
We need to talk about random seeds
Oct 24, 2022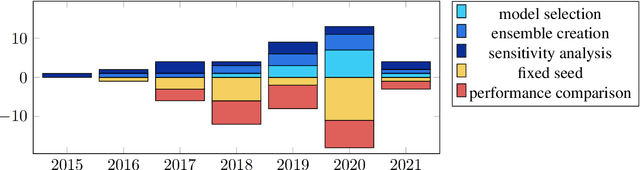

Modern neural network libraries all take as a hyperparameter a random seed, typically used to determine the initial state of the model parameters. This opinion piece argues that there are some safe uses for random seeds: as part of the hyperparameter search to select a good model, creating an ensemble of several models, or measuring the sensitivity of the training algorithm to the random seed hyperparameter. It argues that some uses for random seeds are risky: using a fixed random seed for "replicability" and varying only the random seed to create score distributions for performance comparison. An analysis of 85 recent publications from the ACL Anthology finds that more than 50% contain risky uses of random seeds.
Better Retrieval May Not Lead to Better Question Answering
May 07, 2022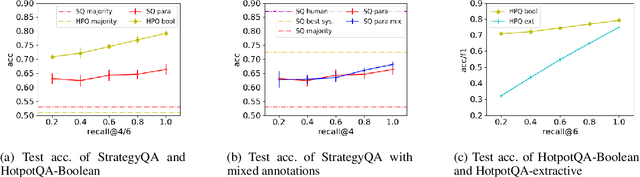



Considerable progress has been made recently in open-domain question answering (QA) problems, which require Information Retrieval (IR) and Reading Comprehension (RC). A popular approach to improve the system's performance is to improve the quality of the retrieved context from the IR stage. In this work we show that for StrategyQA, a challenging open-domain QA dataset that requires multi-hop reasoning, this common approach is surprisingly ineffective -- improving the quality of the retrieved context hardly improves the system's performance. We further analyze the system's behavior to identify potential reasons.